Seungheon Choo, Suyoung Yoo, Kumiko Endo, Bao Truong, Meong Hi Son
{"title":"使用人工智能评估推进临床聊天机器人验证与新的3-Bot评估系统:仪器验证研究。","authors":"Seungheon Choo, Suyoung Yoo, Kumiko Endo, Bao Truong, Meong Hi Son","doi":"10.2196/63058","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The health care sector faces a projected shortfall of 10 million workers by 2030. Artificial intelligence (AI) automation in areas such as patient education and initial therapy screening presents a strategic response to mitigate this shortage and reallocate medical staff to higher-priority tasks. However, current methods of evaluating early-stage health care AI chatbots are highly limited due to safety concerns and the amount of time and effort that goes into evaluating them.</p><p><strong>Objective: </strong>This study introduces a novel 3-bot method for efficiently testing and validating early-stage AI health care provider chatbots. To extensively test AI provider chatbots without involving real patients or researchers, various AI patient bots and an evaluator bot were developed.</p><p><strong>Methods: </strong>Provider bots interacted with AI patient bots embodying frustrated, anxious, or depressed personas. An evaluator bot reviewed interaction transcripts based on specific criteria. Human experts then reviewed each interaction transcript, and the evaluator bot's results were compared to human evaluation results to ensure accuracy.</p><p><strong>Results: </strong>The patient-education bot's evaluations by the AI evaluator and the human evaluator were nearly identical, with minimal variance, limiting the opportunity for further analysis. The screening bot's evaluations also yielded similar results between the AI evaluator and human evaluator. Statistical analysis confirmed the reliability and accuracy of the AI evaluations.</p><p><strong>Conclusions: </strong>The innovative evaluation method ensures a safe, adaptable, and effective means to test and refine early versions of health care provider chatbots without risking patient safety or investing excessive researcher time and effort. Our patient-education evaluator bots could have benefitted from larger evaluation criteria, as we had extremely similar results from the AI and human evaluators, which could have arisen because of the small number of evaluation criteria. We were limited in the amount of prompting we could input into each bot due to the practical consideration that response time increases with larger and larger prompts. In the future, using techniques such as retrieval augmented generation will allow the system to receive more information and become more specific and accurate in evaluating the chatbots. This evaluation method will allow for rapid testing and validation of health care chatbots to automate basic medical tasks, freeing providers to address more complex tasks.</p>","PeriodicalId":73556,"journal":{"name":"JMIR nursing","volume":"8 ","pages":"e63058"},"PeriodicalIF":4.0000,"publicationDate":"2025-02-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11884306/pdf/","citationCount":"0","resultStr":"{\"title\":\"Advancing Clinical Chatbot Validation Using AI-Powered Evaluation With a New 3-Bot Evaluation System: Instrument Validation Study.\",\"authors\":\"Seungheon Choo, Suyoung Yoo, Kumiko Endo, Bao Truong, Meong Hi Son\",\"doi\":\"10.2196/63058\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The health care sector faces a projected shortfall of 10 million workers by 2030. Artificial intelligence (AI) automation in areas such as patient education and initial therapy screening presents a strategic response to mitigate this shortage and reallocate medical staff to higher-priority tasks. However, current methods of evaluating early-stage health care AI chatbots are highly limited due to safety concerns and the amount of time and effort that goes into evaluating them.</p><p><strong>Objective: </strong>This study introduces a novel 3-bot method for efficiently testing and validating early-stage AI health care provider chatbots. To extensively test AI provider chatbots without involving real patients or researchers, various AI patient bots and an evaluator bot were developed.</p><p><strong>Methods: </strong>Provider bots interacted with AI patient bots embodying frustrated, anxious, or depressed personas. An evaluator bot reviewed interaction transcripts based on specific criteria. Human experts then reviewed each interaction transcript, and the evaluator bot's results were compared to human evaluation results to ensure accuracy.</p><p><strong>Results: </strong>The patient-education bot's evaluations by the AI evaluator and the human evaluator were nearly identical, with minimal variance, limiting the opportunity for further analysis. The screening bot's evaluations also yielded similar results between the AI evaluator and human evaluator. Statistical analysis confirmed the reliability and accuracy of the AI evaluations.</p><p><strong>Conclusions: </strong>The innovative evaluation method ensures a safe, adaptable, and effective means to test and refine early versions of health care provider chatbots without risking patient safety or investing excessive researcher time and effort. Our patient-education evaluator bots could have benefitted from larger evaluation criteria, as we had extremely similar results from the AI and human evaluators, which could have arisen because of the small number of evaluation criteria. We were limited in the amount of prompting we could input into each bot due to the practical consideration that response time increases with larger and larger prompts. In the future, using techniques such as retrieval augmented generation will allow the system to receive more information and become more specific and accurate in evaluating the chatbots. This evaluation method will allow for rapid testing and validation of health care chatbots to automate basic medical tasks, freeing providers to address more complex tasks.</p>\",\"PeriodicalId\":73556,\"journal\":{\"name\":\"JMIR nursing\",\"volume\":\"8 \",\"pages\":\"e63058\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2025-02-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11884306/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR nursing\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/63058\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR nursing","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/63058","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Advancing Clinical Chatbot Validation Using AI-Powered Evaluation With a New 3-Bot Evaluation System: Instrument Validation Study.
