基于选定状态空间和散列的高效跨视角图像融合方法促进城市感知
IF 14.7
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
在跨视角图像地理定位领域,传统的基于卷积神经网络(CNN)的学习模型由于无法建立全局相关性模型,其融合性能并不理想。基于变换器的融合方法可以很好地弥补上述问题,但变换器具有二次计算复杂性和巨大的 GPU 内存消耗。最近推出的基于选择状态空间的 Mamba 模型具有很强的长序列建模能力、较低的 GPU 内存占用和较少的 GFLOP。因此,将 Mamba 应用于跨视角图像地理定位任务是非常有吸引力和值得研究的。此外,在图像匹配过程(即卫星/航拍和街景数据的融合)中,我们发现基于浮点特征的相似性度量的存储占用率很高。有效地将浮点特征转换成哈希代码是一个可行的解决方案。在本研究中,我们提出了一种纯粹基于 Vision Mamba 和散列的跨视图图像地理定位方法(S6HG)。S6HG 充分利用了 Vision Mamba 在全局信息建模和显式位置信息编码方面的优势,以及散列码的低存储占用率。我们的方法包括两个阶段。在第一阶段,我们使用纯粹基于视觉 Mamba 的连体网络,分别为街景图像和卫星图像嵌入特征。我们的第一阶段模型称为 S6G。在第二阶段,我们构建了一个跨视图自动编码器来进一步细化和压缩嵌入的特征,然后将细化后的特征简单地映射为哈希代码。综合实验表明,S6G 在 CVACT 数据集上取得了优异的结果,在 CVUSA 数据集上的结果与最先进的方法不相上下。值得注意的是,在存储 90,618 个检索图库数据时,其他基于浮点特征的方法(4096 维)比 S6HG(768 位)快 170.59 倍。此外,S6G 的推理效率也高于基于 ViT 的计算方法。本文章由计算机程序翻译,如有差异,请以英文原文为准。
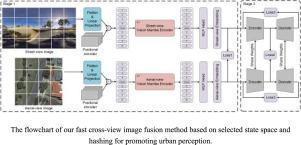
An efficient cross-view image fusion method based on selected state space and hashing for promoting urban perception
In the field of cross-view image geolocation, traditional convolutional neural network (CNN)-based learning models generate unsatisfactory fusion performance due to their inability to model global correlations. The Transformer-based fusion methods can well compensate for the above problems, however, the Transformer has quadratic computational complexity and huge GPU memory consumption. The recent Mamba model based on the selection state space has a strong ability to model long sequences, lower GPU memory occupancy, and fewer GFLOPs. It is thus attractive and worth studying to apply Mamba to the cross-view image geolocation task. In addition, in the image-matching process (i.e., fusion of satellite/aerial and street view data.), we found that the storage occupancy of similarity measures based on floating-point features is high. Efficiently converting floating-point features into hash codes is a possible solution. In this study, we propose a cross-view image geolocation method (S6HG) based purely on Vision Mamba and hashing. S6HG fully utilizes the advantages of Vision Mamba in global information modeling and explicit location information encoding and the low storage occupancy of hash codes. Our method consists of two stages. In the first stage, we use a Siamese network based purely on vision Mamba to embed features for street view images and satellite images respectively. Our first-stage model is called S6G. In the second stage, we construct a cross-view autoencoder to further refine and compress the embedded features, and then simply map the refined features to hash codes. Comprehensive experiments show that S6G has achieved superior results on the CVACT dataset and comparable results to the most advanced methods on the CVUSA dataset. It is worth noting that other floating-point feature-based methods (4096-dimension) are 170.59 times faster than S6HG (768-bit) in storing 90,618 retrieval gallery data. Furthermore, the inference efficiency of S6G is higher than ViT-based computational methods.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Information Fusion
工程技术-计算机:理论方法
CiteScore
33.20
自引率
4.30%
发文量
161
审稿时长
7.9 months
期刊介绍:
Information Fusion serves as a central platform for showcasing advancements in multi-sensor, multi-source, multi-process information fusion, fostering collaboration among diverse disciplines driving its progress. It is the leading outlet for sharing research and development in this field, focusing on architectures, algorithms, and applications. Papers dealing with fundamental theoretical analyses as well as those demonstrating their application to real-world problems will be welcome.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


