Janaína Mendes-Laureano, Jorge A Gómez-García, Alejandro Guerrero-López, Elisa Luque-Buzo, Julián D Arias-Londoño, Francisco J Grandas-Pérez, Juan I Godino-Llorente
{"title":"一个卡斯蒂利亚语的帕金森氏语言语料库。","authors":"Janaína Mendes-Laureano, Jorge A Gómez-García, Alejandro Guerrero-López, Elisa Luque-Buzo, Julián D Arias-Londoño, Francisco J Grandas-Pérez, Juan I Godino-Llorente","doi":"10.1038/s41597-024-04186-z","DOIUrl":null,"url":null,"abstract":"<p><p>The screening of Parkinson's Disease (PD) through speech is hindered by a notable lack of publicly available datasets in different languages. This fact limits the reproducibility and further exploration of existing research. To address this gap, this manuscript presents the NeuroVoz corpus consisting of 112 native Castilian-Spanish speakers, including 58 healthy controls and 54 individuals with PD, all recorded in ON state. The corpus showcases a diverse array of speech tasks: sustained vowels; diadochokinetic tests; 16 Listen-and-Repeat utterances; and spontaneous monologues. The dataset is also complemented with subjective assessments of voice quality performed by an expert according to the GRBAS scale (Grade/Roughness/Breathiness/Asthenia/Strain), as well as annotations with a thorough examination of phonation quality, intensity, speed, resonance, intelligibility, and prosody. The corpus offers a substantial resource for the exploration of the impact of PD on speech. This data set has already supported several studies, achieving a benchmark accuracy of 89% for the screening of PD. Despite these advances, the broader challenge of conducting a language-agnostic, cross-corpora analysis of Parkinsonian speech patterns remains open.</p>","PeriodicalId":21597,"journal":{"name":"Scientific Data","volume":"11 1","pages":"1367"},"PeriodicalIF":6.9000,"publicationDate":"2024-12-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11655668/pdf/","citationCount":"0","resultStr":"{\"title\":\"NeuroVoz: a Castillian Spanish corpus of parkinsonian speech.\",\"authors\":\"Janaína Mendes-Laureano, Jorge A Gómez-García, Alejandro Guerrero-López, Elisa Luque-Buzo, Julián D Arias-Londoño, Francisco J Grandas-Pérez, Juan I Godino-Llorente\",\"doi\":\"10.1038/s41597-024-04186-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The screening of Parkinson's Disease (PD) through speech is hindered by a notable lack of publicly available datasets in different languages. This fact limits the reproducibility and further exploration of existing research. To address this gap, this manuscript presents the NeuroVoz corpus consisting of 112 native Castilian-Spanish speakers, including 58 healthy controls and 54 individuals with PD, all recorded in ON state. The corpus showcases a diverse array of speech tasks: sustained vowels; diadochokinetic tests; 16 Listen-and-Repeat utterances; and spontaneous monologues. The dataset is also complemented with subjective assessments of voice quality performed by an expert according to the GRBAS scale (Grade/Roughness/Breathiness/Asthenia/Strain), as well as annotations with a thorough examination of phonation quality, intensity, speed, resonance, intelligibility, and prosody. The corpus offers a substantial resource for the exploration of the impact of PD on speech. This data set has already supported several studies, achieving a benchmark accuracy of 89% for the screening of PD. Despite these advances, the broader challenge of conducting a language-agnostic, cross-corpora analysis of Parkinsonian speech patterns remains open.</p>\",\"PeriodicalId\":21597,\"journal\":{\"name\":\"Scientific Data\",\"volume\":\"11 1\",\"pages\":\"1367\"},\"PeriodicalIF\":6.9000,\"publicationDate\":\"2024-12-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11655668/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Scientific Data\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41597-024-04186-z\",\"RegionNum\":2,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Data","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41597-024-04186-z","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
NeuroVoz: a Castillian Spanish corpus of parkinsonian speech.
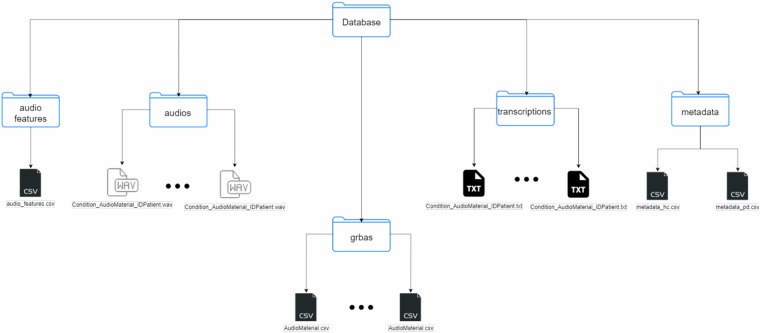
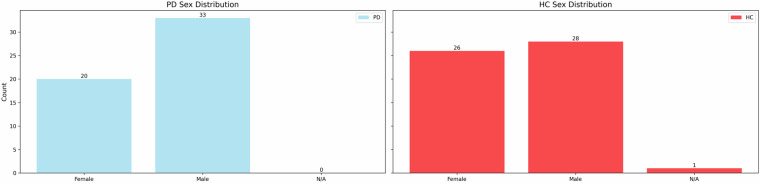
The screening of Parkinson's Disease (PD) through speech is hindered by a notable lack of publicly available datasets in different languages. This fact limits the reproducibility and further exploration of existing research. To address this gap, this manuscript presents the NeuroVoz corpus consisting of 112 native Castilian-Spanish speakers, including 58 healthy controls and 54 individuals with PD, all recorded in ON state. The corpus showcases a diverse array of speech tasks: sustained vowels; diadochokinetic tests; 16 Listen-and-Repeat utterances; and spontaneous monologues. The dataset is also complemented with subjective assessments of voice quality performed by an expert according to the GRBAS scale (Grade/Roughness/Breathiness/Asthenia/Strain), as well as annotations with a thorough examination of phonation quality, intensity, speed, resonance, intelligibility, and prosody. The corpus offers a substantial resource for the exploration of the impact of PD on speech. This data set has already supported several studies, achieving a benchmark accuracy of 89% for the screening of PD. Despite these advances, the broader challenge of conducting a language-agnostic, cross-corpora analysis of Parkinsonian speech patterns remains open.
期刊介绍:
Scientific Data is an open-access journal focused on data, publishing descriptions of research datasets and articles on data sharing across natural sciences, medicine, engineering, and social sciences. Its goal is to enhance the sharing and reuse of scientific data, encourage broader data sharing, and acknowledge those who share their data.
The journal primarily publishes Data Descriptors, which offer detailed descriptions of research datasets, including data collection methods and technical analyses validating data quality. These descriptors aim to facilitate data reuse rather than testing hypotheses or presenting new interpretations, methods, or in-depth analyses.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


