通过聚合绑定增强文本到图像扩散中的语义映射
IF 2.8
4区 计算机科学
Q2 COMPUTER SCIENCE, SOFTWARE ENGINEERING
引用次数: 0
摘要
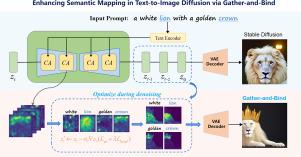
文本到图像的合成是一项具有挑战性的任务,其目的是根据自然语言描述生成逼真、多样的图像。然而,现有的文本到图像扩散模型(如稳定扩散模型)有时无法满足用户的语义描述,尤其是当提示包含多个概念或修饰词(如颜色)时。通过可视化稳定扩散模型在去噪过程中的交叉注意图,我们发现其中一个概念的注意图非常分散,无法形成一个整体,逐渐被忽略。此外,修饰词的注意图很难与相应的概念重叠,导致语义映射不正确。针对这一问题,我们提出了一种 "聚合与绑定"(Gather-and-Bind)方法,即在去噪过程中对交叉注意力图进行干预,以缓解灾难性遗忘和属性绑定问题,而无需任何预训练。具体来说,我们首先使用信息熵来测量交叉注意力图的分散程度,并构建一个信息熵损失来收集这些分散的注意力图,最终在生成的输出中捕获所有概念。此外,我们还构建了一种属性绑定损失,使属性注意图与其对应概念之间的距离最小化,从而使模型能够建立正确的语义映射,并显著提高了基线模型的性能。我们在公共数据集上进行了大量实验,证明我们的方法能更好地捕捉输入提示的语义信息。代码见 https://github.com/huan085128/Gather-and-Bind。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Enhancing semantic mapping in text-to-image diffusion via Gather-and-Bind
Text-to-image synthesis is a challenging task that aims to generate realistic and diverse images from natural language descriptions. However, existing text-to-image diffusion models (e.g., Stable Diffusion) sometimes fail to satisfy the semantic descriptions of the users, especially when the prompts contain multiple concepts or modifiers such as colors. By visualizing the cross-attention maps of the Stable Diffusion model during the denoising process, we find that one of the concepts has a very scattered attention map, which cannot form a whole and gradually gets ignored. Moreover, the attention maps of the modifiers are hard to overlap with the corresponding concepts, resulting in incorrect semantic mapping. To address this issue, we propose a Gather-and-Bind method that intervenes in the cross-attention maps during the denoising process to alleviate the catastrophic forgetting and attribute binding problems without any pre-training. Specifically, we first use information entropy to measure the dispersion degree of the cross-attention maps and construct an information entropy loss to gather these scattered attention maps, which eventually captures all the concepts in the generated output. Furthermore, we construct an attribute binding loss that minimizes the distance between the attention maps of the attributes and their corresponding concepts, which enables the model to establish correct semantic mapping and significantly improves the performance of the baseline model. We conduct extensive experiments on public datasets and demonstrate that our method can better capture the semantic information of the input prompts. Code is available at https://github.com/huan085128/Gather-and-Bind.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computers & Graphics-Uk
工程技术-计算机:软件工程
CiteScore
5.30
自引率
12.00%
发文量
173
审稿时长
38 days
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


