Andrés Lozano, Enrique Nava, María Dolores García Méndez, Ignacio Moreno-Torres
{"title":"用mfccc和卷积神经网络计算平衡。","authors":"Andrés Lozano, Enrique Nava, María Dolores García Méndez, Ignacio Moreno-Torres","doi":"10.1371/journal.pone.0315452","DOIUrl":null,"url":null,"abstract":"<p><p>Nasalance is a valuable clinical biomarker for hypernasality. It is computed as the ratio of acoustic energy emitted through the nose to the total energy emitted through the mouth and nose (eNasalance). A new approach is proposed to compute nasalance using Convolutional Neural Networks (CNNs) trained with Mel-Frequency Cepstrum Coefficients (mfccNasalance). mfccNasalance is evaluated by examining its accuracy: 1) when the train and test data are from the same or from different dialects; 2) with test data that differs in dynamicity (e.g. rapidly produced diadochokinetic syllables versus short words); and 3) using multiple CNN configurations (i.e. kernel shape and use of 1 × 1 pointwise convolution). Dual-channel Nasometer speech data from healthy speakers from different dialects: Costa Rica, more(+) nasal, Spain and Chile, less(-) nasal, are recorded. The input to the CNN models were sequences of 39 MFCC vectors computed from 250 ms moving windows. The test data were recorded in Spain and included short words (-dynamic), sentences (+dynamic), and diadochokinetic syllables (+dynamic). The accuracy of a CNN model was defined as the Spearman correlation between the mfccNasalance for that model and the perceptual nasality scores of human experts. In the same-dialect condition, mfccNasalance was more accurate than eNasalance independently of the CNN configuration; using a 1 × 1 kernel resulted in increased accuracy for +dynamic utterances (p < .000), though not for -dynamic utterances. The kernel shape had a significant impact for -dynamic utterances (p < .000) exclusively. In the different-dialect condition, the scores were significantly less accurate than in the same-dialect condition, particularly for Costa Rica trained models. We conclude that mfccNasalance is a flexible and useful alternative to eNasalance. Future studies should explore how to optimize mfccNasalance by selecting the most adequate CNN model as a function of the dynamicity of the target speech data.</p>","PeriodicalId":20189,"journal":{"name":"PLoS ONE","volume":"19 12","pages":"e0315452"},"PeriodicalIF":2.6000,"publicationDate":"2024-12-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11687758/pdf/","citationCount":"0","resultStr":"{\"title\":\"Computing nasalance with MFCCs and Convolutional Neural Networks.\",\"authors\":\"Andrés Lozano, Enrique Nava, María Dolores García Méndez, Ignacio Moreno-Torres\",\"doi\":\"10.1371/journal.pone.0315452\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Nasalance is a valuable clinical biomarker for hypernasality. It is computed as the ratio of acoustic energy emitted through the nose to the total energy emitted through the mouth and nose (eNasalance). A new approach is proposed to compute nasalance using Convolutional Neural Networks (CNNs) trained with Mel-Frequency Cepstrum Coefficients (mfccNasalance). mfccNasalance is evaluated by examining its accuracy: 1) when the train and test data are from the same or from different dialects; 2) with test data that differs in dynamicity (e.g. rapidly produced diadochokinetic syllables versus short words); and 3) using multiple CNN configurations (i.e. kernel shape and use of 1 × 1 pointwise convolution). Dual-channel Nasometer speech data from healthy speakers from different dialects: Costa Rica, more(+) nasal, Spain and Chile, less(-) nasal, are recorded. The input to the CNN models were sequences of 39 MFCC vectors computed from 250 ms moving windows. The test data were recorded in Spain and included short words (-dynamic), sentences (+dynamic), and diadochokinetic syllables (+dynamic). The accuracy of a CNN model was defined as the Spearman correlation between the mfccNasalance for that model and the perceptual nasality scores of human experts. In the same-dialect condition, mfccNasalance was more accurate than eNasalance independently of the CNN configuration; using a 1 × 1 kernel resulted in increased accuracy for +dynamic utterances (p < .000), though not for -dynamic utterances. The kernel shape had a significant impact for -dynamic utterances (p < .000) exclusively. In the different-dialect condition, the scores were significantly less accurate than in the same-dialect condition, particularly for Costa Rica trained models. We conclude that mfccNasalance is a flexible and useful alternative to eNasalance. Future studies should explore how to optimize mfccNasalance by selecting the most adequate CNN model as a function of the dynamicity of the target speech data.</p>\",\"PeriodicalId\":20189,\"journal\":{\"name\":\"PLoS ONE\",\"volume\":\"19 12\",\"pages\":\"e0315452\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2024-12-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11687758/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLoS ONE\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pone.0315452\",\"RegionNum\":3,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLoS ONE","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1371/journal.pone.0315452","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Computing nasalance with MFCCs and Convolutional Neural Networks.
