{"title":"一种集成监督学习和无监督学习的推荐数据增强模型。","authors":"Jiaying Chen, Zhongrui Zhu, Haoyang Li, Wanlong Jiang, Gwanggil Jeon, Yurong Qian","doi":"10.1038/s41598-025-88858-9","DOIUrl":null,"url":null,"abstract":"<p><p>Recommendation models based on Graph Neural Networks (GNNs) are typically employed within a supervised learning paradigm. However, the label data is extremely sparse across the entire interaction space, hindering the model's ability to learn high-quality embedding representations. Data augmentation techniques can alleviate the overfitting problem caused by insufficient label data by generating additional training samples. Therefore, we fused supervised learning tasks with unsupervised learning tasks, and applied different data augmentation techniques to learn the generation process, proposing a new recommendation model (DARec). In supervised learning tasks, we leverage the powerful generative capability of diffusion models for data augmentation. In unsupervised learning tasks, we enhance the user-item interaction graph and the knowledge graph (KG) by employing edge dropout. Unlike existing data augmentation methods, DARec does not rely on traditional labeled data; instead, it generates supervisory signals from the input data itself to train the model. This approach enables the model to learn feature representations of the data without explicit labels, thereby leveraging a large amount of unlabeled data to enhance learning efficiency. Moreover, it endeavors to minimize damage to the original interaction matrix and graph structure as much as possible. Validation on three representative public datasets shows that our DARec model outperforms several state-of-the-art recommendation models.</p>","PeriodicalId":21811,"journal":{"name":"Scientific Reports","volume":"15 1","pages":"4862"},"PeriodicalIF":3.9000,"publicationDate":"2025-02-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11808110/pdf/","citationCount":"0","resultStr":"{\"title\":\"A data augmentation model integrating supervised and unsupervised learning for recommendation.\",\"authors\":\"Jiaying Chen, Zhongrui Zhu, Haoyang Li, Wanlong Jiang, Gwanggil Jeon, Yurong Qian\",\"doi\":\"10.1038/s41598-025-88858-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Recommendation models based on Graph Neural Networks (GNNs) are typically employed within a supervised learning paradigm. However, the label data is extremely sparse across the entire interaction space, hindering the model's ability to learn high-quality embedding representations. Data augmentation techniques can alleviate the overfitting problem caused by insufficient label data by generating additional training samples. Therefore, we fused supervised learning tasks with unsupervised learning tasks, and applied different data augmentation techniques to learn the generation process, proposing a new recommendation model (DARec). In supervised learning tasks, we leverage the powerful generative capability of diffusion models for data augmentation. In unsupervised learning tasks, we enhance the user-item interaction graph and the knowledge graph (KG) by employing edge dropout. Unlike existing data augmentation methods, DARec does not rely on traditional labeled data; instead, it generates supervisory signals from the input data itself to train the model. This approach enables the model to learn feature representations of the data without explicit labels, thereby leveraging a large amount of unlabeled data to enhance learning efficiency. Moreover, it endeavors to minimize damage to the original interaction matrix and graph structure as much as possible. Validation on three representative public datasets shows that our DARec model outperforms several state-of-the-art recommendation models.</p>\",\"PeriodicalId\":21811,\"journal\":{\"name\":\"Scientific Reports\",\"volume\":\"15 1\",\"pages\":\"4862\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-02-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11808110/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Reports\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41598-025-88858-9\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Reports","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41598-025-88858-9","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
A data augmentation model integrating supervised and unsupervised learning for recommendation.
