Bernat Font, Francisco Alcántara-Ávila, Jean Rabault, Ricardo Vinuesa, Oriol Lehmkuhl
{"title":"湍流分离泡中主动流动控制的深度强化学习","authors":"Bernat Font, Francisco Alcántara-Ávila, Jean Rabault, Ricardo Vinuesa, Oriol Lehmkuhl","doi":"10.1038/s41467-025-56408-6","DOIUrl":null,"url":null,"abstract":"<p>The control efficacy of deep reinforcement learning (DRL) compared with classical periodic forcing is numerically assessed for a turbulent separation bubble (TSB). We show that a control strategy learned on a coarse grid works on a fine grid as long as the coarse grid captures main flow features. This allows to significantly reduce the computational cost of DRL training in a turbulent-flow environment. On the fine grid, the periodic control is able to reduce the TSB area by 6.8%, while the DRL-based control achieves 9.0% reduction. Furthermore, the DRL agent provides a smoother control strategy while conserving momentum instantaneously. The physical analysis of the DRL control strategy reveals the production of large-scale counter-rotating vortices by adjacent actuator pairs. It is shown that the DRL agent acts on a wide range of frequencies to sustain these vortices in time. Last, we also introduce our computational fluid dynamics and DRL open-source framework suited for the next generation of exascale computing machines.</p>","PeriodicalId":19066,"journal":{"name":"Nature Communications","volume":"140 1","pages":""},"PeriodicalIF":15.7000,"publicationDate":"2025-02-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Deep reinforcement learning for active flow control in a turbulent separation bubble\",\"authors\":\"Bernat Font, Francisco Alcántara-Ávila, Jean Rabault, Ricardo Vinuesa, Oriol Lehmkuhl\",\"doi\":\"10.1038/s41467-025-56408-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The control efficacy of deep reinforcement learning (DRL) compared with classical periodic forcing is numerically assessed for a turbulent separation bubble (TSB). We show that a control strategy learned on a coarse grid works on a fine grid as long as the coarse grid captures main flow features. This allows to significantly reduce the computational cost of DRL training in a turbulent-flow environment. On the fine grid, the periodic control is able to reduce the TSB area by 6.8%, while the DRL-based control achieves 9.0% reduction. Furthermore, the DRL agent provides a smoother control strategy while conserving momentum instantaneously. The physical analysis of the DRL control strategy reveals the production of large-scale counter-rotating vortices by adjacent actuator pairs. It is shown that the DRL agent acts on a wide range of frequencies to sustain these vortices in time. Last, we also introduce our computational fluid dynamics and DRL open-source framework suited for the next generation of exascale computing machines.</p>\",\"PeriodicalId\":19066,\"journal\":{\"name\":\"Nature Communications\",\"volume\":\"140 1\",\"pages\":\"\"},\"PeriodicalIF\":15.7000,\"publicationDate\":\"2025-02-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Communications\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41467-025-56408-6\",\"RegionNum\":1,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Communications","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41467-025-56408-6","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Deep reinforcement learning for active flow control in a turbulent separation bubble
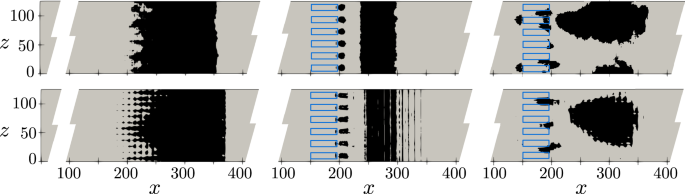
The control efficacy of deep reinforcement learning (DRL) compared with classical periodic forcing is numerically assessed for a turbulent separation bubble (TSB). We show that a control strategy learned on a coarse grid works on a fine grid as long as the coarse grid captures main flow features. This allows to significantly reduce the computational cost of DRL training in a turbulent-flow environment. On the fine grid, the periodic control is able to reduce the TSB area by 6.8%, while the DRL-based control achieves 9.0% reduction. Furthermore, the DRL agent provides a smoother control strategy while conserving momentum instantaneously. The physical analysis of the DRL control strategy reveals the production of large-scale counter-rotating vortices by adjacent actuator pairs. It is shown that the DRL agent acts on a wide range of frequencies to sustain these vortices in time. Last, we also introduce our computational fluid dynamics and DRL open-source framework suited for the next generation of exascale computing machines.
期刊介绍:
Nature Communications, an open-access journal, publishes high-quality research spanning all areas of the natural sciences. Papers featured in the journal showcase significant advances relevant to specialists in each respective field. With a 2-year impact factor of 16.6 (2022) and a median time of 8 days from submission to the first editorial decision, Nature Communications is committed to rapid dissemination of research findings. As a multidisciplinary journal, it welcomes contributions from biological, health, physical, chemical, Earth, social, mathematical, applied, and engineering sciences, aiming to highlight important breakthroughs within each domain.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


