{"title":"基于临床病例报告和图像识别,ChatGPT 3.5、4.0、4o 和 Gemini 在诊断口腔潜在恶性病变方面的准确性。","authors":"P Pradhan","doi":"10.4317/medoral.26824","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The accurate and timely diagnosis of oral potentially malignant lesions (OPMLs) is crucial for effective management and prevention of oral cancer. Recent advancements in artificial intelligence technologies indicates its potential to assist in clinical decision-making. Hence, this study was carried out with the aim to evaluate and compare the diagnostic accuracy of ChatGPT 3.5, 4.0, 4o and Gemini in identifying OPMLs.</p><p><strong>Material and methods: </strong>The analysis was carried out using 42 case reports from PubMed, Scopus and Google Scholar and images from two datasets, corresponding to different OPMLs. The reports were inputted separately for text description-based diagnosis in GPT 3.5, 4.0, 4o and Gemini, and for image recognition-based diagnosis in GPT 4o and Gemini. Two subject-matter experts independently reviewed the reports and offered their evaluations.</p><p><strong>Results: </strong>For text-based diagnosis, among LLMs, GPT 4o got the maximum number of correct responses (27/42), followed by GPT 4.0 (20/42), GPT 3.5 (18/42) and Gemini (15/42). In identifying OPMLs based on image, GPT 4o demonstrated better performance than Gemini. There was fair to moderate agreement found between Large Language Models (LLMs) and subject experts. None of the LLMs matched the accuracy of the subject experts in identifying the correct number of lesions.</p><p><strong>Conclusions: </strong>The results point towards cautious optimism with respect to commonly used LLMs in diagnosing OPMLs. While their potential in diagnostic applications is undeniable, their integration should be approached judiciously.</p>","PeriodicalId":49016,"journal":{"name":"Medicina Oral Patologia Oral Y Cirugia Bucal","volume":" ","pages":"e224-e231"},"PeriodicalIF":2.1000,"publicationDate":"2025-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11972639/pdf/","citationCount":"0","resultStr":"{\"title\":\"Accuracy of ChatGPT 3.5, 4.0, 4o and Gemini in diagnosing oral potentially malignant lesions based on clinical case reports and image recognition.\",\"authors\":\"P Pradhan\",\"doi\":\"10.4317/medoral.26824\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The accurate and timely diagnosis of oral potentially malignant lesions (OPMLs) is crucial for effective management and prevention of oral cancer. Recent advancements in artificial intelligence technologies indicates its potential to assist in clinical decision-making. Hence, this study was carried out with the aim to evaluate and compare the diagnostic accuracy of ChatGPT 3.5, 4.0, 4o and Gemini in identifying OPMLs.</p><p><strong>Material and methods: </strong>The analysis was carried out using 42 case reports from PubMed, Scopus and Google Scholar and images from two datasets, corresponding to different OPMLs. The reports were inputted separately for text description-based diagnosis in GPT 3.5, 4.0, 4o and Gemini, and for image recognition-based diagnosis in GPT 4o and Gemini. Two subject-matter experts independently reviewed the reports and offered their evaluations.</p><p><strong>Results: </strong>For text-based diagnosis, among LLMs, GPT 4o got the maximum number of correct responses (27/42), followed by GPT 4.0 (20/42), GPT 3.5 (18/42) and Gemini (15/42). In identifying OPMLs based on image, GPT 4o demonstrated better performance than Gemini. There was fair to moderate agreement found between Large Language Models (LLMs) and subject experts. None of the LLMs matched the accuracy of the subject experts in identifying the correct number of lesions.</p><p><strong>Conclusions: </strong>The results point towards cautious optimism with respect to commonly used LLMs in diagnosing OPMLs. While their potential in diagnostic applications is undeniable, their integration should be approached judiciously.</p>\",\"PeriodicalId\":49016,\"journal\":{\"name\":\"Medicina Oral Patologia Oral Y Cirugia Bucal\",\"volume\":\" \",\"pages\":\"e224-e231\"},\"PeriodicalIF\":2.1000,\"publicationDate\":\"2025-03-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11972639/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Medicina Oral Patologia Oral Y Cirugia Bucal\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.4317/medoral.26824\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"DENTISTRY, ORAL SURGERY & MEDICINE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medicina Oral Patologia Oral Y Cirugia Bucal","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.4317/medoral.26824","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"DENTISTRY, ORAL SURGERY & MEDICINE","Score":null,"Total":0}
Accuracy of ChatGPT 3.5, 4.0, 4o and Gemini in diagnosing oral potentially malignant lesions based on clinical case reports and image recognition.
Background: The accurate and timely diagnosis of oral potentially malignant lesions (OPMLs) is crucial for effective management and prevention of oral cancer. Recent advancements in artificial intelligence technologies indicates its potential to assist in clinical decision-making. Hence, this study was carried out with the aim to evaluate and compare the diagnostic accuracy of ChatGPT 3.5, 4.0, 4o and Gemini in identifying OPMLs.
