Calum Snowdon, Giuseppe M. J. Barca
求助PDF
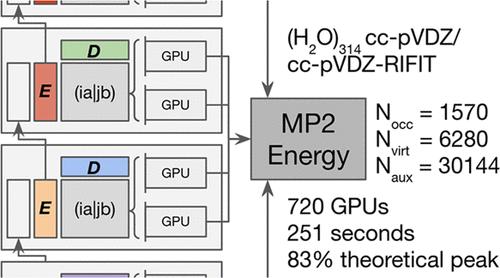
{"title":"适用于分布式多 GPU 架构的高效 RI-MP2 算法","authors":"Calum Snowdon, Giuseppe M. J. Barca","doi":"10.1021/acs.jctc.4c00814","DOIUrl":null,"url":null,"abstract":"Second-order Møller–Plesset perturbation theory (MP2) using the Resolution of the Identity approximation (RI-MP2) is a widely used method for computing molecular energies beyond the Hartree–Fock mean-field approximation. However, its high computational cost and lack of efficient algorithms for modern supercomputing architectures limit its applicability to large molecules. In this paper, we present the first distributed-memory many-GPU RI-MP2 algorithm explicitly designed to utilize hundreds of GPU accelerators for every step of the computation. Our novel algorithm achieves near-peak performance on GPU-based supercomputers through the development of a distributed memory algorithm for forming RI-MP2 intermediate tensors with zero internode communication, except for a single <i></i><span style=\"color: inherit;\"></span><span data-mathml='<math xmlns=\"http://www.w3.org/1998/Math/MathML\" display=\"inline\"><mi mathvariant=\"script\">O</mi><mrow><mo stretchy=\"false\">(</mo><msup><mi>N</mi><mn>2</mn></msup><mo stretchy=\"false\">)</mo></mrow></math>' role=\"presentation\" style=\"position: relative;\" tabindex=\"0\"><nobr aria-hidden=\"true\"><span style=\"width: 3.071em; display: inline-block;\"><span style=\"display: inline-block; position: relative; width: 2.787em; height: 0px; font-size: 110%;\"><span style=\"position: absolute; clip: rect(1.537em, 1002.73em, 2.901em, -999.997em); top: -2.554em; left: 0em;\"><span><span style=\"font-family: STIXMathJax_Script-italic;\">𝒪</span><span><span style=\"font-family: STIXMathJax_Main;\">(</span><span><span style=\"display: inline-block; position: relative; width: 1.423em; height: 0px;\"><span style=\"position: absolute; clip: rect(3.185em, 1000.91em, 4.151em, -999.997em); top: -3.974em; left: 0em;\"><span style=\"font-family: STIXMathJax_Normal-italic;\">𝑁<span style=\"display: inline-block; overflow: hidden; height: 1px; width: 0.06em;\"></span></span><span style=\"display: inline-block; width: 0px; height: 3.98em;\"></span></span><span style=\"position: absolute; top: -4.315em; left: 0.969em;\"><span style=\"font-size: 70.7%; font-family: STIXMathJax_Main;\">2</span><span style=\"display: inline-block; width: 0px; height: 3.98em;\"></span></span></span></span><span style=\"font-family: STIXMathJax_Main;\">)</span></span></span><span style=\"display: inline-block; width: 0px; height: 2.56em;\"></span></span></span><span style=\"display: inline-block; overflow: hidden; vertical-align: -0.247em; border-left: 0px solid; width: 0px; height: 1.253em;\"></span></span></nobr><span role=\"presentation\"><math display=\"inline\" xmlns=\"http://www.w3.org/1998/Math/MathML\"><mi mathvariant=\"script\">O</mi><mrow><mo stretchy=\"false\">(</mo><msup><mi>N</mi><mn>2</mn></msup><mo stretchy=\"false\">)</mo></mrow></math></span></span><script type=\"math/mml\"><math display=\"inline\"><mi mathvariant=\"script\">O</mi><mrow><mo stretchy=\"false\">(</mo><msup><mi>N</mi><mn>2</mn></msup><mo stretchy=\"false\">)</mo></mrow></math></script> asynchronous broadcast, and a distributed memory algorithm for the <i></i><span style=\"color: inherit;\"></span><span data-mathml='<math xmlns=\"http://www.w3.org/1998/Math/MathML\" display=\"inline\"><mi mathvariant=\"script\">O</mi><mrow><mo