{"title":"数据复杂性对分类器性能的影响。","authors":"Jonas Eberlein, Daniel Rodriguez, Rachel Harrison","doi":"10.1007/s10664-024-10554-5","DOIUrl":null,"url":null,"abstract":"<p><p>The research area of Software Defect Prediction (SDP) is both extensive and popular, and is often treated as a classification problem. Improvements in classification, pre-processing and tuning techniques, (together with many factors which can influence model performance) have encouraged this trend. However, no matter the effort in these areas, it seems that there is a ceiling in the performance of the classification models used in SDP. In this paper, the issue of classifier performance is analysed from the perspective of data complexity. Specifically, data complexity metrics are calculated using the Unified Bug Dataset, a collection of well-known SDP datasets, and then checked for correlation with the defect prediction performance of machine learning classifiers (in particular, the classifiers C5.0, Naive Bayes, Artificial Neural Networks, Random Forests, and Support Vector Machines). In this work, different domains of competence and incompetence are identified for the classifiers. Similarities and differences between the classifiers and the performance metrics are found and the Unified Bug Dataset is analysed from the perspective of data complexity. We found that certain classifiers work best in certain situations and that all data complexity metrics can be problematic, although certain classifiers did excel in some situations.</p>","PeriodicalId":11525,"journal":{"name":"Empirical Software Engineering","volume":"30 1","pages":"16"},"PeriodicalIF":3.6000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11527945/pdf/","citationCount":"0","resultStr":"{\"title\":\"The effect of data complexity on classifier performance.\",\"authors\":\"Jonas Eberlein, Daniel Rodriguez, Rachel Harrison\",\"doi\":\"10.1007/s10664-024-10554-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The research area of Software Defect Prediction (SDP) is both extensive and popular, and is often treated as a classification problem. Improvements in classification, pre-processing and tuning techniques, (together with many factors which can influence model performance) have encouraged this trend. However, no matter the effort in these areas, it seems that there is a ceiling in the performance of the classification models used in SDP. In this paper, the issue of classifier performance is analysed from the perspective of data complexity. Specifically, data complexity metrics are calculated using the Unified Bug Dataset, a collection of well-known SDP datasets, and then checked for correlation with the defect prediction performance of machine learning classifiers (in particular, the classifiers C5.0, Naive Bayes, Artificial Neural Networks, Random Forests, and Support Vector Machines). In this work, different domains of competence and incompetence are identified for the classifiers. Similarities and differences between the classifiers and the performance metrics are found and the Unified Bug Dataset is analysed from the perspective of data complexity. We found that certain classifiers work best in certain situations and that all data complexity metrics can be problematic, although certain classifiers did excel in some situations.</p>\",\"PeriodicalId\":11525,\"journal\":{\"name\":\"Empirical Software Engineering\",\"volume\":\"30 1\",\"pages\":\"16\"},\"PeriodicalIF\":3.6000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11527945/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Empirical Software Engineering\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10664-024-10554-5\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/31 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Empirical Software Engineering","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10664-024-10554-5","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/31 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
The effect of data complexity on classifier performance.
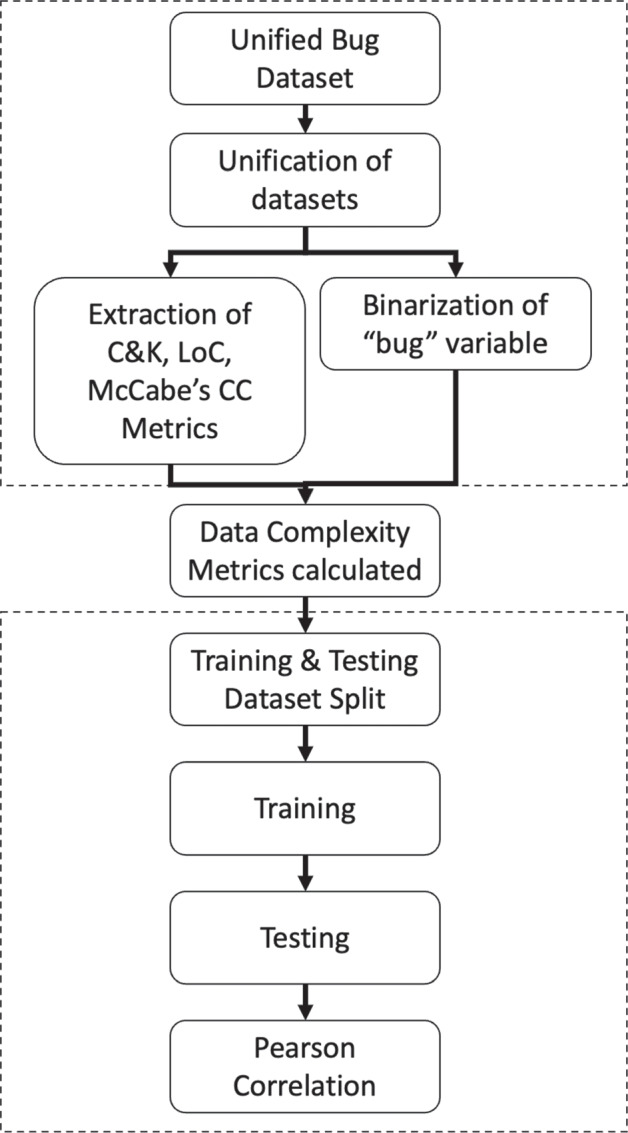
The research area of Software Defect Prediction (SDP) is both extensive and popular, and is often treated as a classification problem. Improvements in classification, pre-processing and tuning techniques, (together with many factors which can influence model performance) have encouraged this trend. However, no matter the effort in these areas, it seems that there is a ceiling in the performance of the classification models used in SDP. In this paper, the issue of classifier performance is analysed from the perspective of data complexity. Specifically, data complexity metrics are calculated using the Unified Bug Dataset, a collection of well-known SDP datasets, and then checked for correlation with the defect prediction performance of machine learning classifiers (in particular, the classifiers C5.0, Naive Bayes, Artificial Neural Networks, Random Forests, and Support Vector Machines). In this work, different domains of competence and incompetence are identified for the classifiers. Similarities and differences between the classifiers and the performance metrics are found and the Unified Bug Dataset is analysed from the perspective of data complexity. We found that certain classifiers work best in certain situations and that all data complexity metrics can be problematic, although certain classifiers did excel in some situations.
期刊介绍:
Empirical Software Engineering provides a forum for applied software engineering research with a strong empirical component, and a venue for publishing empirical results relevant to both researchers and practitioners. Empirical studies presented here usually involve the collection and analysis of data and experience that can be used to characterize, evaluate and reveal relationships between software development deliverables, practices, and technologies. Over time, it is expected that such empirical results will form a body of knowledge leading to widely accepted and well-formed theories.
The journal also offers industrial experience reports detailing the application of software technologies - processes, methods, or tools - and their effectiveness in industrial settings.
Empirical Software Engineering promotes the publication of industry-relevant research, to address the significant gap between research and practice.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


