Enqing Chen, Xueting Wang, Xin Guo, Ying Zhu, Dong Li
{"title":"基于人体骨骼动作识别的隐空间改进掩码重建模型。","authors":"Enqing Chen, Xueting Wang, Xin Guo, Ying Zhu, Dong Li","doi":"10.3389/fnbot.2025.1482281","DOIUrl":null,"url":null,"abstract":"<p><p>Human skeleton-based action recognition is an important task in the field of computer vision. In recent years, masked autoencoder (MAE) has been used in various fields due to its powerful self-supervised learning ability and has achieved good results in masked data reconstruction tasks. However, in visual classification tasks such as action recognition, the limited ability of the encoder to learn features in the autoencoder structure results in poor classification performance. We propose to enhance the encoder's feature extraction ability in classification tasks by leveraging the latent space of variational autoencoder (VAE) and further replace it with the latent space of vector quantized variational autoencoder (VQVAE). The constructed models are called SkeletonMVAE and SkeletonMVQVAE, respectively. In SkeletonMVAE, we constrain the latent variables to represent features in the form of distributions. In SkeletonMVQVAE, we discretize the latent variables. These help the encoder learn deeper data structures and more discriminative and generalized feature representations. The experiment results on the NTU-60 and NTU-120 datasets demonstrate that our proposed method can effectively improve the classification accuracy of the encoder in classification tasks and its generalization ability in the case of few labeled data. SkeletonMVAE exhibits stronger classification ability, while SkeletonMVQVAE exhibits stronger generalization in situations with fewer labeled data.</p>","PeriodicalId":12628,"journal":{"name":"Frontiers in Neurorobotics","volume":"19 ","pages":"1482281"},"PeriodicalIF":2.8000,"publicationDate":"2025-02-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11947723/pdf/","citationCount":"0","resultStr":"{\"title\":\"Latent space improved masked reconstruction model for human skeleton-based action recognition.\",\"authors\":\"Enqing Chen, Xueting Wang, Xin Guo, Ying Zhu, Dong Li\",\"doi\":\"10.3389/fnbot.2025.1482281\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Human skeleton-based action recognition is an important task in the field of computer vision. In recent years, masked autoencoder (MAE) has been used in various fields due to its powerful self-supervised learning ability and has achieved good results in masked data reconstruction tasks. However, in visual classification tasks such as action recognition, the limited ability of the encoder to learn features in the autoencoder structure results in poor classification performance. We propose to enhance the encoder's feature extraction ability in classification tasks by leveraging the latent space of variational autoencoder (VAE) and further replace it with the latent space of vector quantized variational autoencoder (VQVAE). The constructed models are called SkeletonMVAE and SkeletonMVQVAE, respectively. In SkeletonMVAE, we constrain the latent variables to represent features in the form of distributions. In SkeletonMVQVAE, we discretize the latent variables. These help the encoder learn deeper data structures and more discriminative and generalized feature representations. The experiment results on the NTU-60 and NTU-120 datasets demonstrate that our proposed method can effectively improve the classification accuracy of the encoder in classification tasks and its generalization ability in the case of few labeled data. SkeletonMVAE exhibits stronger classification ability, while SkeletonMVQVAE exhibits stronger generalization in situations with fewer labeled data.</p>\",\"PeriodicalId\":12628,\"journal\":{\"name\":\"Frontiers in Neurorobotics\",\"volume\":\"19 \",\"pages\":\"1482281\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-02-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11947723/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Neurorobotics\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.3389/fnbot.2025.1482281\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Neurorobotics","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.3389/fnbot.2025.1482281","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Latent space improved masked reconstruction model for human skeleton-based action recognition.