stretchy=\"false\">(</mo><msup><mi>N</mi><mn>5</mn></msup><mo stretchy=\"false\">)</mo></mrow></math>' role=\"presentation\" style=\"position: relative;\" tabindex=\"0\"><nobr aria-hidden=\"true\"><span style=\"width: 3.071em; display: inline-block;\"><span style=\"display: inline-block; position: relative; width: 2.787em; height: 0px; font-size: 110%;\"><span style=\"position: absolute; clip: rect(1.537em, 1002.73em, 2.901em, -999.997em); top: -2.554em; left: 0em;\"><span><span style=\"font-family: STIXMathJax_Script-italic;\">𝒪</span><span><span style=\"font-family: STIXMathJax_Main;\">(</span><span><span style=\"display: inline-block; position: relative; width: 1.423em; height: 0px;\"><span style=\"position: absolute; clip: rect(3.185em, 1000.91em, 4.151em, -999.997em); top: -3.974em; left: 0em;\"><span style=\"font-family: STIXMathJax_Normal-italic;\">𝑁<span style=\"display: inline-block; overflow: hidden; height: 1px; width: 0.06em;\"></span></span><span style=\"display: inline-block; width: 0px; height: 3.98em;\"></span></span><span style=\"position: absolute; top: -4.315em; left: 0.969em;\"><span style=\"font-size: 70.7%; font-family: STIXMathJax_Main;\">5</span><span style=\"display: inline-block; width: 0px; height: 3.98em;\"></span></span></span></span><span style=\"font-family: STIXMathJax_Main;\">)</span></span></span><span style=\"display: inline-block; width: 0px; height: 2.56em;\"></span></span></span><span style=\"display: inline-block; overflow: hidden; vertical-align: -0.247em; border-left: 0px solid; width: 0px; height: 1.253em;\"></span></span></nobr><span role=\"presentation\"><math display=\"inline\" xmlns=\"http://www.w3.org/1998/Math/MathML\"><mi mathvariant=\"script\">O</mi><mrow><mo stretchy=\"false\">(</mo><msup><mi>N</mi><mn>5</mn></msup><mo stretchy=\"false\">)</mo></mrow></math></span></span><script type=\"math/mml\"><math display=\"inline\"><mi mathvariant=\"script\">O</mi><mrow><mo stretchy=\"false\">(</mo><msup><mi>N</mi><mn>5</mn></msup><mo stretchy=\"false\">)</mo></mrow></math></script> energy reduction step, capable of sustaining near-peak performance on clusters with several hundred GPUs. Comparative analysis shows our implementation outperforms state-of-the-art quantum chemistry software by over 3.5 times in speed while achieving an 8-fold reduction in computational power consumption. Benchmarking on the Perlmutter supercomputer, our algorithm achieves 11.8 PFLOP/s (83% of peak performance) performing and the RI-MP2 energy calculation on a 314-water cluster with 7850 primary and 30,144 auxiliary basis functions in 4 min on 180 nodes and 720 A100 GPUs. This performance represents a substantial improvement over traditional CPU-based methods, demonstrating significant time-to-solution and power consumption benefits of leveraging modern GPU-accelerated computing environments for quantum chemistry calculations.","PeriodicalId":45,"journal":{"name":"Journal of Chemical Theory and Computation","volume":null,"pages":null},"PeriodicalIF":5.7000,"publicationDate":"2024-10-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"An Efficient RI-MP2 Algorithm for Distributed Many-GPU Architectures\",\"authors\":\"Calum Snowdon, Giuseppe M. J. Barca\",\"doi\":\"10.1021/acs.jctc.4c00814\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Second-order Møller–Plesset perturbation theory (MP2) using the Resolution of the Identity approximation (RI-MP2) is a widely used method for computing molecular energies beyond the