Alper Idrisoglu, Ana Luiza Dallora Moraes, Abbas Cheddad, Peter Anderberg, Andreas Jakobsson, Johan Sanmartin Berglund
{"title":"元音分割对慢性阻塞性肺疾病机器学习分类的影响。","authors":"Alper Idrisoglu, Ana Luiza Dallora Moraes, Abbas Cheddad, Peter Anderberg, Andreas Jakobsson, Johan Sanmartin Berglund","doi":"10.1038/s41598-025-95320-3","DOIUrl":null,"url":null,"abstract":"<p><p>Vowel-based voice analysis is gaining attention as a potential non-invasive tool for COPD classification, offering insights into phonatory function. The growing need for voice data has necessitated the adoption of various techniques, including segmentation, to augment existing datasets for training comprehensive Machine Learning (ML) modelsThis study aims to investigate the possible effects of segmentation of the utterance of vowel \"a\" on the performance of ML classifiers CatBoost (CB), Random Forest (RF), and Support Vector Machine (SVM). This research involves training individual ML models using three distinct dataset constructions: full-sequence, segment-wise, and group-wise, derived from the utterance of the vowel \"a\" which consists of 1058 recordings belonging to 48 participants. This approach comprehensively analyzes how each data categorization impacts the model's performance and results. A nested cross-validation (nCV) approach was implemented with grid search for hyperparameter optimization. This rigorous methodology was employed to minimize overfitting risks and maximize model performance. Compared to the full-sequence dataset, the findings indicate that the second segment yielded higher results within the four-segment category. Specifically, the CB model achieved superior accuracy, attaining 97.8% and 84.6% on the validation and test sets, respectively. The same category for the CB model also demonstrated the best balance regarding true positive rate (TPR) and true negative rate (TNR), making it the most clinically effective choice. These findings suggest that time-sensitive properties in vowel production are important for COPD classification and that segmentation can aid in capturing these properties. Despite these promising results, the dataset size and demographic homogeneity limit generalizability, highlighting areas for future research.Trial registration The study is registered on clinicaltrials.gov with ID: NCT06160674.</p>","PeriodicalId":21811,"journal":{"name":"Scientific Reports","volume":"15 1","pages":"9930"},"PeriodicalIF":3.9000,"publicationDate":"2025-03-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11929820/pdf/","citationCount":"0","resultStr":"{\"title\":\"Vowel segmentation impact on machine learning classification for chronic obstructive pulmonary disease.\",\"authors\":\"Alper Idrisoglu, Ana Luiza Dallora Moraes, Abbas Cheddad, Peter Anderberg, Andreas Jakobsson, Johan Sanmartin Berglund\",\"doi\":\"10.1038/s41598-025-95320-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Vowel-based voice analysis is gaining attention as a potential non-invasive tool for COPD classification, offering insights into phonatory function. The growing need for voice data has necessitated the adoption of various techniques, including segmentation, to augment existing datasets for training comprehensive Machine Learning (ML) modelsThis study aims to investigate the possible effects of segmentation of the utterance of vowel \\\"a\\\" on the performance of ML classifiers CatBoost (CB), Random Forest (RF), and Support Vector Machine (SVM). This research involves training individual ML models using three distinct dataset constructions: full-sequence, segment-wise, and group-wise, derived from the utterance of the vowel \\\"a\\\" which consists of 1058 recordings belonging to 48 participants. This approach comprehensively analyzes how each data categorization impacts the model's performance and results. A nested cross-validation (nCV) approach was implemented with grid search for hyperparameter optimization. This rigorous methodology was employed to minimize overfitting risks and maximize model performance. Compared to the full-sequence dataset, the findings indicate that the second segment yielded higher results within the four-segment category. Specifically, the CB model achieved superior accuracy, attaining 97.8% and 84.6% on the validation and test sets, respectively. The same category for the CB model also demonstrated the best balance regarding true positive rate (TPR) and true negative rate (TNR), making it the most clinically effective choice. These findings suggest that time-sensitive properties in vowel production are important for COPD classification and that segmentation can aid in capturing these properties. Despite these promising results, the dataset size and demographic homogeneity limit generalizability, highlighting areas for future research.Trial registration The study is registered on clinicaltrials.gov with ID: NCT06160674.</p>\",\"PeriodicalId\":21811,\"journal\":{\"name\":\"Scientific Reports\",\"volume\":\"15 1\",\"pages\":\"9930\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-03-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11929820/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Reports\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41598-025-95320-3\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Reports","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41598-025-95320-3","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Vowel segmentation impact on machine learning classification for chronic obstructive pulmonary disease.
