R. Aiudi, R. Pacelli, P. Baglioni, A. Vezzani, R. Burioni, P. Rotondo
{"title":"局部核重整化作为一种超参数化卷积神经网络特征学习机制","authors":"R. Aiudi, R. Pacelli, P. Baglioni, A. Vezzani, R. Burioni, P. Rotondo","doi":"10.1038/s41467-024-55229-3","DOIUrl":null,"url":null,"abstract":"<p>Empirical evidence shows that fully-connected neural networks in the infinite-width limit (lazy training) eventually outperform their finite-width counterparts in most computer vision tasks; on the other hand, modern architectures with convolutional layers often achieve optimal performances in the finite-width regime. In this work, we present a theoretical framework that provides a rationale for these differences in one-hidden-layer networks; we derive an effective action in the so-called proportional limit for an architecture with one convolutional hidden layer and compare it with the result available for fully-connected networks. Remarkably, we identify a completely different form of kernel renormalization: whereas the kernel of the fully-connected architecture is just globally renormalized by a single scalar parameter, the convolutional kernel undergoes a local renormalization, meaning that the network can select the local components that will contribute to the final prediction in a data-dependent way. This finding highlights a simple mechanism for feature learning that can take place in overparametrized shallow convolutional neural networks, but not in shallow fully-connected architectures or in locally connected neural networks without weight sharing.</p>","PeriodicalId":19066,"journal":{"name":"Nature Communications","volume":"91 1","pages":""},"PeriodicalIF":14.7000,"publicationDate":"2025-01-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Local kernel renormalization as a mechanism for feature learning in overparametrized convolutional neural networks\",\"authors\":\"R. Aiudi, R. Pacelli, P. Baglioni, A. Vezzani, R. Burioni, P. Rotondo\",\"doi\":\"10.1038/s41467-024-55229-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Empirical evidence shows that fully-connected neural networks in the infinite-width limit (lazy training) eventually outperform their finite-width counterparts in most computer vision tasks; on the other hand, modern architectures with convolutional layers often achieve optimal performances in the finite-width regime. In this work, we present a theoretical framework that provides a rationale for these differences in one-hidden-layer networks; we derive an effective action in the so-called proportional limit for an architecture with one convolutional hidden layer and compare it with the result available for fully-connected networks. Remarkably, we identify a completely different form of kernel renormalization: whereas the kernel of the fully-connected architecture is just globally renormalized by a single scalar parameter, the convolutional kernel undergoes a local renormalization, meaning that the network can select the local components that will contribute to the final prediction in a data-dependent way. This finding highlights a simple mechanism for feature learning that can take place in overparametrized shallow convolutional neural networks, but not in shallow fully-connected architectures or in locally connected neural networks without weight sharing.</p>\",\"PeriodicalId\":19066,\"journal\":{\"name\":\"Nature Communications\",\"volume\":\"91 1\",\"pages\":\"\"},\"PeriodicalIF\":14.7000,\"publicationDate\":\"2025-01-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Communications\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41467-024-55229-3\",\"RegionNum\":1,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Communications","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41467-024-55229-3","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
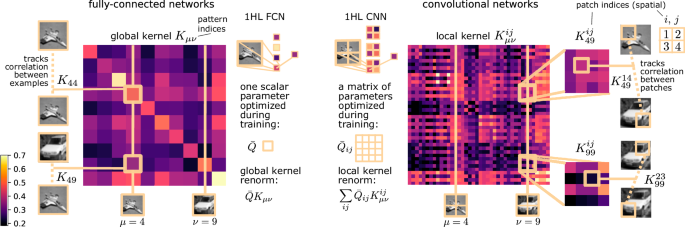
Local kernel renormalization as a mechanism for feature learning in overparametrized convolutional neural networks
Empirical evidence shows that fully-connected neural networks in the infinite-width limit (lazy training) eventually outperform their finite-width counterparts in most computer vision tasks; on the other hand, modern architectures with convolutional layers often achieve optimal performances in the finite-width regime. In this work, we present a theoretical framework that provides a rationale for these differences in one-hidden-layer networks; we derive an effective action in the so-called proportional limit for an architecture with one convolutional hidden layer and compare it with the result available for fully-connected networks. Remarkably, we identify a completely different form of kernel renormalization: whereas the kernel of the fully-connected architecture is just globally renormalized by a single scalar parameter, the convolutional kernel undergoes a local renormalization, meaning that the network can select the local components that will contribute to the final prediction in a data-dependent way. This finding highlights a simple mechanism for feature learning that can take place in overparametrized shallow convolutional neural networks, but not in shallow fully-connected architectures or in locally connected neural networks without weight sharing.
期刊介绍:
Nature Communications, an open-access journal, publishes high-quality research spanning all areas of the natural sciences. Papers featured in the journal showcase significant advances relevant to specialists in each respective field. With a 2-year impact factor of 16.6 (2022) and a median time of 8 days from submission to the first editorial decision, Nature Communications is committed to rapid dissemination of research findings. As a multidisciplinary journal, it welcomes contributions from biological, health, physical, chemical, Earth, social, mathematical, applied, and engineering sciences, aiming to highlight important breakthroughs within each domain.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