Hartree–Fock mean-field approximation. However, its high computational cost and lack of efficient algorithms for modern supercomputing architectures limit its applicability to large molecules. In this paper, we present the first distributed-memory many-GPU RI-MP2 algorithm explicitly designed to utilize hundreds of GPU accelerators for every step of the computation. Our novel algorithm achieves near-peak performance on GPU-based supercomputers through the development of a distributed memory algorithm for forming RI-MP2 intermediate tensors with zero internode communication, except for a single <i></i><span style=\\\"color: inherit;\\\"></span><span data-mathml='<math xmlns=\\\"http://www.w3.org/1998/Math/MathML\\\" display=\\\"inline\\\"><mi mathvariant=\\\"script\\\">O</mi><mrow><mo stretchy=\\\"false\\\">(</mo><msup><mi>N</mi><mn>2</mn></msup><mo stretchy=\\\"false\\\">)</mo></mrow></math>' role=\\\"presentation\\\" style=\\\"position: relative;\\\" tabindex=\\\"0\\\"><nobr aria-hidden=\\\"true\\\"><span style=\\\"width: 3.071em; display: inline-block;\\\"><span style=\\\"display: inline-block; position: relative; width: 2.787em; height: 0px; font-size: 110%;\\\"><span style=\\\"position: absolute; clip: rect(1.537em, 1002.73em, 2.901em, -999.997em); top: -2.554em; left: 0em;\\\"><span><span style=\\\"font-family: STIXMathJax_Script-italic;\\\">𝒪</span><span><span style=\\\"font-family: STIXMathJax_Main;\\\">(</span><span><span style=\\\"display: inline-block; position: relative; width: 1.423em; height: 0px;\\\"><span style=\\\"position: absolute; clip: rect(3.185em, 1000.91em, 4.151em, -999.997em); top: -3.974em; left: 0em;\\\"><span style=\\\"font-family: STIXMathJax_Normal-italic;\\\">𝑁<span style=\\\"display: inline-block; overflow: hidden; height: 1px; width: 0.06em;\\\"></span></span><span style=\\\"display: inline-block; width: 0px; height: 3.98em;\\\"></span></span><span style=\\\"position: absolute; top: -4.315em; left: 0.969em;\\\"><span style=\\\"font-size: 70.7%; font-family: STIXMathJax_Main;\\\">2</span><span style=\\\"display: inline-block; width: 0px; height: 3.98em;\\\"></span></span></span></span><span style=\\\"font-family: STIXMathJax_Main;\\\">)</span></span></span><span style=\\\"display: inline-block; width: 0px; height: 2.56em;\\\"></span></span></span><span style=\\\"display: inline-block; overflow: hidden; vertical-align: -0.247em; border-left: 0px solid; width: 0px; height: 1.253em;\\\"></span></span></nobr><span role=\\\"presentation\\\"><math display=\\\"inline\\\" xmlns=\\\"http://www.w3.org/1998/Math/MathML\\\"><mi mathvariant=\\\"script\\\">O</mi><mrow><mo stretchy=\\\"false\\\">(</mo><msup><mi>N</mi><mn>2</mn></msup><mo stretchy=\\\"false\\\">)</mo></mrow></math></span></span><script type=\\\"math/mml\\\"><math display=\\\"inline\\\"><mi mathvariant=\\\"script\\\">O</mi><mrow><mo stretchy=\\\"false\\\">(</mo><msup><mi>N</mi><mn>2</mn></msup><mo stretchy=\\\"false\\\">)</mo></mrow></math></script> asynchronous broadcast, and a distributed memory algorithm for the <i></i><span style=\\\"color: inherit;\\\"></span><span data-mathml='<math xmlns=\\\"http://www.w3.org/1998/Math/MathML\\\" display=\\\"inline\\\"><mi mathvariant=\\\"script\\\">O</mi><mrow><mo stretchy=\\\"false\\\">(</mo><msup><mi>N</mi><mn>5</mn></msup><mo stretchy=\\\"false\\\">)</mo></mrow></math>' role=\\\"presentation\\\" style=\\\"position: relative;\\\" tabindex=\\\"0\\\"><nobr aria-hidden=\\\"true\\\"><span style=\\\"width: 3.071em; display: