{"title":"比较创建全国随机twitter用户样本的方法。","authors":"Meysam Alizadeh, Darya Zare, Zeynab Samei, Mohammadamin Alizadeh, Mael Kubli, Mohammadhadi Aliahmadi, Sarvenaz Ebrahimi, Fabrizio Gilardi","doi":"10.1007/s13278-024-01327-5","DOIUrl":null,"url":null,"abstract":"<p><p>Twitter data has been widely used by researchers across various social and computer science disciplines. A common aim when working with Twitter data is the construction of a random sample of users from a given country. However, while several methods have been proposed in the literature, their comparative performance is mostly unexplored. In this paper, we implement four common methods to create a random sample of Twitter users in the US: <i>1% Stream</i>, <i>Bounding Box</i>, <i>Location Query</i>, and <i>Language Query</i>. Then, we compare these methods according to their tweet- and user-level metrics as well as their accuracy in estimating the US population. Our results show that users collected by the <i>1% Stream</i> method tend to have more tweets, tweets per day, followers, and friends, a fewer number of likes, are younger accounts, and include more male users compared to the other three methods. Moreover, it achieves the minimum error in estimating the US population. However, the <i>1% Stream</i> method is time-consuming, cannot be used for the past time frames, and is not suitable when user engagement is part of the study. In situation where these three drawbacks are important, our results support the <i>Bounding Box</i> method as the second-best method.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at. 10.1007/s13278-024-01327-5.</p>","PeriodicalId":21842,"journal":{"name":"Social Network Analysis and Mining","volume":"14 1","pages":"160"},"PeriodicalIF":2.8000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11861139/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparing methods for creating a national random sample of twitter users.\",\"authors\":\"Meysam Alizadeh, Darya Zare, Zeynab Samei, Mohammadamin Alizadeh, Mael Kubli, Mohammadhadi Aliahmadi, Sarvenaz Ebrahimi, Fabrizio Gilardi\",\"doi\":\"10.1007/s13278-024-01327-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Twitter data has been widely used by researchers across various social and computer science disciplines. A common aim when working with Twitter data is the construction of a random sample of users from a given country. However, while several methods have been proposed in the literature, their comparative performance is mostly unexplored. In this paper, we implement four common methods to create a random sample of Twitter users in the US: <i>1% Stream</i>, <i>Bounding Box</i>, <i>Location Query</i>, and <i>Language Query</i>. Then, we compare these methods according to their tweet- and user-level metrics as well as their accuracy in estimating the US population. Our results show that users collected by the <i>1% Stream</i> method tend to have more tweets, tweets per day, followers, and friends, a fewer number of likes, are younger accounts, and include more male users compared to the other three methods. Moreover, it achieves the minimum error in estimating the US population. However, the <i>1% Stream</i> method is time-consuming, cannot be used for the past time frames, and is not suitable when user engagement is part of the study. In situation where these three drawbacks are important, our results support the <i>Bounding Box</i> method as the second-best method.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at. 10.1007/s13278-024-01327-5.</p>\",\"PeriodicalId\":21842,\"journal\":{\"name\":\"Social Network Analysis and Mining\",\"volume\":\"14 1\",\"pages\":\"160\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11861139/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Social Network Analysis and Mining\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s13278-024-01327-5\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/8/14 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Social Network Analysis and Mining","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s13278-024-01327-5","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/14 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Comparing methods for creating a national random sample of twitter users.
