多模态引导下的视觉字幕语义增强
IF 4.3
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
使用单一模式(如视频剪辑)生成的视频字幕往往存在事件发现不足和场景描述不充分的问题。因此,本文旨在通过整合多模态信息来解决这些问题,从而提高字幕质量。具体来说,我们首先构建了一个多模态数据集,并引入了视频、音频和文本的三元组注释,促进了对不同模态之间关联的全面探索。在此基础上,我们提出探索音频和视觉概念的协同感知,通过结合音频和视觉感知先验,减少基于视觉的基准中字幕的不准确和不完整。为此,我们从视觉和听觉模态中提取有效的语义特征,弥合视听模态与文本之间的语义鸿沟,形成更精确的知识图谱多模态一致性检查和信息剪枝机制。详尽的实验证明,在 ChatGPT 的帮助下,所提出的方法超越了现有方法,并具有良好的通用性。本文章由计算机程序翻译,如有差异,请以英文原文为准。
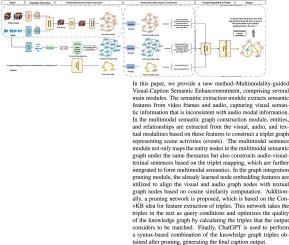
Multimodality-guided Visual-Caption Semantic Enhancement
Video captions generated with single modality, e.g. video clips, often suffer from insufficient event discovery and inadequate scene description. Therefore, this paper aims to improve the quality of captions by addressing these issues through the integration of multi-modal information. Specifically, We first construct a multi-modal dataset and introduce the triplet annotations of video, audio and text, fostering a comprehensive exploration about the associations between different modalities. Build upon this, We propose to explore the collaborative perception of audio and visual concepts to mitigate inaccuracies and incompleteness in captions in vision-based benchmarks by incorporating audio-visual perception priors. To achieve this, we extract effective semantic features from visual and auditory modalities, bridge the semantic gap between audio-visual modalities and text, and form a more precise knowledge graph multimodal coherence checking and information pruning mechanism. Exhaustive experiments demonstrate that the proposed approach surpasses existing methods and generalizes well with the assistance of ChatGPT.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computer Vision and Image Understanding
工程技术-工程:电子与电气
CiteScore
7.80
自引率
4.40%
发文量
112
审稿时长
79 days
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


