João A Leite, Olesya Razuvayevskaya, Kalina Bontcheva, Carolina Scarton
{"title":"基于llm预测可信度信号的弱监督准确率分类。","authors":"João A Leite, Olesya Razuvayevskaya, Kalina Bontcheva, Carolina Scarton","doi":"10.1140/epjds/s13688-025-00534-0","DOIUrl":null,"url":null,"abstract":"<p><p>Credibility signals represent a wide range of heuristics typically used by journalists and fact-checkers to assess the veracity of online content. Automating the extraction of credibility signals presents significant challenges due to the necessity of training high-accuracy, signal-specific extractors, coupled with the lack of sufficiently large annotated datasets. This paper introduces Pastel (<b>P</b>rompted we<b>A</b>k <b>S</b>upervision wi<b>T</b>h cr<b>E</b>dibility signa<b>L</b>s), a weakly supervised approach that leverages large language models (LLMs) to extract credibility signals from web content, and subsequently combines them to predict the veracity of content without relying on human supervision. We validate our approach using four article-level misinformation detection datasets, demonstrating that Pastel outperforms zero-shot veracity detection by 38.3% and achieves 86.7% of the performance of the state-of-the-art system trained with human supervision. Moreover, in cross-domain settings where training and testing datasets originate from different domains, Pastel significantly outperforms the state-of-the-art supervised model by 63%. We further study the association between credibility signals and veracity, and perform an ablation study showing the impact of each signal on model performance. Our findings reveal that 12 out of the 19 proposed signals exhibit strong associations with veracity across all datasets, while some signals show domain-specific strengths.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1140/epjds/s13688-025-00534-0.</p>","PeriodicalId":11887,"journal":{"name":"EPJ Data Science","volume":"14 1","pages":"16"},"PeriodicalIF":2.5000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11845407/pdf/","citationCount":"0","resultStr":"{\"title\":\"Weakly supervised veracity classification with LLM-predicted credibility signals.\",\"authors\":\"João A Leite, Olesya Razuvayevskaya, Kalina Bontcheva, Carolina Scarton\",\"doi\":\"10.1140/epjds/s13688-025-00534-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Credibility signals represent a wide range of heuristics typically used by journalists and fact-checkers to assess the veracity of online content. Automating the extraction of credibility signals presents significant challenges due to the necessity of training high-accuracy, signal-specific extractors, coupled with the lack of sufficiently large annotated datasets. This paper introduces Pastel (<b>P</b>rompted we<b>A</b>k <b>S</b>upervision wi<b>T</b>h cr<b>E</b>dibility signa<b>L</b>s), a weakly supervised approach that leverages large language models (LLMs) to extract credibility signals from web content, and subsequently combines them to predict the veracity of content without relying on human supervision. We validate our approach using four article-level misinformation detection datasets, demonstrating that Pastel outperforms zero-shot veracity detection by 38.3% and achieves 86.7% of the performance of the state-of-the-art system trained with human supervision. Moreover, in cross-domain settings where training and testing datasets originate from different domains, Pastel significantly outperforms the state-of-the-art supervised model by 63%. We further study the association between credibility signals and veracity, and perform an ablation study showing the impact of each signal on model performance. Our findings reveal that 12 out of the 19 proposed signals exhibit strong associations with veracity across all datasets, while some signals show domain-specific strengths.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1140/epjds/s13688-025-00534-0.</p>\",\"PeriodicalId\":11887,\"journal\":{\"name\":\"EPJ Data Science\",\"volume\":\"14 1\",\"pages\":\"16\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11845407/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"EPJ Data Science\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1140/epjds/s13688-025-00534-0\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/2/21 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"EPJ Data Science","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1140/epjds/s13688-025-00534-0","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/2/21 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
摘要
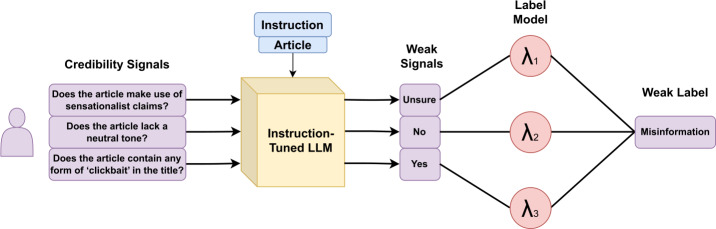
可信度信号代表了广泛的启发式方法,通常由记者和事实核查员用来评估在线内容的真实性。由于需要训练高精度、特定信号的提取器,再加上缺乏足够大的注释数据集,可信度信号的自动提取面临着重大挑战。本文介绍了一种弱监督方法Pastel (prompt weAk Supervision wiTh crEdibility signaLs),它利用大型语言模型(llm)从web内容中提取可信度信号,然后将它们组合在一起,在不依赖人工监督的情况下预测内容的真实性。我们使用四篇文章级别的错误信息检测数据集验证了我们的方法,结果表明,Pastel比零射击准确率检测高出38.3%,达到了人工监督训练的最先进系统性能的86.7%。此外,在训练和测试数据集来自不同领域的跨领域设置中,Pastel显著优于最先进的监督模型63%。我们进一步研究了可信度信号和准确性之间的关系,并进行了消融研究,显示了每个信号对模型性能的影响。我们的研究结果表明,19个提议的信号中有12个与所有数据集的准确性表现出很强的相关性,而一些信号则表现出特定领域的优势。补充信息:在线版本包含补充资料,可在10.1140/epjds/s13688-025-00534-0获得。
Weakly supervised veracity classification with LLM-predicted credibility signals.
Credibility signals represent a wide range of heuristics typically used by journalists and fact-checkers to assess the veracity of online content. Automating the extraction of credibility signals presents significant challenges due to the necessity of training high-accuracy, signal-specific extractors, coupled with the lack of sufficiently large annotated datasets. This paper introduces Pastel (Prompted weAk Supervision wiTh crEdibility signaLs), a weakly supervised approach that leverages large language models (LLMs) to extract credibility signals from web content, and subsequently combines them to predict the veracity of content without relying on human supervision. We validate our approach using four article-level misinformation detection datasets, demonstrating that Pastel outperforms zero-shot veracity detection by 38.3% and achieves 86.7% of the performance of the state-of-the-art system trained with human supervision. Moreover, in cross-domain settings where training and testing datasets originate from different domains, Pastel significantly outperforms the state-of-the-art supervised model by 63%. We further study the association between credibility signals and veracity, and perform an ablation study showing the impact of each signal on model performance. Our findings reveal that 12 out of the 19 proposed signals exhibit strong associations with veracity across all datasets, while some signals show domain-specific strengths.
Supplementary information: The online version contains supplementary material available at 10.1140/epjds/s13688-025-00534-0.
期刊介绍:
EPJ Data Science covers a broad range of research areas and applications and particularly encourages contributions from techno-socio-economic systems, where it comprises those research lines that now regard the digital “tracks” of human beings as first-order objects for scientific investigation. Topics include, but are not limited to, human behavior, social interaction (including animal societies), economic and financial systems, management and business networks, socio-technical infrastructure, health and environmental systems, the science of science, as well as general risk and crisis scenario forecasting up to and including policy advice.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