inline-block;\\\"><span style=\\\"display: inline-block; position: relative; width: 2.787em; height: 0px; font-size: 110%;\\\"><span style=\\\"position: absolute; clip: rect(1.537em, 1002.73em, 2.901em, -999.997em); top: -2.554em; left: 0em;\\\"><span><span style=\\\"font-family: STIXMathJax_Script-italic;\\\">𝒪</span><span><span style=\\\"font-family: STIXMathJax_Main;\\\">(</span><span><span style=\\\"display: inline-block; position: relative; width: 1.423em; height: 0px;\\\"><span style=\\\"position: absolute; clip: rect(3.185em, 1000.91em, 4.151em, -999.997em); top: -3.974em; left: 0em;\\\"><span style=\\\"font-family: STIXMathJax_Normal-italic;\\\">𝑁<span style=\\\"display: inline-block; overflow: hidden; height: 1px; width: 0.06em;\\\"></span></span><span style=\\\"display: inline-block; width: 0px; height: 3.98em;\\\"></span></span><span style=\\\"position: absolute; top: -4.315em; left: 0.969em;\\\"><span style=\\\"font-size: 70.7%; font-family: STIXMathJax_Main;\\\">5</span><span style=\\\"display: inline-block; width: 0px; height: 3.98em;\\\"></span></span></span></span><span style=\\\"font-family: STIXMathJax_Main;\\\">)</span></span></span><span style=\\\"display: inline-block; width: 0px; height: 2.56em;\\\"></span></span></span><span style=\\\"display: inline-block; overflow: hidden; vertical-align: -0.247em; border-left: 0px solid; width: 0px; height: 1.253em;\\\"></span></span></nobr><span role=\\\"presentation\\\"><math display=\\\"inline\\\" xmlns=\\\"http://www.w3.org/1998/Math/MathML\\\"><mi mathvariant=\\\"script\\\">O</mi><mrow><mo stretchy=\\\"false\\\">(</mo><msup><mi>N</mi><mn>5</mn></msup><mo stretchy=\\\"false\\\">)</mo></mrow></math></span></span><script type=\\\"math/mml\\\"><math display=\\\"inline\\\"><mi mathvariant=\\\"script\\\">O</mi><mrow><mo stretchy=\\\"false\\\">(</mo><msup><mi>N</mi><mn>5</mn></msup><mo stretchy=\\\"false\\\">)</mo></mrow></math></script> energy reduction step, capable of sustaining near-peak performance on clusters with several hundred GPUs. Comparative analysis shows our implementation outperforms state-of-the-art quantum chemistry software by over 3.5 times in speed while achieving an 8-fold reduction in computational power consumption. Benchmarking on the Perlmutter supercomputer, our algorithm achieves 11.8 PFLOP/s (83% of peak performance) performing and the RI-MP2 energy calculation on a 314-water cluster with 7850 primary and 30,144 auxiliary basis functions in 4 min on 180 nodes and 720 A100 GPUs. This performance represents a substantial improvement over traditional CPU-based methods, demonstrating significant time-to-solution and power consumption benefits of leveraging modern GPU-accelerated computing environments for quantum chemistry calculations.\",\"PeriodicalId\":45,\"journal\":{\"name\":\"Journal of Chemical Theory and Computation\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":5.7000,\"publicationDate\":\"2024-10-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Chemical Theory and Computation\",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://doi.org/10.1021/acs.jctc.4c00814\",\"RegionNum\":1,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"CHEMISTRY, PHYSICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Chemical Theory and Computation","FirstCategoryId":"92","ListUrlMain":"https://doi.org/10.1021/acs.jctc.4c00814","RegionNum":1,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
引用
批量引用

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


