Christopher E. Soulard, Jessica J. Walker, Britt W. Smith, Jason Kreitler
{"title":"利用国家级数据集对亚利桑那州湿地进行机器学习分类的可行性","authors":"Christopher E. Soulard, Jessica J. Walker, Britt W. Smith, Jason Kreitler","doi":"10.1002/esp.5985","DOIUrl":null,"url":null,"abstract":"<p>The advent of machine learning techniques has led to a proliferation of landscape classification products. These approaches can fill gaps in wetland inventories across the United States (U.S.) provided that large reference datasets are available to develop accurate models. In this study, we tested the feasibility of expediting the classification process by sourcing requisite training and testing data from existing national-scale land cover maps instead of customized sample sets. We created a single map of water and wetland presence by intersecting water and wetland classes from available land cover products (National Wetland Inventory, Gap Analysis Project, National Land Cover Database and Dynamic Surface Water Extent) across the U.S. state of Arizona, which has fewer wetland-specific mapping products than other parts of the U.S. We derived classified samples for four wetland classes from the combined map: open water, herbaceous wetlands, wooded wetlands and non-wetland cover. In Google Earth Engine, we developed a random forest model that combined the training data with spatial predictor variables, including vegetation greenness indices, wetness indices, seasonal index variation, topographic parameters and vegetation height metrics. Results show that the final model separates the four classes with an overall accuracy of 86.2%. The accuracy suggests that existing datasets can be effectively used to compile machine learning training samples to map wetlands in arid landscapes in the U.S. These methods hold promise for the generation of wetland inventories at more frequent intervals, which could allow more nuanced investigations of wetland change over time in response to anthropogenic and climatic drivers.</p>","PeriodicalId":11408,"journal":{"name":"Earth Surface Processes and Landforms","volume":"49 14","pages":"4632-4649"},"PeriodicalIF":2.8000,"publicationDate":"2024-09-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"The feasibility of using national-scale datasets for classifying wetlands in Arizona with machine learning\",\"authors\":\"Christopher E. Soulard, Jessica J. Walker, Britt W. Smith, Jason Kreitler\",\"doi\":\"10.1002/esp.5985\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The advent of machine learning techniques has led to a proliferation of landscape classification products. These approaches can fill gaps in wetland inventories across the United States (U.S.) provided that large reference datasets are available to develop accurate models. In this study, we tested the feasibility of expediting the classification process by sourcing requisite training and testing data from existing national-scale land cover maps instead of customized sample sets. We created a single map of water and wetland presence by intersecting water and wetland classes from available land cover products (National Wetland Inventory, Gap Analysis Project, National Land Cover Database and Dynamic Surface Water Extent) across the U.S. state of Arizona, which has fewer wetland-specific mapping products than other parts of the U.S. We derived classified samples for four wetland classes from the combined map: open water, herbaceous wetlands, wooded wetlands and non-wetland cover. In Google Earth Engine, we developed a random forest model that combined the training data with spatial predictor variables, including vegetation greenness indices, wetness indices, seasonal index variation, topographic parameters and vegetation height metrics. Results show that the final model separates the four classes with an overall accuracy of 86.2%. The accuracy suggests that existing datasets can be effectively used to compile machine learning training samples to map wetlands in arid landscapes in the U.S. These methods hold promise for the generation of wetland inventories at more frequent intervals, which could allow more nuanced investigations of wetland change over time in response to anthropogenic and climatic drivers.