Phillip Park, Yeonho Choi, Nayoung Han, Ye-Lin Park, Juyeon Hwang, Heejung Chae, Chong Woo Yoo, Kui Son Choi, Hyun-Jin Kim
{"title":"利用自然语言处理从乳腺癌病理报告中有效地提取信息:单机构研究。","authors":"Phillip Park, Yeonho Choi, Nayoung Han, Ye-Lin Park, Juyeon Hwang, Heejung Chae, Chong Woo Yoo, Kui Son Choi, Hyun-Jin Kim","doi":"10.1371/journal.pone.0318726","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Pathology reports provide important information for accurate diagnosis of cancer and optimal treatment decision making. In particular, breast cancer has known to be the most common cancer in women worldwide.</p><p><strong>Objective: </strong>For the data extraction of breast cancer pathology reports in a single institute, we assessed the accuracy of methods between regular expression and natural language processing (NLP).</p><p><strong>Methods: </strong>A total of 1,215 breast cancer pathology reports were annotated for NLP model development. As NLP models, we considered three BERT models with specific vocabularies including BERT-basic, BioBERT, and ClinicalBERT. K-fold cross-validation was used to verify the performance of the BERT model. The results between the regular expression and the BERT model were compared using the named entity recognition (NER) techniques.</p><p><strong>Results: </strong>Among three BERT models, BioBERT was the most accurate parsing model (average performance = 0.99901) for breast cancer pathology when set to k = 5. BioBERT also had the lowest error rate for all items in the breast cancer pathology report compared to other BERT models (accuracy for all variables ≥ 0.9). Therefore, we finally selected BioBERT as the NLP model. When comparing the results of BioBERT and regular expressions using NER, we identified that BioBERT was more accurate than regular expression method, especially for some items such as intraductal component (BioBERT: 1.0, RegEx: 0.1644), lymph node (BioBERT: 0.9886, RegEx: 0.4792), and lymphovascular invasion (BioBERT: 0.9918, RegEx: 0.3759).</p><p><strong>Conclusions: </strong>Our results showed that the NLP model, BioBERT, had higher accuracy than regular expression, suggesting the importance of BioBERT in the processing of breast cancer pathology reports.</p>","PeriodicalId":20189,"journal":{"name":"PLoS ONE","volume":"20 2","pages":"e0318726"},"PeriodicalIF":2.6000,"publicationDate":"2025-02-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12005671/pdf/","citationCount":"0","resultStr":"{\"title\":\"Leveraging natural language processing for efficient information extraction from breast cancer pathology reports: Single-institution study.\",\"authors\":\"Phillip Park, Yeonho Choi, Nayoung Han, Ye-Lin Park, Juyeon Hwang, Heejung Chae, Chong Woo Yoo, Kui Son Choi, Hyun-Jin Kim\",\"doi\":\"10.1371/journal.pone.0318726\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Pathology reports provide important information for accurate diagnosis of cancer and optimal treatment decision making. In particular, breast cancer has known to be the most common cancer in women worldwide.</p><p><strong>Objective: </strong>For the data extraction of breast cancer pathology reports in a single institute, we assessed the accuracy of methods between regular expression and natural language processing (NLP).</p><p><strong>Methods: </strong>A total of 1,215 breast cancer pathology reports were annotated for NLP model development. As NLP models, we considered three BERT models with specific vocabularies including BERT-basic, BioBERT, and ClinicalBERT. K-fold cross-validation was used to verify the performance of the BERT model. The results between the regular expression and the BERT model were compared using the named entity recognition (NER) techniques.</p><p><strong>Results: </strong>Among three BERT models, BioBERT was the most accurate parsing model (average performance = 0.99901) for breast cancer pathology when set to k = 5. BioBERT also had the lowest error rate for all items in the breast cancer pathology report compared to other BERT models (accuracy for all variables ≥ 0.9). Therefore, we finally selected BioBERT as the NLP model. When comparing the results of BioBERT and regular expressions using NER, we identified that BioBERT was more accurate than regular expression method, especially for some items such as intraductal component (BioBERT: 1.0, RegEx: 0.1644), lymph node (BioBERT: 0.9886, RegEx: 0.4792), and lymphovascular invasion (BioBERT: 0.9918, RegEx: 0.3759).</p><p><strong>Conclusions: </strong>Our results showed that the NLP model, BioBERT, had higher accuracy than regular expression, suggesting the importance of BioBERT in the processing of breast cancer pathology reports.</p>\",\"PeriodicalId\":20189,\"journal\":{\"name\":\"PLoS ONE\",\"volume\":\"20 2\",\"pages\":\"e0318726\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2025-02-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12005671/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLoS ONE\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pone.0318726\",\"RegionNum\":3,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLoS ONE","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1371/journal.pone.0318726","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Leveraging natural language processing for efficient information extraction from breast cancer pathology reports: Single-institution study.