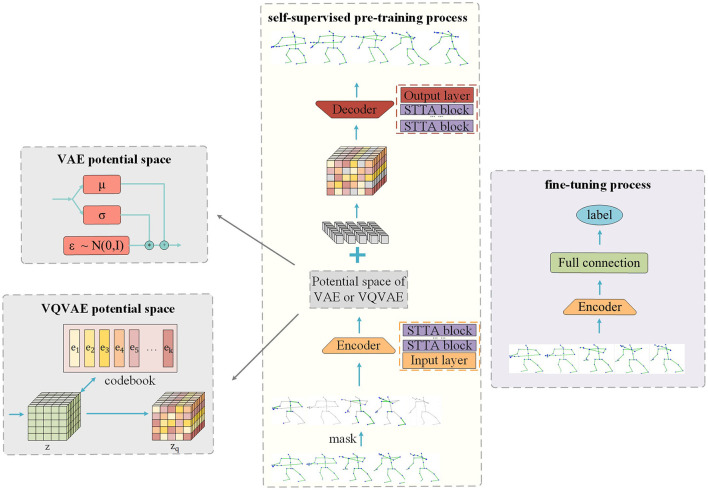
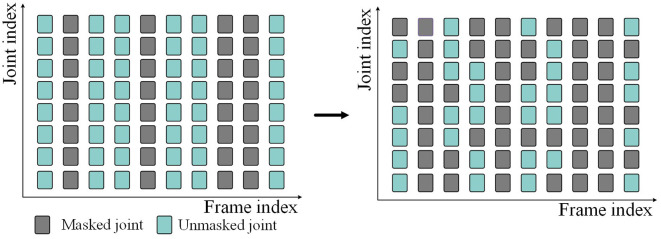
Human skeleton-based action recognition is an important task in the field of computer vision. In recent years, masked autoencoder (MAE) has been used in various fields due to its powerful self-supervised learning ability and has achieved good results in masked data reconstruction tasks. However, in visual classification tasks such as action recognition, the limited ability of the encoder to learn features in the autoencoder structure results in poor classification performance. We propose to enhance the encoder's feature extraction ability in classification tasks by leveraging the latent space of variational autoencoder (VAE) and further replace it with the latent space of vector quantized variational autoencoder (VQVAE). The constructed models are called SkeletonMVAE and SkeletonMVQVAE, respectively. In SkeletonMVAE, we constrain the latent variables to represent features in the form of distributions. In SkeletonMVQVAE, we discretize the latent variables. These help the encoder learn deeper data structures and more discriminative and generalized feature representations. The experiment results on the NTU-60 and NTU-120 datasets demonstrate that our proposed method can effectively improve the classification accuracy of the encoder in classification tasks and its generalization ability in the case of few labeled data. SkeletonMVAE exhibits stronger classification ability, while SkeletonMVQVAE exhibits stronger generalization in situations with fewer labeled data.
期刊介绍:
Frontiers in Neurorobotics publishes rigorously peer-reviewed research in the science and technology of embodied autonomous neural systems. Specialty Chief Editors Alois C. Knoll and Florian Röhrbein at the Technische Universität München are supported by an outstanding Editorial Board of international experts. This multidisciplinary open-access journal is at the forefront of disseminating and communicating scientific knowledge and impactful discoveries to researchers, academics and the public worldwide.
Neural systems include brain-inspired algorithms (e.g. connectionist networks), computational models of biological neural networks (e.g. artificial spiking neural nets, large-scale simulations of neural microcircuits) and actual biological systems (e.g. in vivo and in vitro neural nets). The focus of the journal is the embodiment of such neural systems in artificial software and hardware devices, machines, robots or any other form of physical actuation. This also includes prosthetic devices, brain machine interfaces, wearable systems, micro-machines, furniture, home appliances, as well as systems for managing micro and macro infrastructures. Frontiers in Neurorobotics also aims to publish radically new tools and methods to study plasticity and development of autonomous self-learning systems that are capable of acquiring knowledge in an open-ended manner. Models complemented with experimental studies revealing self-organizing principles of embodied neural systems are welcome. Our journal also publishes on the micro and macro engineering and mechatronics of robotic devices driven by neural systems, as well as studies on the impact that such systems will have on our daily life.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


