避免回溯和烧毁输入:使用 OpenMP 进行 CONUS 规模流域划分
IF 4.8
2区 环境科学与生态学
Q1 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
摘要
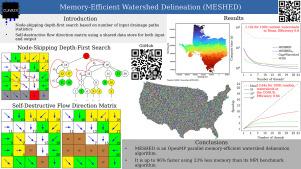
针对美国毗连区(CONUS)尺度的水文建模,介绍了内存效率流域划分(MESHED)并行算法。为一项大陆尺度的研究划分数以万计的流域不仅计算量大,而且耗费内存。现有算法需要单独的输入和输出数据存储。然而,随着需要划定的流域数量和输入数据分辨率的大幅增加,算法所需的内存量也会迅速增加。MESHED 在处理输入数据时将其销毁,并采用节点跳转深度优先搜索,从而将输入和输出数据存储在同一个数据存储区,进一步减少了所需内存。对于德克萨斯州的 1000 个流域,MESHED 的运行速度比中央处理器(CPU)基准算法快 95%,内存占用率却低 33%。在一次扩展实验中,它在 13.64 秒内就划定了整个美国的 100,000 个流域。在内存容量相同的情况下,MESHED 可以解决的问题比 CPU 基准算法大 50%。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Avoid backtracking and burn your inputs: CONUS-scale watershed delineation using OpenMP
The Memory-Efficient Watershed Delineation (MESHED) parallel algorithm is introduced for Contiguous United States (CONUS)-scale hydrologic modeling. Delineating tens of thousands of watersheds for a continental-scale study can not only be computationally intensive, but also be memory-consuming. Existing algorithms require separate input and output data stores. However, as the number of watersheds to delineate and the resolution of input data grow significantly, the amount of memory required for an algorithm also quickly increases. MESHED uses one data store for both input and output by destructing input data as processed and a node-skipping depth-first search to further reduce required memory. For 1000 watersheds in Texas, MESHED performed 95 % faster than the Central Processing Unit (CPU) benchmark algorithm using 33 % less memory. In a scaling experiment, it delineated 100,000 watersheds across the CONUS in 13.64 s. Given the same amount of memory, MESHED can solve 50 % larger problems than the CPU benchmark algorithm can.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Environmental Modelling & Software
工程技术-工程:环境
CiteScore
9.30
自引率
8.20%
发文量
241
审稿时长
60 days
期刊介绍:
Environmental Modelling & Software publishes contributions, in the form of research articles, reviews and short communications, on recent advances in environmental modelling and/or software. The aim is to improve our capacity to represent, understand, predict or manage the behaviour of environmental systems at all practical scales, and to communicate those improvements to a wide scientific and professional audience.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


