Maria Mahbub, Gregory M Dams, Sudarshan Srinivasan, Caitlin Rizy, Ioana Danciu, Jodie Trafton, Kathryn Knight
{"title":"使用大型语言模型从临床记录中解码物质使用障碍的严重程度。","authors":"Maria Mahbub, Gregory M Dams, Sudarshan Srinivasan, Caitlin Rizy, Ioana Danciu, Jodie Trafton, Kathryn Knight","doi":"10.1038/s44184-024-00114-6","DOIUrl":null,"url":null,"abstract":"<p><p>Substance use disorder (SUD) poses a major concern due to its detrimental effects on health and society. SUD identification and treatment depend on a variety of factors such as severity, co-determinants (e.g., withdrawal symptoms), and social determinants of health. Existing diagnostic coding systems used by insurance providers, like the International Classification of Diseases (ICD-10), lack granularity for certain diagnoses, but American clinicians will add this granularity (as that found within the Diagnostic and Statistical Manual of Mental Disorders classification or DSM-5) as supplemental unstructured text in clinical notes. Traditional natural language processing (NLP) methods face limitations in accurately parsing such diverse clinical language. Large language models (LLMs) offer promise in overcoming these challenges by adapting to diverse language patterns. This study investigates the application of LLMs for extracting severity-related information for various SUD diagnoses from clinical notes. We propose a workflow employing zero-shot learning of LLMs with carefully crafted prompts and post-processing techniques. Through experimentation with Flan-T5, an open-source LLM, we demonstrate its superior recall compared to the rule-based approach. Focusing on 11 categories of SUD diagnoses, we show the effectiveness of LLMs in extracting severity information, contributing to improved risk assessment and treatment planning for SUD patients.</p>","PeriodicalId":74321,"journal":{"name":"Npj mental health research","volume":"4 1","pages":"5"},"PeriodicalIF":0.0000,"publicationDate":"2025-02-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11802718/pdf/","citationCount":"0","resultStr":"{\"title\":\"Decoding substance use disorder severity from clinical notes using a large language model.\",\"authors\":\"Maria Mahbub, Gregory M Dams, Sudarshan Srinivasan, Caitlin Rizy, Ioana Danciu, Jodie Trafton, Kathryn Knight\",\"doi\":\"10.1038/s44184-024-00114-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Substance use disorder (SUD) poses a major concern due to its detrimental effects on health and society. SUD identification and treatment depend on a variety of factors such as severity, co-determinants (e.g., withdrawal symptoms), and social determinants of health. Existing diagnostic coding systems used by insurance providers, like the International Classification of Diseases (ICD-10), lack granularity for certain diagnoses, but American clinicians will add this granularity (as that found within the Diagnostic and Statistical Manual of Mental Disorders classification or DSM-5) as supplemental unstructured text in clinical notes. Traditional natural language processing (NLP) methods face limitations in accurately parsing such diverse clinical language. Large language models (LLMs) offer promise in overcoming these challenges by adapting to diverse language patterns. This study investigates the application of LLMs for extracting severity-related information for various SUD diagnoses from clinical notes. We propose a workflow employing zero-shot learning of LLMs with carefully crafted prompts and post-processing techniques. Through experimentation with Flan-T5, an open-source LLM, we demonstrate its superior recall compared to the rule-based approach. Focusing on 11 categories of SUD diagnoses, we show the effectiveness of LLMs in extracting severity information, contributing to improved risk assessment and treatment planning for SUD patients.</p>\",\"PeriodicalId\":74321,\"journal\":{\"name\":\"Npj mental health research\",\"volume\":\"4 1\",\"pages\":\"5\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-02-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11802718/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Npj mental health research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1038/s44184-024-00114-6\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Npj mental health research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1038/s44184-024-00114-6","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Decoding substance use disorder severity from clinical notes using a large language model.
