技能很重要:多代理合作强化学习的动态技能学习
IF 6
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
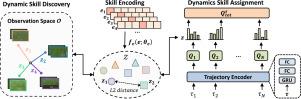
随着智能的普及,智能机器之间合作的必要性使得协作式多代理强化学习(MARL)的研究更加广泛。现有方法通常通过对环境进行任务分解或对代理进行角色分类来应对这一挑战。然而,这些研究可能依赖于代理之间的参数共享,导致代理行为的同质性,这对于复杂任务来说并不有效。或者依赖外部奖励的训练难以适应奖励稀少的场景。基于上述挑战,我们在本文中提出了一种新颖的动态技能学习(DSL)框架,让代理在内部奖励的激励下学习更多样化的能力。具体来说,动态技能学习有两个组成部分:(i) 动态技能发现,它鼓励以无监督的方式探索环境,利用技能向量和轨迹表示之间的内积产生内在奖励,从而产生有意义的技能。同时,利用状态表示函数的 Lipschitz 约束来确保所学技能的正确轨迹。(ii) 动态技能分配,即利用策略控制器,根据每个代理的不同轨迹潜变量为其分配技能。此外,为了避免技能选择的频繁变化导致训练不稳定,我们引入了正则化项来限制相邻时间步之间的技能切换。我们在《星际争霸 II》和谷歌研究足球这两个具有挑战性的基准上对 DSL 方法进行了全面测试。实验结果表明,与 QMIX 和 RODE 等强基准相比,DSL 有效地提高了性能,并且更能适应困难的协作场景。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Skill matters: Dynamic skill learning for multi-agent cooperative reinforcement learning
With the popularization of intelligence, the necessity of cooperation between intelligent machines makes the research of collaborative multi-agent reinforcement learning (MARL) more extensive. Existing approaches typically address this challenge through task decomposition of the environment or role classification of agents. However, these studies may rely on the sharing of parameters between agents, resulting in the homogeneity of agent behavior, which is not effective for complex tasks. Or training that relies on external rewards is difficult to adapt to scenarios with sparse rewards. Based on the above challenges, in this paper we propose a novel dynamic skill learning (DSL) framework for agents to learn more diverse abilities motivated by internal rewards. Specifically, the DSL has two components: (i) Dynamic skill discovery, which encourages the production of meaningful skills by exploring the environment in an unsupervised manner, using the inner product between a skill vector and a trajectory representation to generate intrinsic rewards. Meanwhile, the Lipschitz constraint of the state representation function is used to ensure the proper trajectory of the learned skills. (ii) Dynamic skill assignment, which utilizes a policy controller to assign skills to each agent based on its different trajectory latent variables. In addition, in order to avoid training instability caused by frequent changes in skill selection, we introduce a regularization term to limit skill switching between adjacent time steps. We thoroughly tested the DSL approach on two challenging benchmarks, StarCraft II and Google Research Football. Experimental results show that compared with strong benchmarks such as QMIX and RODE, DSL effectively improves performance and is more adaptable to difficult collaborative scenarios.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Neural Networks
工程技术-计算机:人工智能
CiteScore
13.90
自引率
7.70%
发文量
425
审稿时长
67 days
期刊介绍:
Neural Networks is a platform that aims to foster an international community of scholars and practitioners interested in neural networks, deep learning, and other approaches to artificial intelligence and machine learning. Our journal invites submissions covering various aspects of neural networks research, from computational neuroscience and cognitive modeling to mathematical analyses and engineering applications. By providing a forum for interdisciplinary discussions between biology and technology, we aim to encourage the development of biologically-inspired artificial intelligence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