</p>\",\"PeriodicalId\":11408,\"journal\":{\"name\":\"Earth Surface Processes and Landforms\",\"volume\":\"49 14\",\"pages\":\"4632-4649\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-09-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Earth Surface Processes and Landforms\",\"FirstCategoryId\":\"89\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/esp.5985\",\"RegionNum\":3,\"RegionCategory\":\"地球科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"GEOGRAPHY, PHYSICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Earth Surface Processes and Landforms","FirstCategoryId":"89","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/esp.5985","RegionNum":3,"RegionCategory":"地球科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"GEOGRAPHY, PHYSICAL","Score":null,"Total":0}
The feasibility of using national-scale datasets for classifying wetlands in Arizona with machine learning
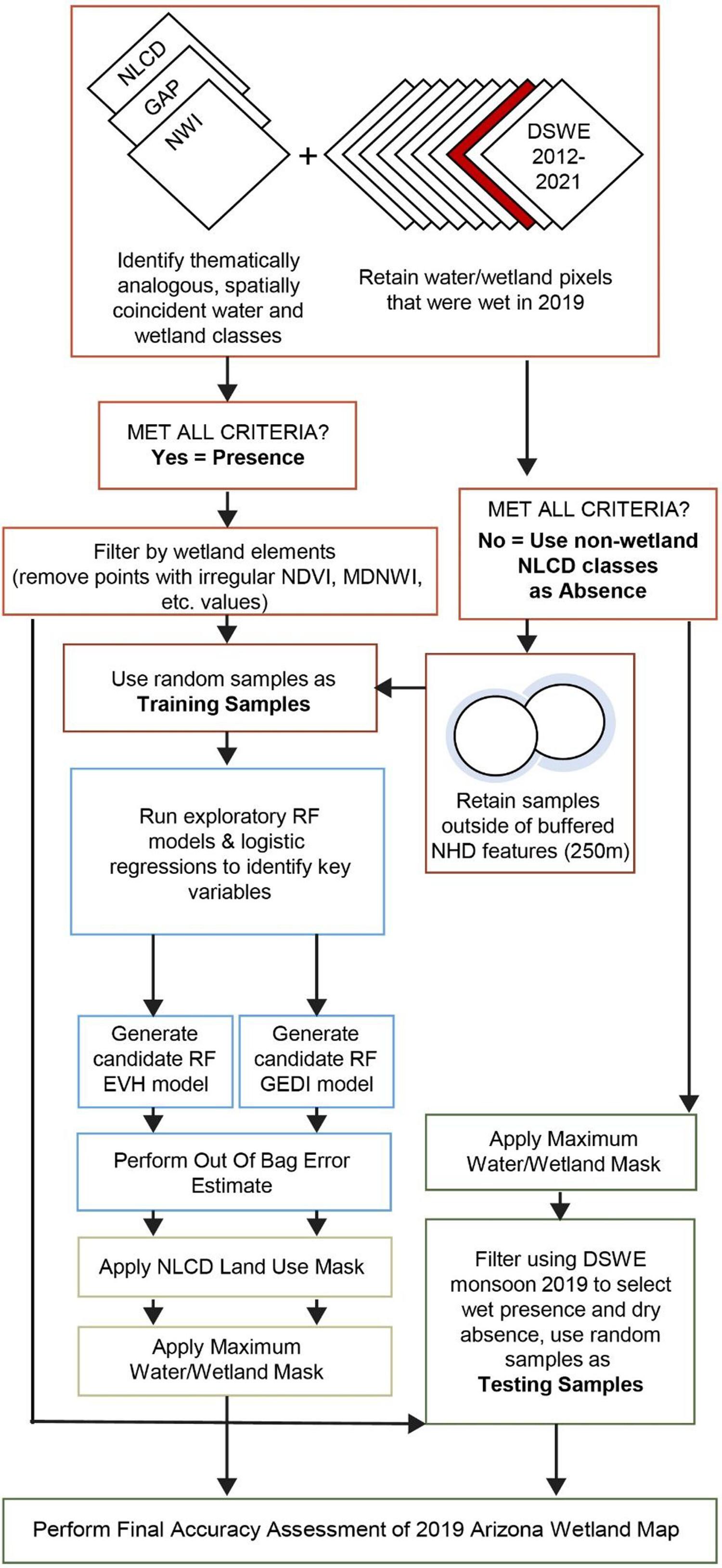
The advent of machine learning techniques has led to a proliferation of landscape classification products. These approaches can fill gaps in wetland inventories across the United States (U.S.) provided that large reference datasets are available to develop accurate models. In this study, we tested the feasibility of expediting the classification process by sourcing requisite training and testing data from existing national-scale land cover maps instead of customized sample sets. We created a single map of water and wetland presence by intersecting water and wetland classes from available land cover products (National Wetland Inventory, Gap Analysis Project, National Land Cover Database and Dynamic Surface Water Extent) across the U.S. state of Arizona, which has fewer wetland-specific mapping products than other parts of the U.S. We derived classified samples for four wetland classes from the combined map: open water, herbaceous wetlands, wooded wetlands and non-wetland cover. In Google Earth Engine, we developed a random forest model that combined the training data with spatial predictor variables, including vegetation greenness indices, wetness indices, seasonal index variation, topographic parameters and vegetation height metrics. Results show that the final model separates the four classes with an overall accuracy of 86.2%. The accuracy suggests that existing datasets can be effectively used to compile machine learning training samples to map wetlands in arid landscapes in the U.S. These methods hold promise for the generation of wetland inventories at more frequent intervals, which could allow more nuanced investigations of wetland change over time in response to anthropogenic and climatic drivers.
期刊介绍:
Earth Surface Processes and Landforms is an interdisciplinary international journal concerned with:
the interactions between surface processes and landforms and landscapes;
that lead to physical, chemical and biological changes; and which in turn create;
current landscapes and the geological record of past landscapes.
Its focus is core to both physical geographical and geological communities, and also the wider geosciences

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


