{"title":"利用包裹损失和神经网络减少年度数据漂移,增强PM2.5预测。","authors":"Md Khalid Hossen, Yan-Tsung Peng, Meng Chang Chen","doi":"10.1371/journal.pone.0314327","DOIUrl":null,"url":null,"abstract":"<p><p>In many deep learning tasks, it is assumed that the data used in the training process is sampled from the same distribution. However, this may not be accurate for data collected from different contexts or during different periods. For instance, the temperatures in a city can vary from year to year due to various unclear reasons. In this paper, we utilized three distinct statistical techniques to analyze annual data drifting at various stations. These techniques calculate the P values for each station by comparing data from five years (2014-2018) to identify data drifting phenomena. To find out the data drifting scenario those statistical techniques and calculate the P value from those techniques to measure the data drifting in specific locations. From those statistical techniques, the highest drifting stations can be identified from the previous year's datasets To identify data drifting and highlight areas with significant drift, we utilized meteorological air quality and weather data in this study. We proposed two models that consider the characteristics of data drifting for PM2.5 prediction and compared them with various deep learning models, such as Long Short-Term Memory (LSTM) and its variants, for predictions from the next hour to the 64th hour. Our proposed models significantly outperform traditional neural networks. Additionally, we introduced a wrapped loss function incorporated into a model, resulting in more accurate results compared to those using the original loss function alone and prediction has been evaluated by RMSE, MAE and MAPE metrics. The proposed Front-loaded connection model(FLC) and Back-loaded connection model (BLC) solve the data drifting issue and the wrap loss function also help alleviate the data drifting problem with model training and works for the neural network models to achieve more accurate results. Eventually, the experimental results have shown that the proposed model performance enhanced from 24.1% -16%, 12%-8.3% respectively at 1h-24h, 32h-64h with compared to baselines BILSTM model, by 24.6% -11.8%, 10%-10.2% respectively at 1h-24h, 32h-64h compared to CNN model in hourly PM2.5 predictions.</p>","PeriodicalId":20189,"journal":{"name":"PLoS ONE","volume":"20 2","pages":"e0314327"},"PeriodicalIF":2.6000,"publicationDate":"2025-02-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11813127/pdf/","citationCount":"0","resultStr":"{\"title\":\"Enhancing PM2.5 prediction by mitigating annual data drift using wrapped loss and neural networks.\",\"authors\":\"Md Khalid Hossen, Yan-Tsung Peng, Meng Chang Chen\",\"doi\":\"10.1371/journal.pone.0314327\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In many deep learning tasks, it is assumed that the data used in the training process is sampled from the same distribution. However, this may not be accurate for data collected from different contexts or during different periods. For instance, the temperatures in a city can vary from year to year due to various unclear reasons. In this paper, we utilized three distinct statistical techniques to analyze annual data drifting at various stations. These techniques calculate the P values for each station by comparing data from five years (2014-2018) to identify data drifting phenomena. To find out the data drifting scenario those statistical techniques and calculate the P value from those techniques to measure the data drifting in specific locations. From those statistical techniques, the highest drifting stations can be identified from the previous year's datasets To identify data drifting and highlight areas with significant drift, we utilized meteorological air quality and weather data in this study. We proposed two models that consider the characteristics of data drifting for PM2.5 prediction and compared them with various deep learning models, such as Long Short-Term Memory (LSTM) and its variants, for predictions from the next hour to the 64th hour. Our proposed models significantly outperform traditional neural networks. Additionally, we introduced a wrapped loss function incorporated into a model, resulting in more accurate results compared to those using the original loss function alone and prediction has been evaluated by RMSE, MAE and MAPE metrics. The proposed Front-loaded connection model(FLC) and Back-loaded connection model (BLC) solve the data drifting issue and the wrap loss function also help alleviate the data drifting problem with model training and works for the neural network models to achieve more accurate results. Eventually, the experimental results have shown that the proposed model performance enhanced from 24.1% -16%, 12%-8.3% respectively at 1h-24h, 32h-64h with compared to baselines BILSTM model, by 24.6% -11.8%, 10%-10.2% respectively at 1h-24h, 32h-64h compared to CNN model in hourly PM2.5 predictions.</p>\",\"PeriodicalId\":20189,\"journal\":{\"name\":\"PLoS ONE\",\"volume\":\"20 2\",\"pages\":\"e0314327\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2025-02-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11813127/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLoS ONE\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pone.0314327\",\"RegionNum\":3,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLoS ONE","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1371/journal.pone.0314327","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Enhancing PM2.5 prediction by mitigating annual data drift using wrapped loss and neural networks.
In many deep learning tasks, it is assumed that the data used in the training process is sampled from the same distribution. However, this may not be accurate for data collected from different contexts or during different periods. For instance, the temperatures in a city can vary from year to year due to various unclear reasons. In this paper, we utilized three distinct statistical techniques to analyze annual data drifting at various stations. These techniques calculate the P values for each station by comparing data from five years (2014-2018) to identify data drifting phenomena. To find out the data drifting scenario those statistical techniques and calculate the P value from those techniques to measure the data drifting in specific locations. From those statistical techniques, the highest drifting stations can be identified from the previous year's datasets To identify data drifting and highlight areas with significant drift, we utilized meteorological air quality and weather data in this study. We proposed two models that consider the characteristics of data drifting for PM2.5 prediction and compared them with various deep learning models, such as Long Short-Term Memory (LSTM) and its variants, for predictions from the next hour to the 64th hour. Our proposed models significantly outperform traditional neural networks. Additionally, we introduced a wrapped loss function incorporated into a model, resulting in more accurate results compared to those using the original loss function alone and prediction has been evaluated by RMSE, MAE and MAPE metrics. The proposed Front-loaded connection model(FLC) and Back-loaded connection model (BLC) solve the data drifting issue and the wrap loss function also help alleviate the data drifting problem with model training and works for the neural network models to achieve more accurate results. Eventually, the experimental results have shown that the proposed model performance enhanced from 24.1% -16%, 12%-8.3% respectively at 1h-24h, 32h-64h with compared to baselines BILSTM model, by 24.6% -11.8%, 10%-10.2% respectively at 1h-24h, 32h-64h compared to CNN model in hourly PM2.5 predictions.
期刊介绍:
PLOS ONE is an international, peer-reviewed, open-access, online publication. PLOS ONE welcomes reports on primary research from any scientific discipline. It provides:
* Open-access—freely accessible online, authors retain copyright
* Fast publication times
* Peer review by expert, practicing researchers
* Post-publication tools to indicate quality and impact
* Community-based dialogue on articles
* Worldwide media coverage
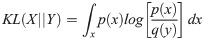
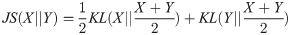
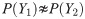

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


