基于时间序列的机器学习用于预测采用不同试剂剂量的全规模饮用水处理中的多元水质
IF 11.4
1区 环境科学与生态学
Q1 ENGINEERING, ENVIRONMENTAL
引用次数: 0
摘要
准确预测饮用水水质对于智能供水管理以及保持水处理工艺的稳定性和效率至关重要。本研究提出了一种优化的时间序列机器学习方法,用于准确预测多元饮用水水质,并明确考虑了试剂投加的时间依赖效应。通过利用全规模处理厂的数据,我们构建了包含进水水质参数、试剂剂量和出水特征的特征工程时间序列数据集。我们开发了七种预测模型,包括传统的机器学习(ML)模型和深度学习(DL)模型,并对照天真平均基线模型进行了严格评估。结果表明,通过时间特征工程增强的传统 ML 模型的性能可与广泛使用的 DL 模型和天真平均基线模型相媲美。具体来说,XGBoost 模型在以 12 小时时滞步长动态预测四种水质特征时取得了更高的预测精度,在平均绝对百分比误差 (MAPE) 方面比天真的基线模型高出 3-4%。这一发现强调了加入 12 小时间隔以有效捕捉试剂投加对水质预测的延迟影响的重要性。此外,SHAP 模型可解释性分析为 XGBoost 模型的决策过程提供了有价值的见解,揭示了其与既定水处理原则相一致的强大数据驱动基础。这项研究凸显了优化机器学习技术在增强水净化过程和实现供水行业更明智的数据驱动决策方面的巨大潜力。本文章由计算机程序翻译,如有差异,请以英文原文为准。
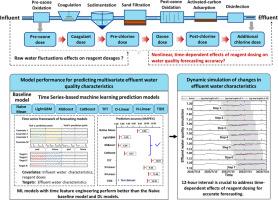
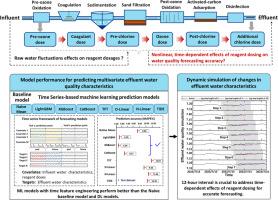
Time series-based machine learning for forecasting multivariate water quality in full-scale drinking water treatment with various reagent dosages
Accurately predicting drinking water quality is critical for intelligent water supply management and for maintaining the stability and efficiency of water treatment processes. This study presents an optimized time series machine learning approach for accurately predicting multivariate drinking water quality, explicitly considering the time-dependent effects of reagent dosing. By leveraging data from a full-scale treatment plant, we constructed feature-engineered time series datasets incorporating influent water quality parameters, reagent dosages and effluent water characteristics. Seven predictive models, including both traditional machine learning (ML) and deep learning (DL) models were developed and rigorously evaluated against a naive mean baseline model. Our results demonstrate that traditional ML models, enhanced with time feature engineering, rivaled the performance of both widely used DL models and the naive mean baseline model. Specifically, an XGBoost model achieved superior prediction accuracy in dynamically forecasting four water quality characteristics at a 12-hour time lag step, outperforming the naive baseline model by 3–4 % in terms of Mean Absolute Percentage Error (MAPE). This finding underscores the importance of incorporating a 12-hour interval to effectively capture the delayed impact of reagent dosing on water quality prediction. Furthermore, SHAP model interpretability analysis provided valuable insights into the XGBoost model's decision-making process, revealing its strong data-driven foundation aligned with established water treatment principles. This research highlights the significant potential of optimized machine learning techniques for enhancing water purification processes and enabling more informed, data-driven decision-making in the water supply industry.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Water Research
环境科学-工程:环境
CiteScore
20.80
自引率
9.40%
发文量
1307
审稿时长
38 days
期刊介绍:
Water Research, along with its open access companion journal Water Research X, serves as a platform for publishing original research papers covering various aspects of the science and technology related to the anthropogenic water cycle, water quality, and its management worldwide. The audience targeted by the journal comprises biologists, chemical engineers, chemists, civil engineers, environmental engineers, limnologists, and microbiologists. The scope of the journal include:
•Treatment processes for water and wastewaters (municipal, agricultural, industrial, and on-site treatment), including resource recovery and residuals management;
•Urban hydrology including sewer systems, stormwater management, and green infrastructure;
•Drinking water treatment and distribution;
•Potable and non-potable water reuse;
•Sanitation, public health, and risk assessment;
•Anaerobic digestion, solid and hazardous waste management, including source characterization and the effects and control of leachates and gaseous emissions;
•Contaminants (chemical, microbial, anthropogenic particles such as nanoparticles or microplastics) and related water quality sensing, monitoring, fate, and assessment;
•Anthropogenic impacts on inland, tidal, coastal and urban waters, focusing on surface and ground waters, and point and non-point sources of pollution;
•Environmental restoration, linked to surface water, groundwater and groundwater remediation;
•Analysis of the interfaces between sediments and water, and between water and atmosphere, focusing specifically on anthropogenic impacts;
•Mathematical modelling, systems analysis, machine learning, and beneficial use of big data related to the anthropogenic water cycle;
•Socio-economic, policy, and regulations studies.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