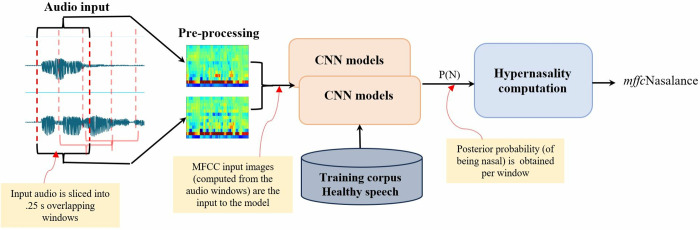
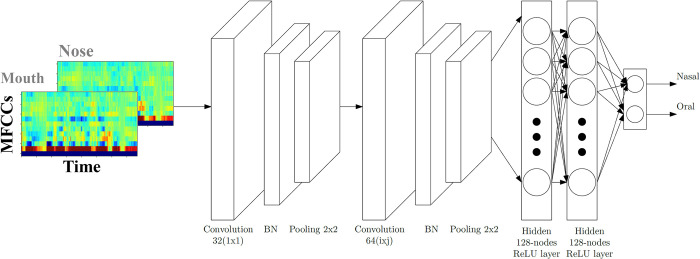
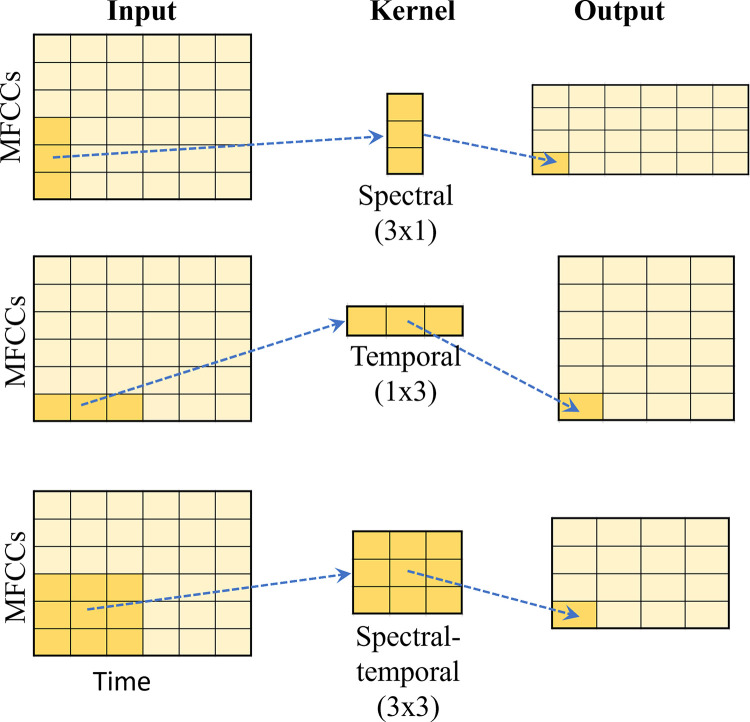
Nasalance is a valuable clinical biomarker for hypernasality. It is computed as the ratio of acoustic energy emitted through the nose to the total energy emitted through the mouth and nose (eNasalance). A new approach is proposed to compute nasalance using Convolutional Neural Networks (CNNs) trained with Mel-Frequency Cepstrum Coefficients (mfccNasalance). mfccNasalance is evaluated by examining its accuracy: 1) when the train and test data are from the same or from different dialects; 2) with test data that differs in dynamicity (e.g. rapidly produced diadochokinetic syllables versus short words); and 3) using multiple CNN configurations (i.e. kernel shape and use of 1 × 1 pointwise convolution). Dual-channel Nasometer speech data from healthy speakers from different dialects: Costa Rica, more(+) nasal, Spain and Chile, less(-) nasal, are recorded. The input to the CNN models were sequences of 39 MFCC vectors computed from 250 ms moving windows. The test data were recorded in Spain and included short words (-dynamic), sentences (+dynamic), and diadochokinetic syllables (+dynamic). The accuracy of a CNN model was defined as the Spearman correlation between the mfccNasalance for that model and the perceptual nasality scores of human experts. In the same-dialect condition, mfccNasalance was more accurate than eNasalance independently of the CNN configuration; using a 1 × 1 kernel resulted in increased accuracy for +dynamic utterances (p < .000), though not for -dynamic utterances. The kernel shape had a significant impact for -dynamic utterances (p < .000) exclusively. In the different-dialect condition, the scores were significantly less accurate than in the same-dialect condition, particularly for Costa Rica trained models. We conclude that mfccNasalance is a flexible and useful alternative to eNasalance. Future studies should explore how to optimize mfccNasalance by selecting the most adequate CNN model as a function of the dynamicity of the target speech data.
期刊介绍:
PLOS ONE is an international, peer-reviewed, open-access, online publication. PLOS ONE welcomes reports on primary research from any scientific discipline. It provides:
* Open-access—freely accessible online, authors retain copyright
* Fast publication times
* Peer review by expert, practicing researchers
* Post-publication tools to indicate quality and impact
* Community-based dialogue on articles
* Worldwide media coverage

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