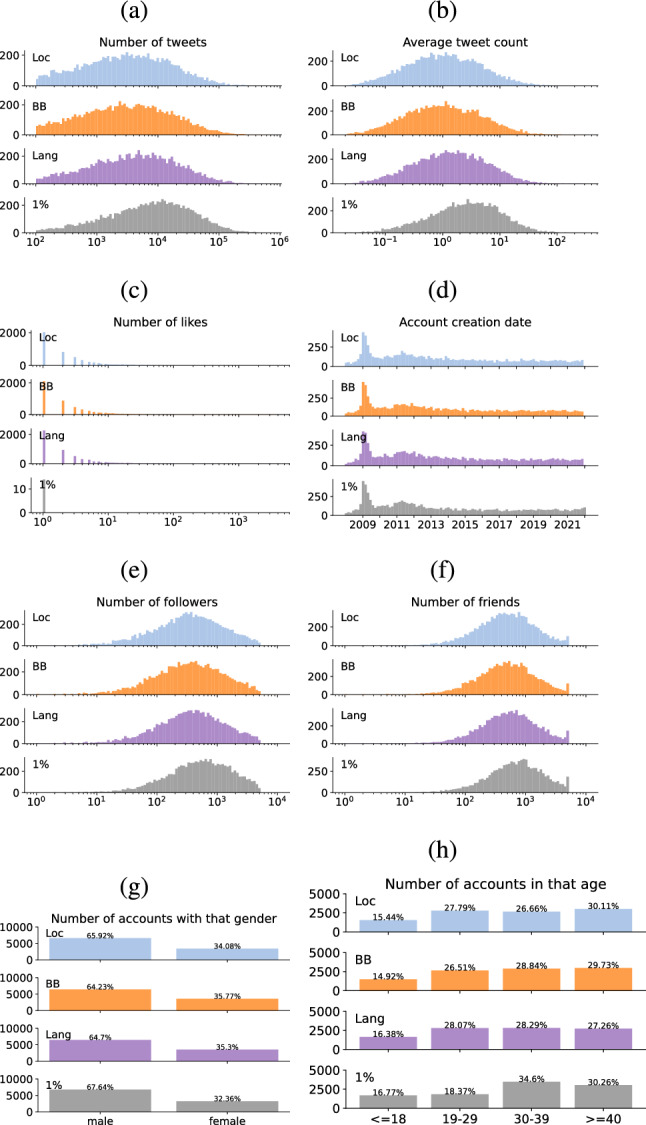
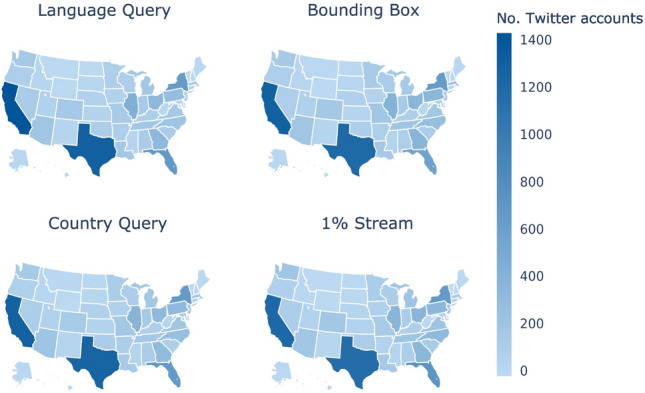
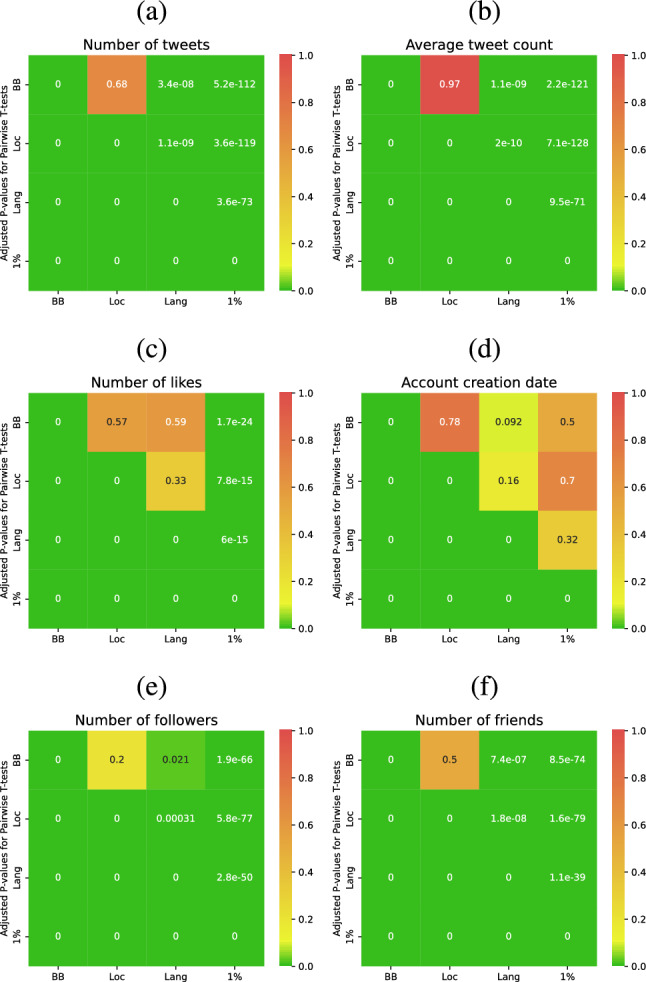
Twitter data has been widely used by researchers across various social and computer science disciplines. A common aim when working with Twitter data is the construction of a random sample of users from a given country. However, while several methods have been proposed in the literature, their comparative performance is mostly unexplored. In this paper, we implement four common methods to create a random sample of Twitter users in the US: 1% Stream, Bounding Box, Location Query, and Language Query. Then, we compare these methods according to their tweet- and user-level metrics as well as their accuracy in estimating the US population. Our results show that users collected by the 1% Stream method tend to have more tweets, tweets per day, followers, and friends, a fewer number of likes, are younger accounts, and include more male users compared to the other three methods. Moreover, it achieves the minimum error in estimating the US population. However, the 1% Stream method is time-consuming, cannot be used for the past time frames, and is not suitable when user engagement is part of the study. In situation where these three drawbacks are important, our results support the Bounding Box method as the second-best method.
Supplementary information: The online version contains supplementary material available at. 10.1007/s13278-024-01327-5.
期刊介绍:
Social Network Analysis and Mining (SNAM) is a multidisciplinary journal serving researchers and practitioners in academia and industry. It is the main venue for a wide range of researchers and readers from computer science, network science, social sciences, mathematical sciences, medical and biological sciences, financial, management and political sciences. We solicit experimental and theoretical work on social network analysis and mining using a wide range of techniques from social sciences, mathematics, statistics, physics, network science and computer science. The main areas covered by SNAM include: (1) data mining advances on the discovery and analysis of communities, personalization for solitary activities (e.g. search) and social activities (e.g. discovery of potential friends), the analysis of user behavior in open forums (e.g. conventional sites, blogs and forums) and in commercial platforms (e.g. e-auctions), and the associated security and privacy-preservation challenges; (2) social network modeling, construction of scalable and customizable social network infrastructure, identification and discovery of complex, dynamics, growth, and evolution patterns using machine learning and data mining approaches or multi-agent based simulation; (3) social network analysis and mining for open source intelligence and homeland security. Papers should elaborate on data mining and machine learning or related methods, issues associated to data preparation and pattern interpretation, both for conventional data (usage logs, query logs, document collections) and for multimedia data (pictures and their annotations, multi-channel usage data). Topics include but are not limited to: Applications of social network in business engineering, scientific and medical domains, homeland security, terrorism and criminology, fraud detection, public sector, politics, and case studies.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