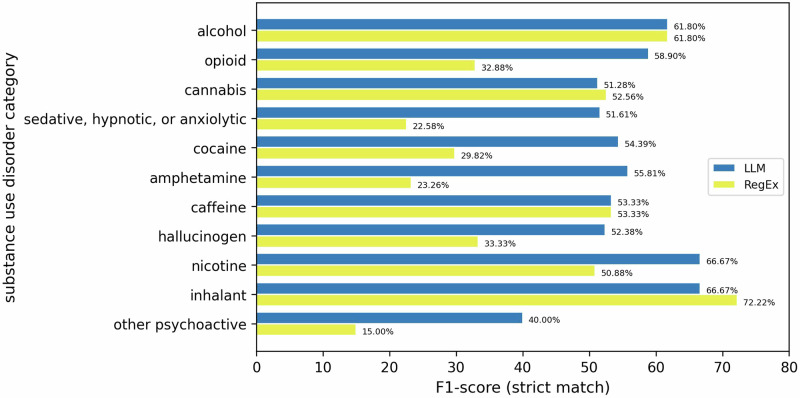
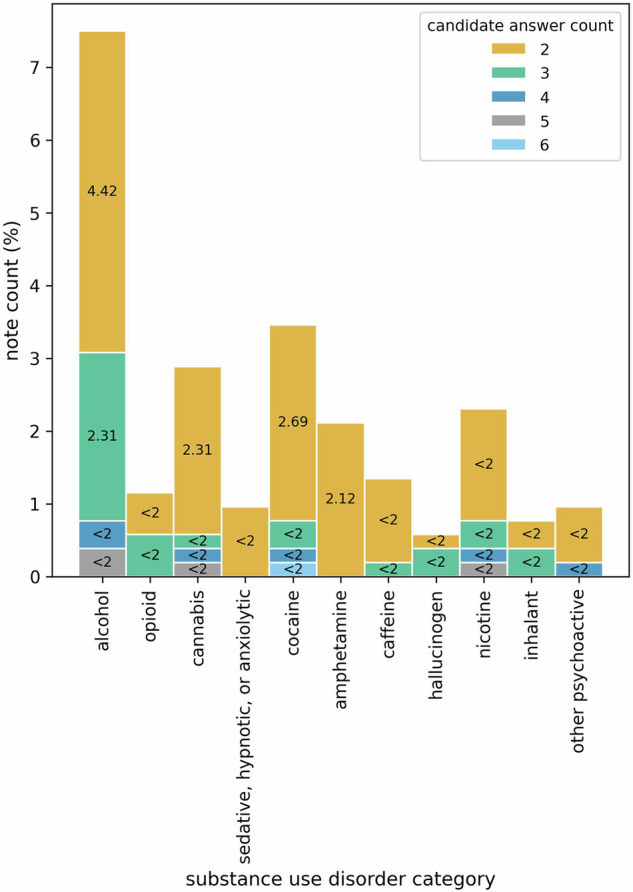
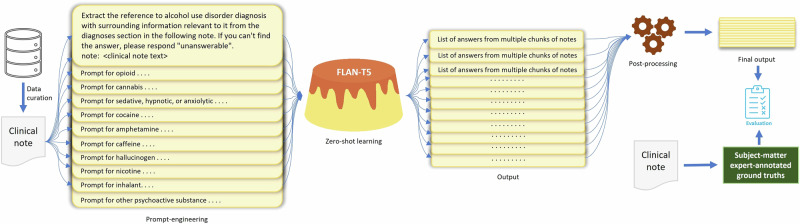
Substance use disorder (SUD) poses a major concern due to its detrimental effects on health and society. SUD identification and treatment depend on a variety of factors such as severity, co-determinants (e.g., withdrawal symptoms), and social determinants of health. Existing diagnostic coding systems used by insurance providers, like the International Classification of Diseases (ICD-10), lack granularity for certain diagnoses, but American clinicians will add this granularity (as that found within the Diagnostic and Statistical Manual of Mental Disorders classification or DSM-5) as supplemental unstructured text in clinical notes. Traditional natural language processing (NLP) methods face limitations in accurately parsing such diverse clinical language. Large language models (LLMs) offer promise in overcoming these challenges by adapting to diverse language patterns. This study investigates the application of LLMs for extracting severity-related information for various SUD diagnoses from clinical notes. We propose a workflow employing zero-shot learning of LLMs with carefully crafted prompts and post-processing techniques. Through experimentation with Flan-T5, an open-source LLM, we demonstrate its superior recall compared to the rule-based approach. Focusing on 11 categories of SUD diagnoses, we show the effectiveness of LLMs in extracting severity information, contributing to improved risk assessment and treatment planning for SUD patients.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


