Luigi Naldi, Vincenzo Bettoli, Eugenio Santoro, Maria Rosa Valetto, Anna Bolzon, Fortunato Cassalia, Simone Cazzaniga, Sergio Cima, Andrea Danese, Silvia Emendi, Monica Ponzano, Nicoletta Scarpa, Pietro Dri
{"title":"ChatGPT作为内容生成工具在继续医学教育中的应用:痤疮作为测试主题。","authors":"Luigi Naldi, Vincenzo Bettoli, Eugenio Santoro, Maria Rosa Valetto, Anna Bolzon, Fortunato Cassalia, Simone Cazzaniga, Sergio Cima, Andrea Danese, Silvia Emendi, Monica Ponzano, Nicoletta Scarpa, Pietro Dri","doi":"10.4081/dr.2024.10138","DOIUrl":null,"url":null,"abstract":"<p><p>The large language model (LLM) ChatGPT can answer open-ended and complex questions, but its accuracy in providing reliable medical information requires a careful assessment. As part of the AI-CHECK (Artificial Intelligence for CME Health E-learning Contents and Knowledge) study, aimed at evaluating the potential of ChatGPT in continuous medical education (CME), we compared ChatGPT-generated educational content to the recommendations of the National Institute for Health and Care Excellence (NICE) guidelines on acne vulgaris. ChatGPT version 4 was exposed to a 23-item questionnaire developed by an experienced dermatologist. A panel of five dermatologists rated the answers positively in terms of \"quality\" (87.8%), \"readability\" (94.8%), \"accuracy\" (75.7%), \"thoroughness\" (85.2%), and \"consistency\" with guidelines (76.8%). The references provided by ChatGPT obtained positive ratings for \"pertinence\" (94.6%), \"relevance\" (91.2%), and \"update\" (62.3%). The internal reproducibility was adequate both for answers (93.5%) and references (67.4%). Answers related to issues of uncertainty and/or controversy in the scientific community scored the lowest. This study underscores the need to develop rigorous evaluation criteria for AI-generated medical content and for expert oversight to ensure accuracy and guideline adherence.</p>","PeriodicalId":11049,"journal":{"name":"Dermatology Reports","volume":" ","pages":""},"PeriodicalIF":1.3000,"publicationDate":"2025-05-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12210357/pdf/","citationCount":"0","resultStr":"{\"title\":\"Application of ChatGPT as a content generation tool in continuing medical education: acne as a test topic.\",\"authors\":\"Luigi Naldi, Vincenzo Bettoli, Eugenio Santoro, Maria Rosa Valetto, Anna Bolzon, Fortunato Cassalia, Simone Cazzaniga, Sergio Cima, Andrea Danese, Silvia Emendi, Monica Ponzano, Nicoletta Scarpa, Pietro Dri\",\"doi\":\"10.4081/dr.2024.10138\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The large language model (LLM) ChatGPT can answer open-ended and complex questions, but its accuracy in providing reliable medical information requires a careful assessment. As part of the AI-CHECK (Artificial Intelligence for CME Health E-learning Contents and Knowledge) study, aimed at evaluating the potential of ChatGPT in continuous medical education (CME), we compared ChatGPT-generated educational content to the recommendations of the National Institute for Health and Care Excellence (NICE) guidelines on acne vulgaris. ChatGPT version 4 was exposed to a 23-item questionnaire developed by an experienced dermatologist. A panel of five dermatologists rated the answers positively in terms of \\\"quality\\\" (87.8%), \\\"readability\\\" (94.8%), \\\"accuracy\\\" (75.7%), \\\"thoroughness\\\" (85.2%), and \\\"consistency\\\" with guidelines (76.8%). The references provided by ChatGPT obtained positive ratings for \\\"pertinence\\\" (94.6%), \\\"relevance\\\" (91.2%), and \\\"update\\\" (62.3%). The internal reproducibility was adequate both for answers (93.5%) and references (67.4%). Answers related to issues of uncertainty and/or controversy in the scientific community scored the lowest. This study underscores the need to develop rigorous evaluation criteria for AI-generated medical content and for expert oversight to ensure accuracy and guideline adherence.</p>\",\"PeriodicalId\":11049,\"journal\":{\"name\":\"Dermatology Reports\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2025-05-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12210357/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Dermatology Reports\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4081/dr.2024.10138\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/11/28 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"DERMATOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Dermatology Reports","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4081/dr.2024.10138","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/28 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"DERMATOLOGY","Score":null,"Total":0}
Application of ChatGPT as a content generation tool in continuing medical education: acne as a test topic.
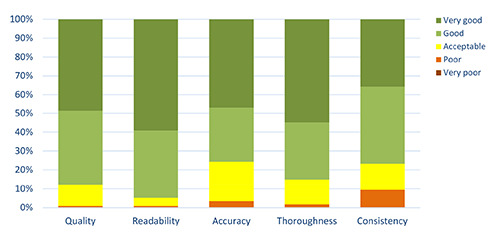
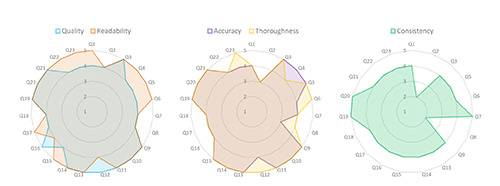
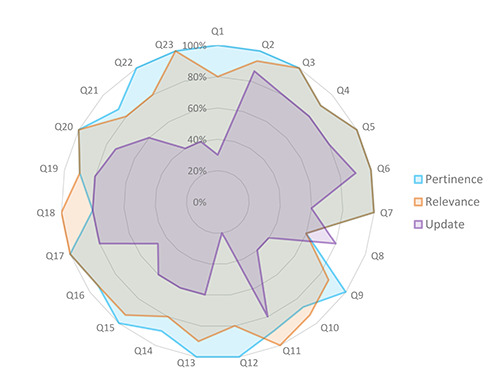
The large language model (LLM) ChatGPT can answer open-ended and complex questions, but its accuracy in providing reliable medical information requires a careful assessment. As part of the AI-CHECK (Artificial Intelligence for CME Health E-learning Contents and Knowledge) study, aimed at evaluating the potential of ChatGPT in continuous medical education (CME), we compared ChatGPT-generated educational content to the recommendations of the National Institute for Health and Care Excellence (NICE) guidelines on acne vulgaris. ChatGPT version 4 was exposed to a 23-item questionnaire developed by an experienced dermatologist. A panel of five dermatologists rated the answers positively in terms of "quality" (87.8%), "readability" (94.8%), "accuracy" (75.7%), "thoroughness" (85.2%), and "consistency" with guidelines (76.8%). The references provided by ChatGPT obtained positive ratings for "pertinence" (94.6%), "relevance" (91.2%), and "update" (62.3%). The internal reproducibility was adequate both for answers (93.5%) and references (67.4%). Answers related to issues of uncertainty and/or controversy in the scientific community scored the lowest. This study underscores the need to develop rigorous evaluation criteria for AI-generated medical content and for expert oversight to ensure accuracy and guideline adherence.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


