Daniel Alexander Alber, Zihao Yang, Anton Alyakin, Eunice Yang, Sumedha Rai, Aly A. Valliani, Jeff Zhang, Gabriel R. Rosenbaum, Ashley K. Amend-Thomas, David B. Kurland, Caroline M. Kremer, Alexander Eremiev, Bruck Negash, Daniel D. Wiggan, Michelle A. Nakatsuka, Karl L. Sangwon, Sean N. Neifert, Hammad A. Khan, Akshay Vinod Save, Adhith Palla, Eric A. Grin, Monika Hedman, Mustafa Nasir-Moin, Xujin Chris Liu, Lavender Yao Jiang, Michal A. Mankowski, Dorry L. Segev, Yindalon Aphinyanaphongs, Howard A. Riina, John G. Golfinos, Daniel A. Orringer, Douglas Kondziolka, Eric Karl Oermann
{"title":"医学大型语言模型容易受到数据中毒攻击","authors":"Daniel Alexander Alber, Zihao Yang, Anton Alyakin, Eunice Yang, Sumedha Rai, Aly A. Valliani, Jeff Zhang, Gabriel R. Rosenbaum, Ashley K. Amend-Thomas, David B. Kurland, Caroline M. Kremer, Alexander Eremiev, Bruck Negash, Daniel D. Wiggan, Michelle A. Nakatsuka, Karl L. Sangwon, Sean N. Neifert, Hammad A. Khan, Akshay Vinod Save, Adhith Palla, Eric A. Grin, Monika Hedman, Mustafa Nasir-Moin, Xujin Chris Liu, Lavender Yao Jiang, Michal A. Mankowski, Dorry L. Segev, Yindalon Aphinyanaphongs, Howard A. Riina, John G. Golfinos, Daniel A. Orringer, Douglas Kondziolka, Eric Karl Oermann","doi":"10.1038/s41591-024-03445-1","DOIUrl":null,"url":null,"abstract":"<p>The adoption of large language models (LLMs) in healthcare demands a careful analysis of their potential to spread false medical knowledge. Because LLMs ingest massive volumes of data from the open Internet during training, they are potentially exposed to unverified medical knowledge that may include deliberately planted misinformation. Here, we perform a threat assessment that simulates a data-poisoning attack against The Pile, a popular dataset used for LLM development. We find that replacement of just 0.001% of training tokens with medical misinformation results in harmful models more likely to propagate medical errors. Furthermore, we discover that corrupted models match the performance of their corruption-free counterparts on open-source benchmarks routinely used to evaluate medical LLMs. Using biomedical knowledge graphs to screen medical LLM outputs, we propose a harm mitigation strategy that captures 91.9% of harmful content (F1 = 85.7%). Our algorithm provides a unique method to validate stochastically generated LLM outputs against hard-coded relationships in knowledge graphs. In view of current calls for improved data provenance and transparent LLM development, we hope to raise awareness of emergent risks from LLMs trained indiscriminately on web-scraped data, particularly in healthcare where misinformation can potentially compromise patient safety.</p>","PeriodicalId":19037,"journal":{"name":"Nature Medicine","volume":"28 1","pages":""},"PeriodicalIF":58.7000,"publicationDate":"2025-01-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Medical large language models are vulnerable to data-poisoning attacks\",\"authors\":\"Daniel Alexander Alber, Zihao Yang, Anton Alyakin, Eunice Yang, Sumedha Rai, Aly A. Valliani, Jeff Zhang, Gabriel R. Rosenbaum, Ashley K. Amend-Thomas, David B. Kurland, Caroline M. Kremer, Alexander Eremiev, Bruck Negash, Daniel D. Wiggan, Michelle A. Nakatsuka, Karl L. Sangwon, Sean N. Neifert, Hammad A. Khan, Akshay Vinod Save, Adhith Palla, Eric A. Grin, Monika Hedman, Mustafa Nasir-Moin, Xujin Chris Liu, Lavender Yao Jiang, Michal A. Mankowski, Dorry L. Segev, Yindalon Aphinyanaphongs, Howard A. Riina, John G. Golfinos, Daniel A. Orringer, Douglas Kondziolka, Eric Karl Oermann\",\"doi\":\"10.1038/s41591-024-03445-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The adoption of large language models (LLMs) in healthcare demands a careful analysis of their potential to spread false medical knowledge. Because LLMs ingest massive volumes of data from the open Internet during training, they are potentially exposed to unverified medical knowledge that may include deliberately planted misinformation. Here, we perform a threat assessment