Background: The health care sector faces a projected shortfall of 10 million workers by 2030. Artificial intelligence (AI) automation in areas such as patient education and initial therapy screening presents a strategic response to mitigate this shortage and reallocate medical staff to higher-priority tasks. However, current methods of evaluating early-stage health care AI chatbots are highly limited due to safety concerns and the amount of time and effort that goes into evaluating them.
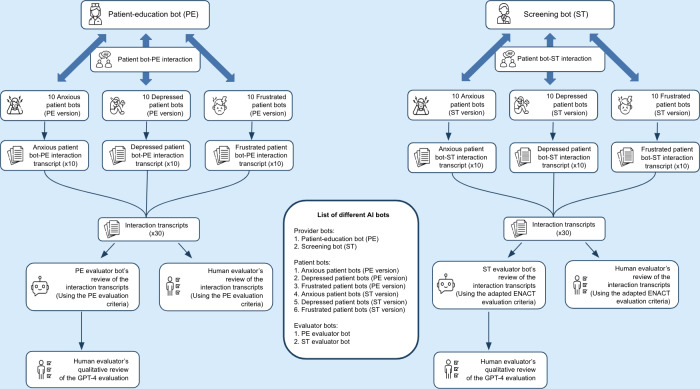
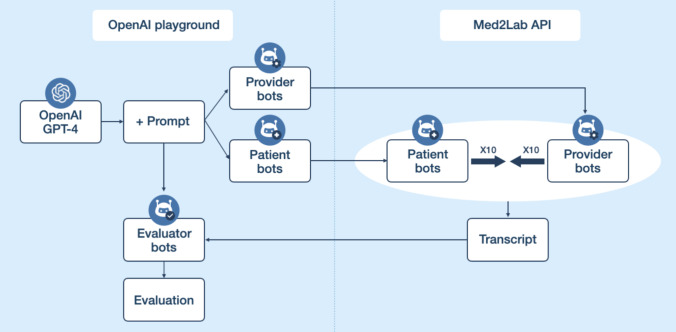
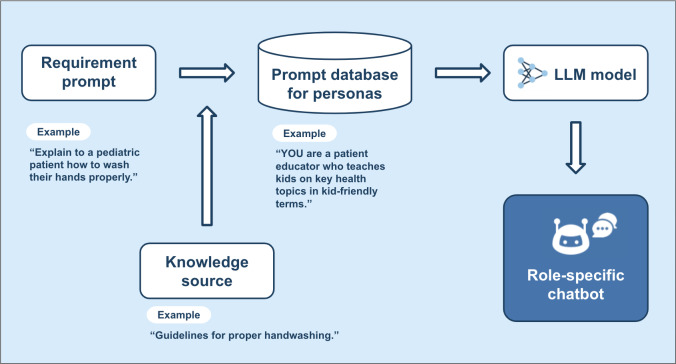
Objective: This study introduces a novel 3-bot method for efficiently testing and validating early-stage AI health care provider chatbots. To extensively test AI provider chatbots without involving real patients or researchers, various AI patient bots and an evaluator bot were developed.
Methods: Provider bots interacted with AI patient bots embodying frustrated, anxious, or depressed personas. An evaluator bot reviewed interaction transcripts based on specific criteria. Human experts then reviewed each interaction transcript, and the evaluator bot's results were compared to human evaluation results to ensure accuracy.
Results: The patient-education bot's evaluations by the AI evaluator and the human evaluator were nearly identical, with minimal variance, limiting the opportunity for further analysis. The screening bot's evaluations also yielded similar results between the AI evaluator and human evaluator. Statistical analysis confirmed the reliability and accuracy of the AI evaluations.
Conclusions: The innovative evaluation method ensures a safe, adaptable, and effective means to test and refine early versions of health care provider chatbots without risking patient safety or investing excessive researcher time and effort. Our patient-education evaluator bots could have benefitted from larger evaluation criteria, as we had extremely similar results from the AI and human evaluators, which could have arisen because of the small number of evaluation criteria. We were limited in the amount of prompting we could input into each bot due to the practical consideration that response time increases with larger and larger prompts. In the future, using techniques such as retrieval augmented generation will allow the system to receive more information and become more specific and accurate in evaluating the chatbots. This evaluation method will allow for rapid testing and validation of health care chatbots to automate basic medical tasks, freeing providers to address more complex tasks.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


