Ziqi Lv, Yuhan Fan, Te Sha, Yao Cui, Yuxin Wu, Haimei Lv, Meijie Sun, Yanan Tu, Zhiqiang Xu, Weidong Wang
{"title":"用于支持深度学习的原煤智能分类和分析的大规模开放图像数据集。","authors":"Ziqi Lv, Yuhan Fan, Te Sha, Yao Cui, Yuxin Wu, Haimei Lv, Meijie Sun, Yanan Tu, Zhiqiang Xu, Weidong Wang","doi":"10.1038/s41597-025-04719-0","DOIUrl":null,"url":null,"abstract":"<p><p>Under the strategic objectives of carbon peaking and carbon neutrality, energy transition driven by new quality productive forces has emerged as a central theme in China's energy development. Among these, the intelligent sorting and analysis of raw coal using deep learning constitute a pivotal technical process. However, the progress of intelligent coal preparation in China has been constrained by the absence of accurate and large-scale data. To address this gap, this study introduces DsCGF, a large-scale, open-source raw coal image dataset. Over the past five years, extensive raw coal image samples were systematically collected and meticulously annotated from three representative mining regions in China, resulting in a dataset comprising over 270,000 visible-light images. These images are annotated at multiple levels, targeting three primary categories: coal, gangue, and foreign objects, and are designed for three core computer vision tasks: image classification, object detection, and instance segmentation. Comprehensive evaluation results indicate that the DsCGF can effectively support further research into the intelligent sorting of raw coal.</p>","PeriodicalId":21597,"journal":{"name":"Scientific Data","volume":"12 1","pages":"403"},"PeriodicalIF":6.9000,"publicationDate":"2025-03-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11890867/pdf/","citationCount":"0","resultStr":"{\"title\":\"A large-scale open image dataset for deep learning-enabled intelligent sorting and analyzing of raw coal.\",\"authors\":\"Ziqi Lv, Yuhan Fan, Te Sha, Yao Cui, Yuxin Wu, Haimei Lv, Meijie Sun, Yanan Tu, Zhiqiang Xu, Weidong Wang\",\"doi\":\"10.1038/s41597-025-04719-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Under the strategic objectives of carbon peaking and carbon neutrality, energy transition driven by new quality productive forces has emerged as a central theme in China's energy development. Among these, the intelligent sorting and analysis of raw coal using deep learning constitute a pivotal technical process. However, the progress of intelligent coal preparation in China has been constrained by the absence of accurate and large-scale data. To address this gap, this study introduces DsCGF, a large-scale, open-source raw coal image dataset. Over the past five years, extensive raw coal image samples were systematically collected and meticulously annotated from three representative mining regions in China, resulting in a dataset comprising over 270,000 visible-light images. These images are annotated at multiple levels, targeting three primary categories: coal, gangue, and foreign objects, and are designed for three core computer vision tasks: image classification, object detection, and instance segmentation. Comprehensive evaluation results indicate that the DsCGF can effectively support further research into the intelligent sorting of raw coal.</p>\",\"PeriodicalId\":21597,\"journal\":{\"name\":\"Scientific Data\",\"volume\":\"12 1\",\"pages\":\"403\"},\"PeriodicalIF\":6.9000,\"publicationDate\":\"2025-03-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11890867/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Data\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41597-025-04719-0\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Data","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41597-025-04719-0","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
A large-scale open image dataset for deep learning-enabled intelligent sorting and analyzing of raw coal.
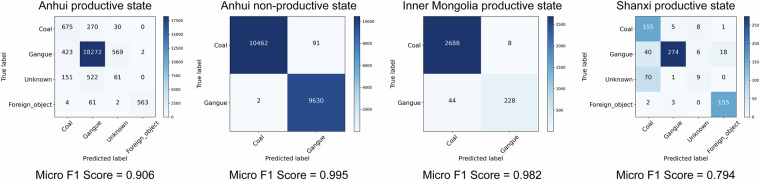
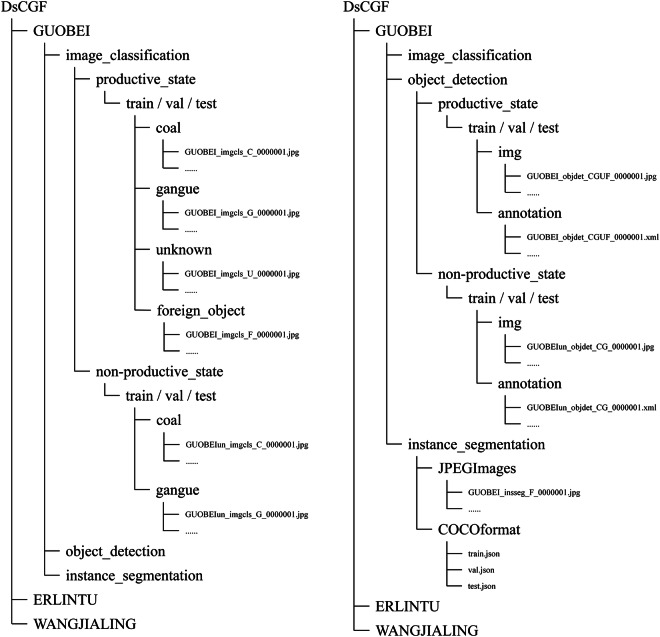
Under the strategic objectives of carbon peaking and carbon neutrality, energy transition driven by new quality productive forces has emerged as a central theme in China's energy development. Among these, the intelligent sorting and analysis of raw coal using deep learning constitute a pivotal technical process. However, the progress of intelligent coal preparation in China has been constrained by the absence of accurate and large-scale data. To address this gap, this study introduces DsCGF, a large-scale, open-source raw coal image dataset. Over the past five years, extensive raw coal image samples were systematically collected and meticulously annotated from three representative mining regions in China, resulting in a dataset comprising over 270,000 visible-light images. These images are annotated at multiple levels, targeting three primary categories: coal, gangue, and foreign objects, and are designed for three core computer vision tasks: image classification, object detection, and instance segmentation. Comprehensive evaluation results indicate that the DsCGF can effectively support further research into the intelligent sorting of raw coal.
期刊介绍:
Scientific Data is an open-access journal focused on data, publishing descriptions of research datasets and articles on data sharing across natural sciences, medicine, engineering, and social sciences. Its goal is to enhance the sharing and reuse of scientific data, encourage broader data sharing, and acknowledge those who share their data.
The journal primarily publishes Data Descriptors, which offer detailed descriptions of research datasets, including data collection methods and technical analyses validating data quality. These descriptors aim to facilitate data reuse rather than testing hypotheses or presenting new interpretations, methods, or in-depth analyses.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


