Zi-Lin Li, Shuxin Pei, Ziying Chen, Teng-Yu Huang, Xu-Dong Wang, Lin Shen, Xuebo Chen, Qi-Qiang Wang, De-Xian Wang, Yu-Fei Ao
{"title":"机器学习辅助下的氨酶催化对映选择性预测以及提高对映选择性的合理变体设计","authors":"Zi-Lin Li, Shuxin Pei, Ziying Chen, Teng-Yu Huang, Xu-Dong Wang, Lin Shen, Xuebo Chen, Qi-Qiang Wang, De-Xian Wang, Yu-Fei Ao","doi":"10.1038/s41467-024-53048-0","DOIUrl":null,"url":null,"abstract":"<p>Biocatalysis is an attractive approach for the synthesis of chiral pharmaceuticals and fine chemicals, but assessing and/or improving the enantioselectivity of biocatalyst towards target substrates is often time and resource intensive. Although machine learning has been used to reveal the underlying relationship between protein sequences and biocatalytic enantioselectivity, the establishment of substrate fitness space is usually disregarded by chemists and is still a challenge. Using 240 datasets collected in our previous works, we adopt chemistry and geometry descriptors and build random forest classification models for predicting the enantioselectivity of amidase towards new substrates. We further propose a heuristic strategy based on these models, by which the rational protein engineering can be efficiently performed to synthesize chiral compounds with higher ee values, and the optimized variant results in a 53-fold higher <i>E</i>-value comparing to the wild-type amidase. This data-driven methodology is expected to broaden the application of machine learning in biocatalysis research.</p>","PeriodicalId":19066,"journal":{"name":"Nature Communications","volume":"37 1","pages":""},"PeriodicalIF":14.7000,"publicationDate":"2024-10-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Machine learning-assisted amidase-catalytic enantioselectivity prediction and rational design of variants for improving enantioselectivity\",\"authors\":\"Zi-Lin Li, Shuxin Pei, Ziying Chen, Teng-Yu Huang, Xu-Dong Wang, Lin Shen, Xuebo Chen, Qi-Qiang Wang, De-Xian Wang, Yu-Fei Ao\",\"doi\":\"10.1038/s41467-024-53048-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Biocatalysis is an attractive approach for the synthesis of chiral pharmaceuticals and fine chemicals, but assessing and/or improving the enantioselectivity of biocatalyst towards target substrates is often time and resource intensive. Although machine learning has been used to reveal the underlying relationship between protein sequences and biocatalytic enantioselectivity, the establishment of substrate fitness space is usually disregarded by chemists and is still a challenge. Using 240 datasets collected in our previous works, we adopt chemistry and geometry descriptors and build random forest classification models for predicting the enantioselectivity of amidase towards new substrates. We further propose a heuristic strategy based on these models, by which the rational protein engineering can be efficiently performed to synthesize chiral compounds with higher ee values, and the optimized variant results in a 53-fold higher <i>E</i>-value comparing to the wild-type amidase. This data-driven methodology is expected to broaden the application of machine learning in biocatalysis research.</p>\",\"PeriodicalId\":19066,\"journal\":{\"name\":\"Nature Communications\",\"volume\":\"37 1\",\"pages\":\"\"},\"PeriodicalIF\":14.7000,\"publicationDate\":\"2024-10-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Communications\",\"FirstCategoryId\":\"103\",\"ListUrlMain\":\"https://doi.org/10.1038/s41467-024-53048-0\",\"RegionNum\":1,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Communications","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41467-024-53048-0","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
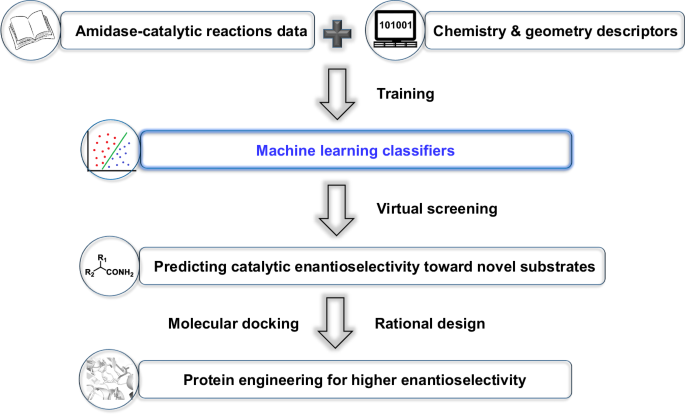
Machine learning-assisted amidase-catalytic enantioselectivity prediction and rational design of variants for improving enantioselectivity
Biocatalysis is an attractive approach for the synthesis of chiral pharmaceuticals and fine chemicals, but assessing and/or improving the enantioselectivity of biocatalyst towards target substrates is often time and resource intensive. Although machine learning has been used to reveal the underlying relationship between protein sequences and biocatalytic enantioselectivity, the establishment of substrate fitness space is usually disregarded by chemists and is still a challenge. Using 240 datasets collected in our previous works, we adopt chemistry and geometry descriptors and build random forest classification models for predicting the enantioselectivity of amidase towards new substrates. We further propose a heuristic strategy based on these models, by which the rational protein engineering can be efficiently performed to synthesize chiral compounds with higher ee values, and the optimized variant results in a 53-fold higher E-value comparing to the wild-type amidase. This data-driven methodology is expected to broaden the application of machine learning in biocatalysis research.
期刊介绍:
Nature Communications, an open-access journal, publishes high-quality research spanning all areas of the natural sciences. Papers featured in the journal showcase significant advances relevant to specialists in each respective field. With a 2-year impact factor of 16.6 (2022) and a median time of 8 days from submission to the first editorial decision, Nature Communications is committed to rapid dissemination of research findings. As a multidisciplinary journal, it welcomes contributions from biological, health, physical, chemical, Earth, social, mathematical, applied, and engineering sciences, aiming to highlight important breakthroughs within each domain.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