Background: Pathology reports provide important information for accurate diagnosis of cancer and optimal treatment decision making. In particular, breast cancer has known to be the most common cancer in women worldwide.
Objective: For the data extraction of breast cancer pathology reports in a single institute, we assessed the accuracy of methods between regular expression and natural language processing (NLP).
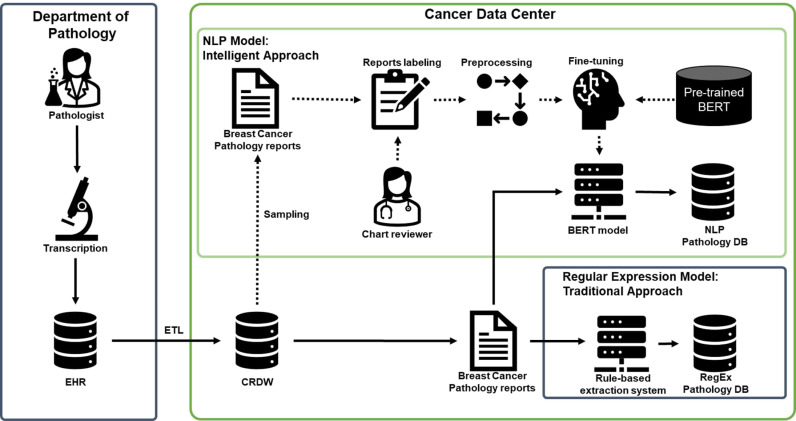
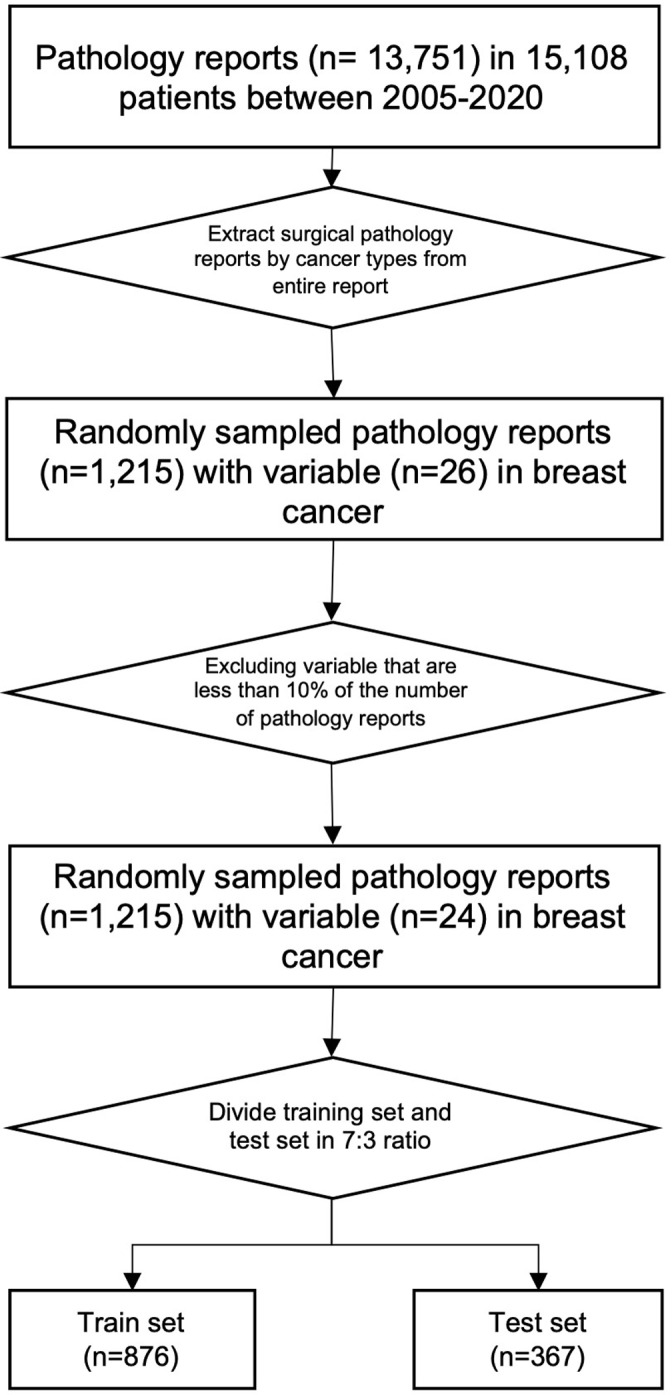
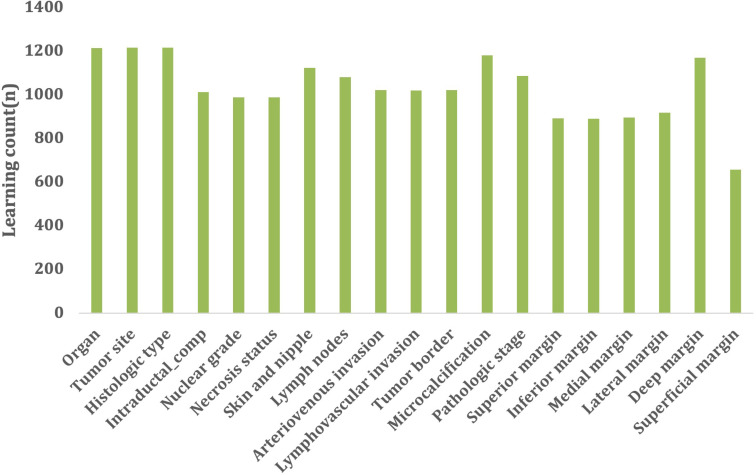
Methods: A total of 1,215 breast cancer pathology reports were annotated for NLP model development. As NLP models, we considered three BERT models with specific vocabularies including BERT-basic, BioBERT, and ClinicalBERT. K-fold cross-validation was used to verify the performance of the BERT model. The results between the regular expression and the BERT model were compared using the named entity recognition (NER) techniques.
Results: Among three BERT models, BioBERT was the most accurate parsing model (average performance = 0.99901) for breast cancer pathology when set to k = 5. BioBERT also had the lowest error rate for all items in the breast cancer pathology report compared to other BERT models (accuracy for all variables ≥ 0.9). Therefore, we finally selected BioBERT as the NLP model. When comparing the results of BioBERT and regular expressions using NER, we identified that BioBERT was more accurate than regular expression method, especially for some items such as intraductal component (BioBERT: 1.0, RegEx: 0.1644), lymph node (BioBERT: 0.9886, RegEx: 0.4792), and lymphovascular invasion (BioBERT: 0.9918, RegEx: 0.3759).
Conclusions: Our results showed that the NLP model, BioBERT, had higher accuracy than regular expression, suggesting the importance of BioBERT in the processing of breast cancer pathology reports.
期刊介绍:
PLOS ONE is an international, peer-reviewed, open-access, online publication. PLOS ONE welcomes reports on primary research from any scientific discipline. It provides:
* Open-access—freely accessible online, authors retain copyright
* Fast publication times
* Peer review by expert, practicing researchers
* Post-publication tools to indicate quality and impact
* Community-based dialogue on articles
* Worldwide media coverage

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


