用于 RGB-D 突出物体检测的轻量级跨模态变换器
IF 4.3
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
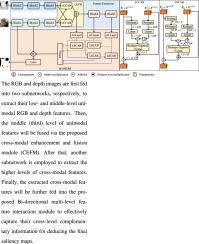
最近,基于变压器的 RGB-D 突出物体检测(SOD)模型将性能提升到了一个新的水平。然而,它们的代价是消耗大量资源,包括内存和电力,从而阻碍了它们在现实生活中的应用。为了解决这一问题,本文将介绍一种用于 RGB-D SOD 的新型轻量级跨模态变换器(LCT)。具体来说,LCT 将首先采用中间层特征融合结构,以轻量级 Transformer 为骨干,从而降低参数和计算成本。然后,借助变换器,有效捕捉多模态输入图像中的跨模态和跨级别互补信息,从而弥补性能的下降。为此,将设计一个带有轻量级信道交叉注意模块(LCCAB)的跨模态增强和融合模块(CEFM),以有效捕捉跨模态互补信息,同时降低成本。双向多级特征交互模块(Bi-MFIM)与轻量级空间交叉注意模块(LSCAB)将被设计用于捕捉跨级互补上下文信息。借助 CEFM 和 Bi-MFIM,可以很好地补偿因参数减少而导致的性能下降,从而提高性能。通过这种方法,我们提出的模型只有 2.8M 个参数、7.6G FLOPs 和 66 FPS 的运行速度。此外,在多个基准数据集上的实验结果表明,我们提出的模型可以取得与其他模型相当甚至更好的结果。我们的代码将在 https://github.com/nexiakele/lightweight-cross-modal-Transformer-LCT-for-RGB-D-SOD 上发布。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Lightweight cross-modal transformer for RGB-D salient object detection
Recently, Transformer-based RGB-D salient object detection (SOD) models have pushed the performance to a new level. However, they come at the cost of consuming abundant resources, including memory and power, thus hindering their real-life applications. To remedy this situation, a novel lightweight cross-modal Transformer (LCT) for RGB-D SOD will be presented in this paper. Specifically, LCT will first reduce its parameters and computational costs by employing a middle-level feature fusion structure and taking a lightweight Transformer as the backbone. Then, with the aid of Transformers, it will compensate for performance degradation by effectively capturing the cross-modal and cross-level complementary information from the multi-modal input images. To this end, a cross-modal enhancement and fusion module (CEFM) with a lightweight channel-wise cross attention block (LCCAB) will be designed to capture the cross-modal complementary information effectively but with fewer costs. A bi-directional multi-level feature interaction module (Bi-MFIM) with a lightweight spatial-wise cross attention block (LSCAB) will be designed to capture the cross-level complementary context information. By virtue of CEFM and Bi-MFIM, the performance degradation caused by parameter reduction can be well compensated, thus boosting the performances. By doing so, our proposed model has only 2.8M parameters with 7.6G FLOPs and runs at 66 FPS. Furthermore, experimental results on several benchmark datasets show that our proposed model can achieve competitive or even better results than other models. Our code will be released on https://github.com/nexiakele/lightweight-cross-modal-Transformer-LCT-for-RGB-D-SOD.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computer Vision and Image Understanding
工程技术-工程:电子与电气
CiteScore
7.80
自引率
4.40%
发文量
112
审稿时长
79 days
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