that simulates a data-poisoning attack against The Pile, a popular dataset used for LLM development. We find that replacement of just 0.001% of training tokens with medical misinformation results in harmful models more likely to propagate medical errors. Furthermore, we discover that corrupted models match the performance of their corruption-free counterparts on open-source benchmarks routinely used to evaluate medical LLMs. Using biomedical knowledge graphs to screen medical LLM outputs, we propose a harm mitigation strategy that captures 91.9% of harmful content (F1 = 85.7%). Our algorithm provides a unique method to validate stochastically generated LLM outputs against hard-coded relationships in knowledge graphs. In view of current calls for improved data provenance and transparent LLM development, we hope to raise awareness of emergent risks from LLMs trained indiscriminately on web-scraped data, particularly in healthcare where misinformation can potentially compromise patient safety.</p>\",\"PeriodicalId\":19037,\"journal\":{\"name\":\"Nature Medicine\",\"volume\":\"28 1\",\"pages\":\"\"},\"PeriodicalIF\":58.7000,\"publicationDate\":\"2025-01-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1038/s41591-024-03445-1\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1038/s41591-024-03445-1","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
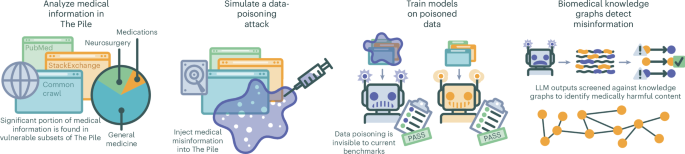
Medical large language models are vulnerable to data-poisoning attacks
The adoption of large language models (LLMs) in healthcare demands a careful analysis of their potential to spread false medical knowledge. Because LLMs ingest massive volumes of data from the open Internet during training, they are potentially exposed to unverified medical knowledge that may include deliberately planted misinformation. Here, we perform a threat assessment that simulates a data-poisoning attack against The Pile, a popular dataset used for LLM development. We find that replacement of just 0.001% of training tokens with medical misinformation results in harmful models more likely to propagate medical errors. Furthermore, we discover that corrupted models match the performance of their corruption-free counterparts on open-source benchmarks routinely used to evaluate medical LLMs. Using biomedical knowledge graphs to screen medical LLM outputs, we propose a harm mitigation strategy that captures 91.9% of harmful content (F1 = 85.7%). Our algorithm provides a unique method to validate stochastically generated LLM outputs against hard-coded relationships in knowledge graphs. In view of current calls for improved data provenance and transparent LLM development, we hope to raise awareness of emergent risks from LLMs trained indiscriminately on web-scraped data, particularly in healthcare where misinformation can potentially compromise patient safety.
期刊介绍:
Nature Medicine is a monthly journal publishing original peer-reviewed research in all areas of medicine. The publication focuses on originality, timeliness, interdisciplinary interest, and the impact on improving human health. In addition to research articles, Nature Medicine also publishes commissioned content such as News, Reviews, and Perspectives. This content aims to provide context for the latest advances in translational and clinical research, reaching a wide audience of M.D. and Ph.D. readers. All editorial decisions for the journal are made by a team of full-time professional editors.
Nature Medicine consider all types of clinical research, including:
-Case-reports and small case series
-Clinical trials, whether phase 1, 2, 3 or 4
-Observational studies
-Meta-analyses
-Biomarker studies
-Public and global health studies
Nature Medicine is also committed to facilitating communication between translational and clinical researchers. As such, we consider “hybrid” studies with preclinical and translational findings reported alongside data from clinical studies.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


