Brian D. Earp, Sebastian Porsdam Mann, Peng Liu, Ivar Hannikainen, Maryam Ali Khan, Yueying Chu, Julian Savulescu
{"title":"人工智能生成内容的功过:四个国家的个性化效果","authors":"Brian D. Earp, Sebastian Porsdam Mann, Peng Liu, Ivar Hannikainen, Maryam Ali Khan, Yueying Chu, Julian Savulescu","doi":"10.1111/nyas.15258","DOIUrl":null,"url":null,"abstract":"<p>Generative artificial intelligence (AI) raises ethical questions concerning moral and legal responsibility—specifically, the attributions of credit and blame for AI-generated content. For example, if a human invests minimal skill or effort to produce a beneficial output with an AI tool, can the human still take credit? How does the answer change if the AI has been personalized (i.e., fine-tuned) on previous outputs produced without AI assistance by the same human? We conducted a preregistered experiment with representative sampling (<i>N</i> = 1802) repeated in four countries (United States, United Kingdom, China, and Singapore). We investigated laypeople's attributions of credit and blame to human users for producing beneficial or harmful outputs with a standard large language model (LLM), a personalized LLM, or no AI assistance (control condition). Participants generally attributed more credit to human users of personalized versus standard LLMs for beneficial outputs, whereas LLM type did not significantly affect blame attributions for harmful outputs, with a partial exception among Chinese participants. In addition, UK participants attributed more blame for using any type of LLM versus no LLM. Practical, ethical, and policy implications of these findings are discussed.</p>","PeriodicalId":8250,"journal":{"name":"Annals of the New York Academy of Sciences","volume":"1542 1","pages":"51-57"},"PeriodicalIF":4.8000,"publicationDate":"2024-11-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/nyas.15258","citationCount":"0","resultStr":"{\"title\":\"Credit and blame for AI–generated content: Effects of personalization in four countries\",\"authors\":\"Brian D. Earp, Sebastian Porsdam Mann, Peng Liu, Ivar Hannikainen, Maryam Ali Khan, Yueying Chu, Julian Savulescu\",\"doi\":\"10.1111/nyas.15258\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Generative artificial intelligence (AI) raises ethical questions concerning moral and legal responsibility—specifically, the attributions of credit and blame for AI-generated content. For example, if a human invests minimal skill or effort to produce a beneficial output with an AI tool, can the human still take credit? How does the answer change if the AI has been personalized (i.e., fine-tuned) on previous outputs produced without AI assistance by the same human? We conducted a preregistered experiment with representative sampling (<i>N</i> = 1802) repeated in four countries (United States, United Kingdom, China, and Singapore). We investigated laypeople's attributions of credit and blame to human users for producing beneficial or harmful outputs with a standard large language model (LLM), a personalized LLM, or no AI assistance (control condition). Participants generally attributed more credit to human users of personalized versus standard LLMs for beneficial outputs, whereas LLM type did not significantly affect blame attributions for harmful outputs, with a partial exception among Chinese participants. In addition, UK participants attributed more blame for using any type of LLM versus no LLM. Practical, ethical, and policy implications of these findings are discussed.</p>\",\"PeriodicalId\":8250,\"journal\":{\"name\":\"Annals of the New York Academy of Sciences\",\"volume\":\"1542 1\",\"pages\":\"51-57\"},\"PeriodicalIF\":4.8000,\"publicationDate\":\"2024-11-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/nyas.15258\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Annals of the New York Academy of Sciences\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://nyaspubs.onlinelibrary.wiley.com/doi/10.1111/nyas.15258\",\"RegionNum\":3,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Annals of the New York Academy of Sciences","FirstCategoryId":"103","ListUrlMain":"https://nyaspubs.onlinelibrary.wiley.com/doi/10.1111/nyas.15258","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Credit and blame for AI–generated content: Effects of personalization in four countries
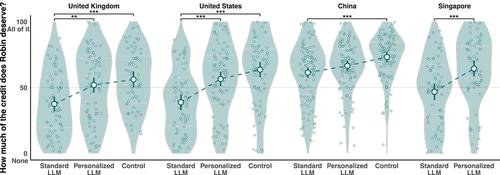
Generative artificial intelligence (AI) raises ethical questions concerning moral and legal responsibility—specifically, the attributions of credit and blame for AI-generated content. For example, if a human invests minimal skill or effort to produce a beneficial output with an AI tool, can the human still take credit? How does the answer change if the AI has been personalized (i.e., fine-tuned) on previous outputs produced without AI assistance by the same human? We conducted a preregistered experiment with representative sampling (N = 1802) repeated in four countries (United States, United Kingdom, China, and Singapore). We investigated laypeople's attributions of credit and blame to human users for producing beneficial or harmful outputs with a standard large language model (LLM), a personalized LLM, or no AI assistance (control condition). Participants generally attributed more credit to human users of personalized versus standard LLMs for beneficial outputs, whereas LLM type did not significantly affect blame attributions for harmful outputs, with a partial exception among Chinese participants. In addition, UK participants attributed more blame for using any type of LLM versus no LLM. Practical, ethical, and policy implications of these findings are discussed.
期刊介绍:
Published on behalf of the New York Academy of Sciences, Annals of the New York Academy of Sciences provides multidisciplinary perspectives on research of current scientific interest with far-reaching implications for the wider scientific community and society at large. Each special issue assembles the best thinking of key contributors to a field of investigation at a time when emerging developments offer the promise of new insight. Individually themed, Annals special issues stimulate new ways to think about science by providing a neutral forum for discourse—within and across many institutions and fields.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


