细胞类型注释中基于知识的归纳偏差和领域适应性
IF 5.2
1区 生物学
Q1 BIOLOGY
引用次数: 0
摘要
测量技术通常会导致特定模式的细胞数据批次之间存在领域差距。归纳偏差指的是描述模型预测行为的一系列假设。不同的注释方法具有不同的归纳偏差,从而导致不同程度的普适性和可解释性。鉴于某些细胞类型表现出独特的功能模式,我们假设细胞注释方法的归纳偏差应与这些生物模式相一致,以产生有意义的预测。在这项研究中,我们提出了 KIDA(基于知识的归纳偏差和领域适应)。基于知识的归纳偏差将从参考数据集(由多个批次组成)中学习到的预测规则限制在与生物学相关的功能模式上,从而提高模型对未见批次的泛化能力。由于查询数据集也包含来自多个批次的空白,KIDA 的领域适应性采用伪标签进行自知提炼,有效缩小了模型预测与查询数据集之间的分布差距。基准实验证明,KIDA 能够实现准确的跨批次细胞类型注释。基于知识的归纳偏差和领域自适应可以提高深度学习模型的细胞类型标注准确性。本文章由计算机程序翻译,如有差异,请以英文原文为准。
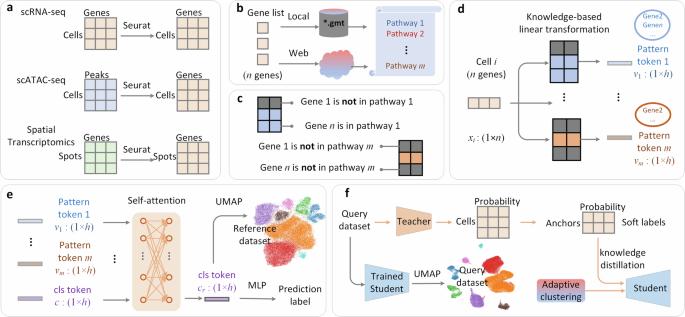
Knowledge-based inductive bias and domain adaptation for cell type annotation
Measurement techniques often result in domain gaps among batches of cellular data from a specific modality. The effectiveness of cross-batch annotation methods is influenced by inductive bias, which refers to a set of assumptions that describe the behavior of model predictions. Different annotation methods possess distinct inductive biases, leading to varying degrees of generalizability and interpretability. Given that certain cell types exhibit unique functional patterns, we hypothesize that the inductive biases of cell annotation methods should align with these biological patterns to produce meaningful predictions. In this study, we propose KIDA, Knowledge-based Inductive bias and Domain Adaptation. The knowledge-based inductive bias constrains the prediction rules learned from the reference dataset, composed of multiple batches, to functional patterns relevant to biology, thereby enhancing the generalization of the model to unseen batches. Since the query dataset also contains gaps from multiple batches, KIDA’s domain adaptation employs pseudo labels for self-knowledge distillation, effectively narrowing the distribution gap between model predictions and the query dataset. Benchmark experiments demonstrate that KIDA is capable of achieving accurate cross-batch cell type annotation. Knowledge-based inductive bias and domain adaptation can enhance the cell type annotation accuracy of deep learning models.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Communications Biology
Medicine-Medicine (miscellaneous)
CiteScore
8.60
自引率
1.70%
发文量
1233
审稿时长
13 weeks
期刊介绍:
Communications Biology is an open access journal from Nature Research publishing high-quality research, reviews and commentary in all areas of the biological sciences. Research papers published by the journal represent significant advances bringing new biological insight to a specialized area of research.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