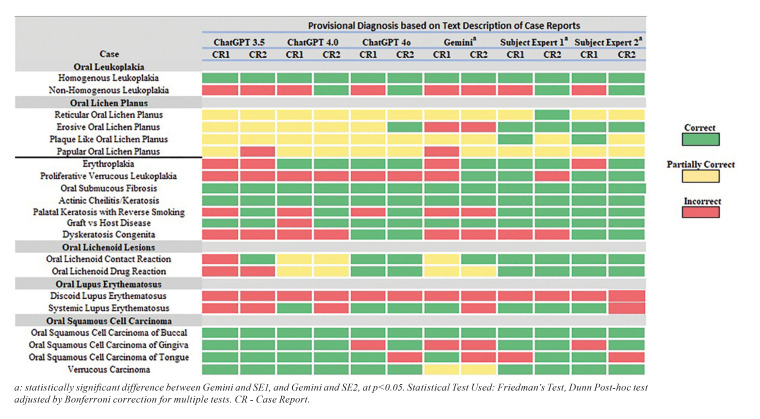
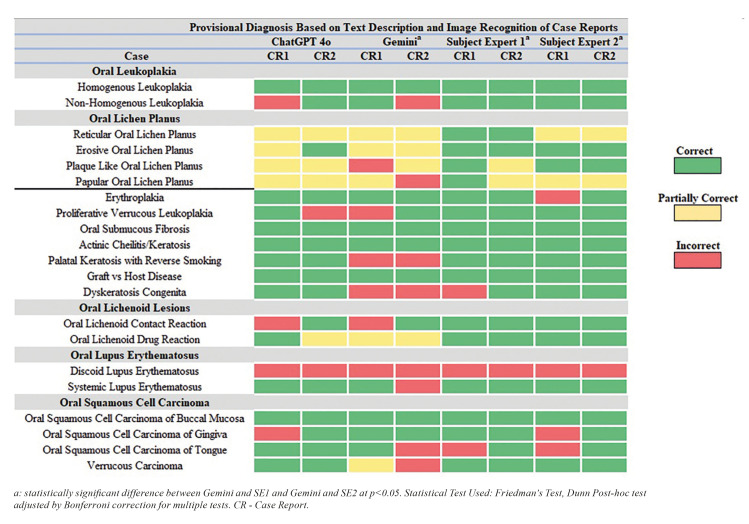
Material and methods: The analysis was carried out using 42 case reports from PubMed, Scopus and Google Scholar and images from two datasets, corresponding to different OPMLs. The reports were inputted separately for text description-based diagnosis in GPT 3.5, 4.0, 4o and Gemini, and for image recognition-based diagnosis in GPT 4o and Gemini. Two subject-matter experts independently reviewed the reports and offered their evaluations.
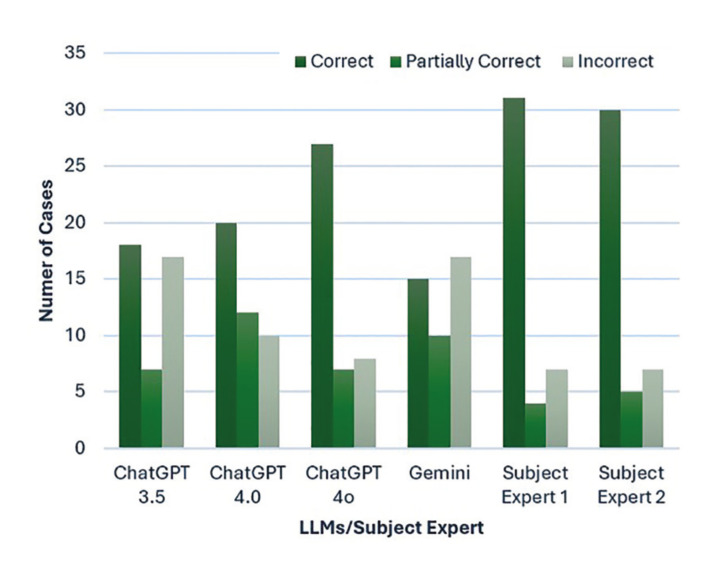
Results: For text-based diagnosis, among LLMs, GPT 4o got the maximum number of correct responses (27/42), followed by GPT 4.0 (20/42), GPT 3.5 (18/42) and Gemini (15/42). In identifying OPMLs based on image, GPT 4o demonstrated better performance than Gemini. There was fair to moderate agreement found between Large Language Models (LLMs) and subject experts. None of the LLMs matched the accuracy of the subject experts in identifying the correct number of lesions.
Conclusions: The results point towards cautious optimism with respect to commonly used LLMs in diagnosing OPMLs. While their potential in diagnostic applications is undeniable, their integration should be approached judiciously.
期刊介绍:
1. Oral Medicine and Pathology:
Clinicopathological as well as medical or surgical management aspects of
diseases affecting oral mucosa, salivary glands, maxillary bones, as well as
orofacial neurological disorders, and systemic conditions with an impact on
the oral cavity.
2. Oral Surgery:
Surgical management aspects of diseases affecting oral mucosa, salivary glands,
maxillary bones, teeth, implants, oral surgical procedures. Surgical management
of diseases affecting head and neck areas.
3. Medically compromised patients in Dentistry:
Articles discussing medical problems in Odontology will also be included, with
a special focus on the clinico-odontological management of medically compromised patients, and considerations regarding high-risk or disabled patients.
4. Implantology
5. Periodontology

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


