Marco Montagna, Filippo Chiabrando, Rebecca De Lorenzo, Patrizia Rovere Querini
{"title":"临床决策支持系统对医学生案件解决能力的影响:焦点小组比较研究","authors":"Marco Montagna, Filippo Chiabrando, Rebecca De Lorenzo, Patrizia Rovere Querini","doi":"10.2196/55709","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Health care practitioners use clinical decision support systems (CDSS) as an aid in the crucial task of clinical reasoning and decision-making. Traditional CDSS are online repositories (ORs) and clinical practice guidelines (CPG). Recently, large language models (LLMs) such as ChatGPT have emerged as potential alternatives. They have proven to be powerful, innovative tools, yet they are not devoid of worrisome risks.</p><p><strong>Objective: </strong>This study aims to explore how medical students perform in an evaluated clinical case through the use of different CDSS tools.</p><p><strong>Methods: </strong>The authors randomly divided medical students into 3 groups, CPG, n=6 (38%); OR, n=5 (31%); and ChatGPT, n=5 (31%); and assigned each group a different type of CDSS for guidance in answering prespecified questions, assessing how students' speed and ability at resolving the same clinical case varied accordingly. External reviewers evaluated all answers based on accuracy and completeness metrics (score: 1-5). The authors analyzed and categorized group scores according to the skill investigated: differential diagnosis, diagnostic workup, and clinical decision-making.</p><p><strong>Results: </strong>Answering time showed a trend for the ChatGPT group to be the fastest. The mean scores for completeness were as follows: CPG 4.0, OR 3.7, and ChatGPT 3.8 (P=.49). The mean scores for accuracy were as follows: CPG 4.0, OR 3.3, and ChatGPT 3.7 (P=.02). Aggregating scores according to the 3 students' skill domains, trends in differences among the groups emerge more clearly, with the CPG group that performed best in nearly all domains and maintained almost perfect alignment between its completeness and accuracy.</p><p><strong>Conclusions: </strong>This hands-on session provided valuable insights into the potential perks and associated pitfalls of LLMs in medical education and practice. It suggested the critical need to include teachings in medical degree courses on how to properly take advantage of LLMs, as the potential for misuse is evident and real.</p>","PeriodicalId":36236,"journal":{"name":"JMIR Medical Education","volume":"11 ","pages":"e55709"},"PeriodicalIF":3.2000,"publicationDate":"2025-03-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11936302/pdf/","citationCount":"0","resultStr":"{\"title\":\"Impact of Clinical Decision Support Systems on Medical Students' Case-Solving Performance: Comparison Study with a Focus Group.\",\"authors\":\"Marco Montagna, Filippo Chiabrando, Rebecca De Lorenzo, Patrizia Rovere Querini\",\"doi\":\"10.2196/55709\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Health care practitioners use clinical decision support systems (CDSS) as an aid in the crucial task of clinical reasoning and decision-making. Traditional CDSS are online repositories (ORs) and clinical practice guidelines (CPG). Recently, large language models (LLMs) such as ChatGPT have emerged as potential alternatives. They have proven to be powerful, innovative tools, yet they are not devoid of worrisome risks.</p><p><strong>Objective: </strong>This study aims to explore how medical students perform in an evaluated clinical case through the use of different CDSS tools.</p><p><strong>Methods: </strong>The authors randomly divided medical students into 3 groups, CPG, n=6 (38%); OR, n=5 (31%); and ChatGPT, n=5 (31%); and assigned each group a different type of CDSS for guidance in answering prespecified questions, assessing how students' speed and ability at resolving the same clinical case varied accordingly. External reviewers evaluated all answers based on accuracy and completeness metrics (score: 1-5). The authors analyzed and categorized group scores according to the skill investigated: differential diagnosis, diagnostic workup, and clinical decision-making.</p><p><strong>Results: </strong>Answering time showed a trend for the ChatGPT group to be the fastest. The mean scores for completeness were as follows: CPG 4.0, OR 3.7, and ChatGPT 3.8 (P=.49). The mean scores for accuracy were as follows: CPG 4.0, OR 3.3, and ChatGPT 3.7 (P=.02). Aggregating scores according to the 3 students' skill domains, trends in differences among the groups emerge more clearly, with the CPG group that performed best in nearly all domains and maintained almost perfect alignment between its completeness and accuracy.</p><p><strong>Conclusions: </strong>This hands-on session provided valuable insights into the potential perks and associated pitfalls of LLMs in medical education and practice. It suggested the critical need to include teachings in medical degree courses on how to properly take advantage of LLMs, as the potential for misuse is evident and real.</p>\",\"PeriodicalId\":36236,\"journal\":{\"name\":\"JMIR Medical Education\",\"volume\":\"11 \",\"pages\":\"e55709\"},\"PeriodicalIF\":3.2000,\"publicationDate\":\"2025-03-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11936302/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Education\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/55709\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"EDUCATION, SCIENTIFIC DISCIPLINES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Education","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/55709","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
引用次数: 0
摘要
背景:卫生保健从业人员使用临床决策支持系统(CDSS)作为辅助临床推理和决策的关键任务。传统的CDSS是在线知识库(ORs)和临床实践指南(CPG)。最近,像ChatGPT这样的大型语言模型(llm)已经成为潜在的替代方案。事实证明,它们是强大的创新工具,但它们并非没有令人担忧的风险。目的:本研究旨在探讨医学生在一个评估的临床病例中如何使用不同的CDSS工具。方法:将医学生随机分为3组,CPG组,n=6 (38%);OR, n=5 (31%);ChatGPT, n=5 (31%);并为每组分配了不同类型的CDSS,以指导他们回答预先指定的问题,评估学生解决同一临床病例的速度和能力如何相应变化。外部审稿人根据准确性和完整性指标评估所有答案(得分:1-5)。作者根据所调查的技能:鉴别诊断、诊断检查和临床决策分析和分类组得分。结果:ChatGPT组的应答时间有最快的趋势。完整性的平均得分如下:CPG 4.0, OR 3.7, ChatGPT 3.8 (P= 0.49)。准确率的平均得分如下:CPG 4.0, OR 3.3, ChatGPT 3.7 (P= 0.02)。根据3名学生的技能领域进行得分汇总,各组之间的差异趋势更加清晰,CPG组在几乎所有领域都表现最好,并且在完整性和准确性之间保持了近乎完美的一致性。结论:这一实践课程提供了宝贵的见解,了解了法学硕士在医学教育和实践中的潜在好处和相关陷阱。它建议,迫切需要在医学学位课程中纳入关于如何适当利用法学硕士的教学,因为滥用的可能性是明显和真实的。
Impact of Clinical Decision Support Systems on Medical Students' Case-Solving Performance: Comparison Study with a Focus Group.
