{"title":"伊朗人群高血压患病率及影响因素研究:来自Fasa队列研究的结果","authors":"Seyede Melika Taheri Ghaleno, Abdollah Safari, Reza Homayounfar, Mojtaba Farjam, Mehdi Rezaeian, Fariba Asadi, Fatemeh Masaebi, Masoud Salehi, Maryam Heydarpour Meymeh, Farid Zayeri","doi":"10.47176/mjiri.38.123","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>In recent years, hypertension has been one of the most important noncommunicable diseases worldwide. In this context, identifying the predictors of this disease can help health policymakers to reduce its burden. This study aimed to identify some of the most important influential factors of hypertension and present a model to predict this disease in the data from a large sample cohort study.</p><p><strong>Methods: </strong>The data set included 10,138 people from the baseline phase of the Fasa cohort study during 2014 and 2016. The main outcome under study was having hypertension in the baseline phase of the study according to self-reports or medical examinations. To identify the related factors of hypertension, logistic regression, classification tree, and random forest models were utilized. Statistical analyses were performed in R.</p><p><strong>Results: </strong>Among the 10,138 people examined, 2819 (27.8%) had hypertension. In the initial screening, 39 variables were regarded as potential indicators of hypertension. After preliminary analysis, 11 variables were recognized as important predictors based on the importance index: history of cardiovascular disease, cardiac disease, waist circumference to height ratio, body mass index, sex, hypertension in a first-degree relative, weight, fatty liver, cardiac disease in a first-degree relative, diabetes in a first-degree relative, and energy intake. The area under the receiving operating characteristic (ROC) curve for predicting hypertension using logistic regression, classification tree, and random forest models was about 72.8%, 73%, and 87.6%, respectively. Also, the accuracy of these models was 65.2%, 67.4% and 77.8%, respectively.</p><p><strong>Conclusion: </strong>In general, our findings showed that machine learning-based approaches, such as random forest models, outperformed classical methods, such as logistic regression in predicting hypertension. Regarding the rather high prevalence of hypertension in the population under study, there is an urgent need to pay more attention to its indicators for early diagnosis of the patients and reducing the burden of this silent disease in our country.</p>","PeriodicalId":18361,"journal":{"name":"Medical Journal of the Islamic Republic of Iran","volume":"38 ","pages":"123"},"PeriodicalIF":0.0000,"publicationDate":"2024-10-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11835403/pdf/","citationCount":"0","resultStr":"{\"title\":\"A Study on Prevalence and Factors Affecting Hypertension in an Iranian Population: Results from the Fasa Cohort Study.\",\"authors\":\"Seyede Melika Taheri Ghaleno, Abdollah Safari, Reza Homayounfar, Mojtaba Farjam, Mehdi Rezaeian, Fariba Asadi, Fatemeh Masaebi, Masoud Salehi, Maryam Heydarpour Meymeh, Farid Zayeri\",\"doi\":\"10.47176/mjiri.38.123\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>In recent years, hypertension has been one of the most important noncommunicable diseases worldwide. In this context, identifying the predictors of this disease can help health policymakers to reduce its burden. This study aimed to identify some of the most important influential factors of hypertension and present a model to predict this disease in the data from a large sample cohort study.</p><p><strong>Methods: </strong>The data set included 10,138 people from the baseline phase of the Fasa cohort study during 2014 and 2016. The main outcome under study was having hypertension in the baseline phase of the study according to self-reports or medical examinations. To identify the related factors of hypertension, logistic regression, classification tree, and random forest models were utilized. Statistical analyses were performed in R.</p><p><strong>Results: </strong>Among the 10,138 people examined, 2819 (27.8%) had hypertension. In the initial screening, 39 variables were regarded as potential indicators of hypertension. After preliminary analysis, 11 variables were recognized as important predictors based on the importance index: history of cardiovascular disease, cardiac disease, waist circumference to height ratio, body mass index, sex, hypertension in a first-degree relative, weight, fatty liver, cardiac disease in a first-degree relative, diabetes in a first-degree relative, and energy intake. The area under the receiving operating characteristic (ROC) curve for predicting hypertension using logistic regression, classification tree, and random forest models was about 72.8%, 73%, and 87.6%, respectively. Also, the accuracy of these models was 65.2%, 67.4% and 77.8%, respectively.</p><p><strong>Conclusion: </strong>In general, our findings showed that machine learning-based approaches, such as random forest models, outperformed classical methods, such as logistic regression in predicting hypertension. Regarding the rather high prevalence of hypertension in the population under study, there is an urgent need to pay more attention to its indicators for early diagnosis of the patients and reducing the burden of this silent disease in our country.</p>\",\"PeriodicalId\":18361,\"journal\":{\"name\":\"Medical Journal of the Islamic Republic of Iran\",\"volume\":\"38 \",\"pages\":\"123\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-10-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11835403/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Medical Journal of the Islamic Republic of Iran\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.47176/mjiri.38.123\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical Journal of the Islamic Republic of Iran","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.47176/mjiri.38.123","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
A Study on Prevalence and Factors Affecting Hypertension in an Iranian Population: Results from the Fasa Cohort Study.