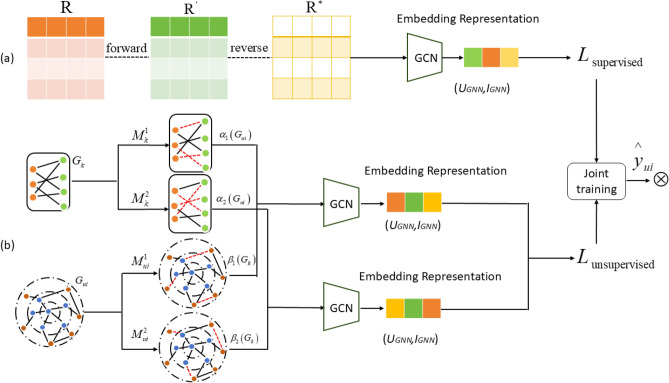
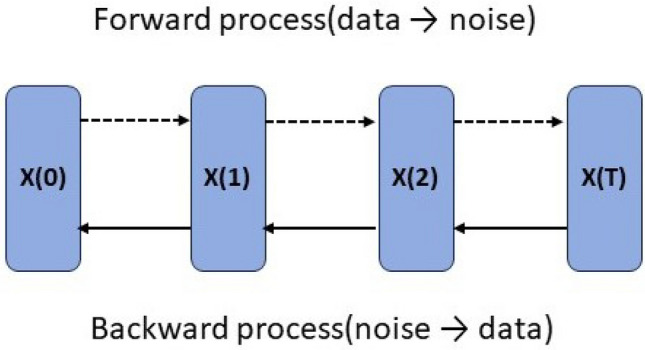
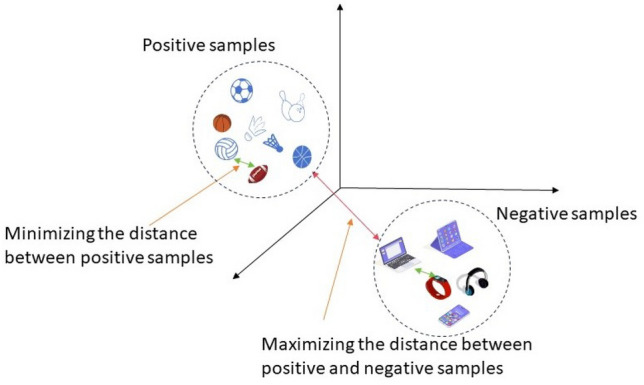
Recommendation models based on Graph Neural Networks (GNNs) are typically employed within a supervised learning paradigm. However, the label data is extremely sparse across the entire interaction space, hindering the model's ability to learn high-quality embedding representations. Data augmentation techniques can alleviate the overfitting problem caused by insufficient label data by generating additional training samples. Therefore, we fused supervised learning tasks with unsupervised learning tasks, and applied different data augmentation techniques to learn the generation process, proposing a new recommendation model (DARec). In supervised learning tasks, we leverage the powerful generative capability of diffusion models for data augmentation. In unsupervised learning tasks, we enhance the user-item interaction graph and the knowledge graph (KG) by employing edge dropout. Unlike existing data augmentation methods, DARec does not rely on traditional labeled data; instead, it generates supervisory signals from the input data itself to train the model. This approach enables the model to learn feature representations of the data without explicit labels, thereby leveraging a large amount of unlabeled data to enhance learning efficiency. Moreover, it endeavors to minimize damage to the original interaction matrix and graph structure as much as possible. Validation on three representative public datasets shows that our DARec model outperforms several state-of-the-art recommendation models.
期刊介绍:
We publish original research from all areas of the natural sciences, psychology, medicine and engineering. You can learn more about what we publish by browsing our specific scientific subject areas below or explore Scientific Reports by browsing all articles and collections.
Scientific Reports has a 2-year impact factor: 4.380 (2021), and is the 6th most-cited journal in the world, with more than 540,000 citations in 2020 (Clarivate Analytics, 2021).
•Engineering
Engineering covers all aspects of engineering, technology, and applied science. It plays a crucial role in the development of technologies to address some of the world''s biggest challenges, helping to save lives and improve the way we live.
•Physical sciences
Physical sciences are those academic disciplines that aim to uncover the underlying laws of nature — often written in the language of mathematics. It is a collective term for areas of study including astronomy, chemistry, materials science and physics.
•Earth and environmental sciences
Earth and environmental sciences cover all aspects of Earth and planetary science and broadly encompass solid Earth processes, surface and atmospheric dynamics, Earth system history, climate and climate change, marine and freshwater systems, and ecology. It also considers the interactions between humans and these systems.
•Biological sciences
Biological sciences encompass all the divisions of natural sciences examining various aspects of vital processes. The concept includes anatomy, physiology, cell biology, biochemistry and biophysics, and covers all organisms from microorganisms, animals to plants.
•Health sciences
The health sciences study health, disease and healthcare. This field of study aims to develop knowledge, interventions and technology for use in healthcare to improve the treatment of patients.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