Background: Health care practitioners use clinical decision support systems (CDSS) as an aid in the crucial task of clinical reasoning and decision-making. Traditional CDSS are online repositories (ORs) and clinical practice guidelines (CPG). Recently, large language models (LLMs) such as ChatGPT have emerged as potential alternatives. They have proven to be powerful, innovative tools, yet they are not devoid of worrisome risks.
Objective: This study aims to explore how medical students perform in an evaluated clinical case through the use of different CDSS tools.
Methods: The authors randomly divided medical students into 3 groups, CPG, n=6 (38%); OR, n=5 (31%); and ChatGPT, n=5 (31%); and assigned each group a different type of CDSS for guidance in answering prespecified questions, assessing how students' speed and ability at resolving the same clinical case varied accordingly. External reviewers evaluated all answers based on accuracy and completeness metrics (score: 1-5). The authors analyzed and categorized group scores according to the skill investigated: differential diagnosis, diagnostic workup, and clinical decision-making.
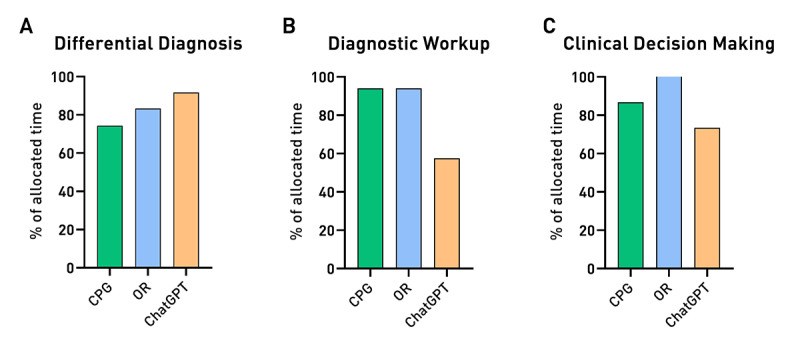
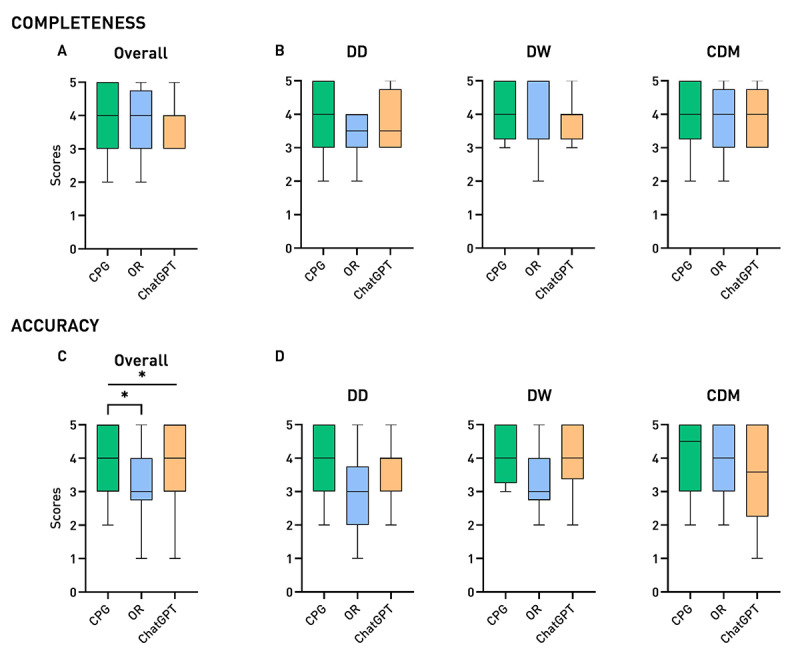
Results: Answering time showed a trend for the ChatGPT group to be the fastest. The mean scores for completeness were as follows: CPG 4.0, OR 3.7, and ChatGPT 3.8 (P=.49). The mean scores for accuracy were as follows: CPG 4.0, OR 3.3, and ChatGPT 3.7 (P=.02). Aggregating scores according to the 3 students' skill domains, trends in differences among the groups emerge more clearly, with the CPG group that performed best in nearly all domains and maintained almost perfect alignment between its completeness and accuracy.
Conclusions: This hands-on session provided valuable insights into the potential perks and associated pitfalls of LLMs in medical education and practice. It suggested the critical need to include teachings in medical degree courses on how to properly take advantage of LLMs, as the potential for misuse is evident and real.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