Background: In recent years, hypertension has been one of the most important noncommunicable diseases worldwide. In this context, identifying the predictors of this disease can help health policymakers to reduce its burden. This study aimed to identify some of the most important influential factors of hypertension and present a model to predict this disease in the data from a large sample cohort study.
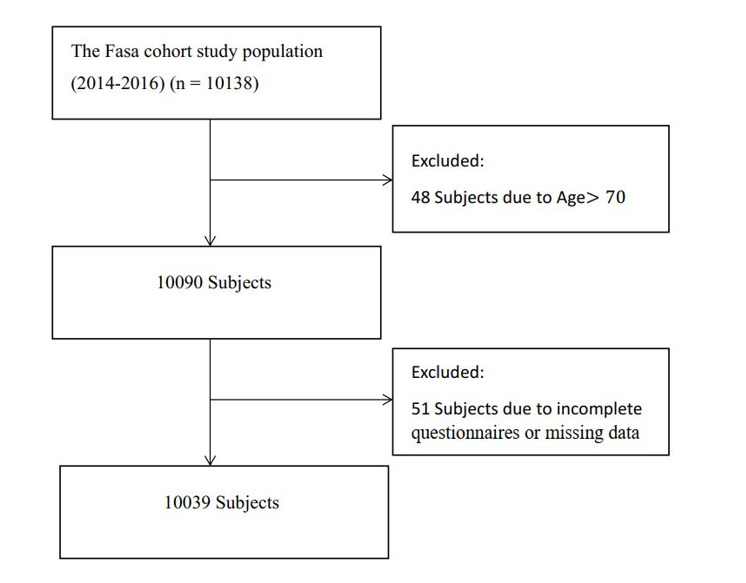
Methods: The data set included 10,138 people from the baseline phase of the Fasa cohort study during 2014 and 2016. The main outcome under study was having hypertension in the baseline phase of the study according to self-reports or medical examinations. To identify the related factors of hypertension, logistic regression, classification tree, and random forest models were utilized. Statistical analyses were performed in R.
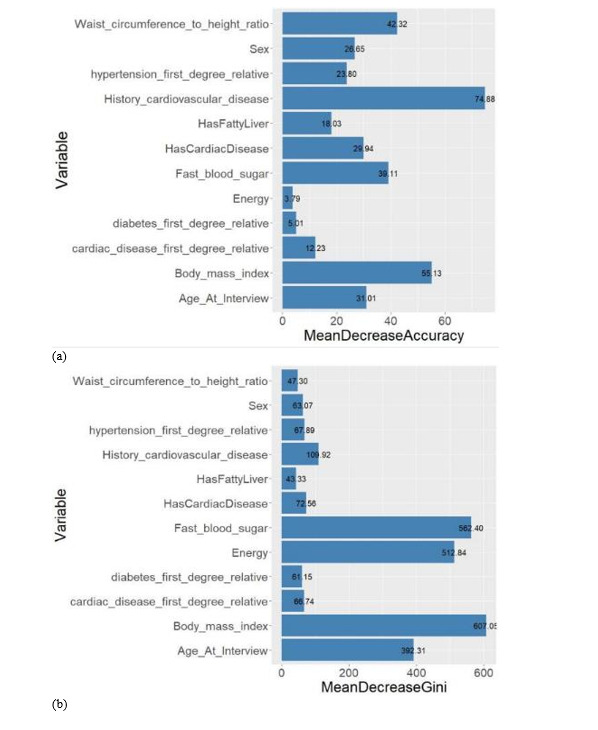
Results: Among the 10,138 people examined, 2819 (27.8%) had hypertension. In the initial screening, 39 variables were regarded as potential indicators of hypertension. After preliminary analysis, 11 variables were recognized as important predictors based on the importance index: history of cardiovascular disease, cardiac disease, waist circumference to height ratio, body mass index, sex, hypertension in a first-degree relative, weight, fatty liver, cardiac disease in a first-degree relative, diabetes in a first-degree relative, and energy intake. The area under the receiving operating characteristic (ROC) curve for predicting hypertension using logistic regression, classification tree, and random forest models was about 72.8%, 73%, and 87.6%, respectively. Also, the accuracy of these models was 65.2%, 67.4% and 77.8%, respectively.
Conclusion: In general, our findings showed that machine learning-based approaches, such as random forest models, outperformed classical methods, such as logistic regression in predicting hypertension. Regarding the rather high prevalence of hypertension in the population under study, there is an urgent need to pay more attention to its indicators for early diagnosis of the patients and reducing the burden of this silent disease in our country.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