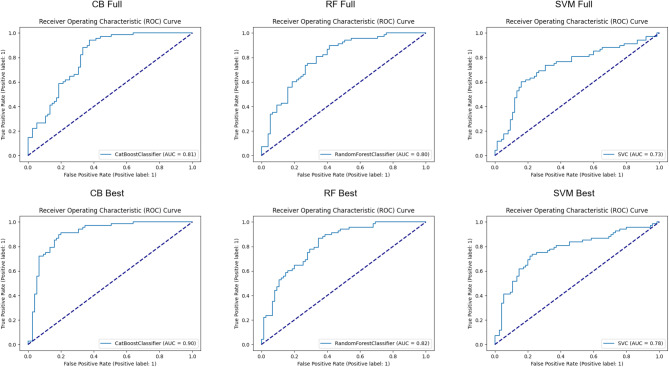
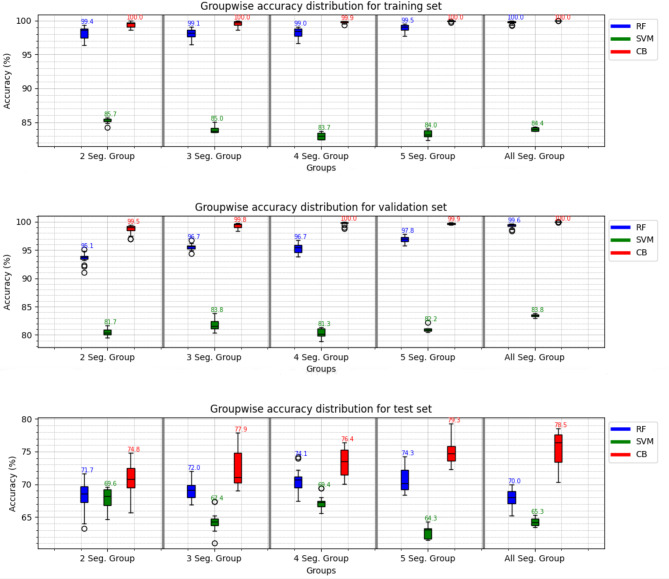
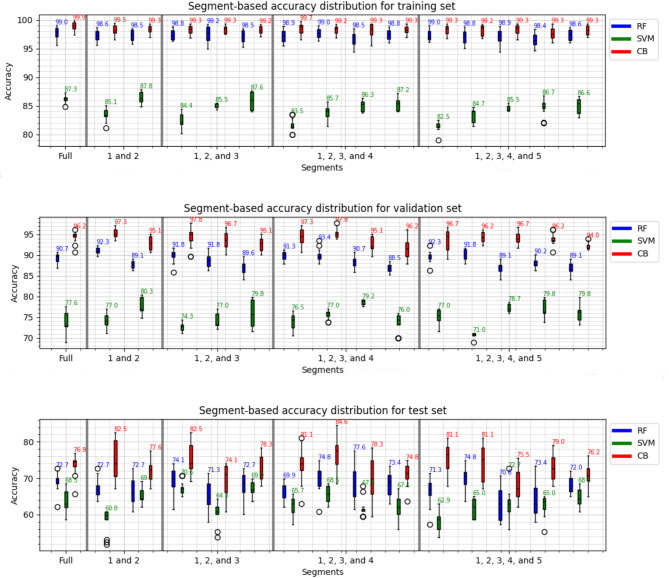
Vowel-based voice analysis is gaining attention as a potential non-invasive tool for COPD classification, offering insights into phonatory function. The growing need for voice data has necessitated the adoption of various techniques, including segmentation, to augment existing datasets for training comprehensive Machine Learning (ML) modelsThis study aims to investigate the possible effects of segmentation of the utterance of vowel "a" on the performance of ML classifiers CatBoost (CB), Random Forest (RF), and Support Vector Machine (SVM). This research involves training individual ML models using three distinct dataset constructions: full-sequence, segment-wise, and group-wise, derived from the utterance of the vowel "a" which consists of 1058 recordings belonging to 48 participants. This approach comprehensively analyzes how each data categorization impacts the model's performance and results. A nested cross-validation (nCV) approach was implemented with grid search for hyperparameter optimization. This rigorous methodology was employed to minimize overfitting risks and maximize model performance. Compared to the full-sequence dataset, the findings indicate that the second segment yielded higher results within the four-segment category. Specifically, the CB model achieved superior accuracy, attaining 97.8% and 84.6% on the validation and test sets, respectively. The same category for the CB model also demonstrated the best balance regarding true positive rate (TPR) and true negative rate (TNR), making it the most clinically effective choice. These findings suggest that time-sensitive properties in vowel production are important for COPD classification and that segmentation can aid in capturing these properties. Despite these promising results, the dataset size and demographic homogeneity limit generalizability, highlighting areas for future research.Trial registration The study is registered on clinicaltrials.gov with ID: NCT06160674.
期刊介绍:
We publish original research from all areas of the natural sciences, psychology, medicine and engineering. You can learn more about what we publish by browsing our specific scientific subject areas below or explore Scientific Reports by browsing all articles and collections.
Scientific Reports has a 2-year impact factor: 4.380 (2021), and is the 6th most-cited journal in the world, with more than 540,000 citations in 2020 (Clarivate Analytics, 2021).
•Engineering
Engineering covers all aspects of engineering, technology, and applied science. It plays a crucial role in the development of technologies to address some of the world''s biggest challenges, helping to save lives and improve the way we live.
•Physical sciences
Physical sciences are those academic disciplines that aim to uncover the underlying laws of nature — often written in the language of mathematics. It is a collective term for areas of study including astronomy, chemistry, materials science and physics.
•Earth and environmental sciences
Earth and environmental sciences cover all aspects of Earth and planetary science and broadly encompass solid Earth processes, surface and atmospheric dynamics, Earth system history, climate and climate change, marine and freshwater systems, and ecology. It also considers the interactions between humans and these systems.
•Biological sciences
Biological sciences encompass all the divisions of natural sciences examining various aspects of vital processes. The concept includes anatomy, physiology, cell biology, biochemistry and biophysics, and covers all organisms from microorganisms, animals to plants.
•Health sciences
The health sciences study health, disease and healthcare. This field of study aims to develop knowledge, interventions and technology for use in healthcare to improve the treatment of patients.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


