{"title":"大语言人工智能模型在解决修复牙科和牙髓病学学生评估方面的表现。","authors":"Paul Künzle, Sebastian Paris","doi":"10.1007/s00784-024-05968-w","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>The advent of artificial intelligence (AI) and large language model (LLM)-based AI applications (LLMAs) has tremendous implications for our society. This study analyzed the performance of LLMAs on solving restorative dentistry and endodontics (RDE) student assessment questions.</p><p><strong>Materials and methods: </strong>151 questions from a RDE question pool were prepared for prompting using LLMAs from OpenAI (ChatGPT-3.5,-4.0 and -4.0o) and Google (Gemini 1.0). Multiple-choice questions were sorted into four question subcategories, entered into LLMAs and answers recorded for analysis. P-value and chi-square statistical analyses were performed using Python 3.9.16.</p><p><strong>Results: </strong>The total answer accuracy of ChatGPT-4.0o was the highest, followed by ChatGPT-4.0, Gemini 1.0 and ChatGPT-3.5 (72%, 62%, 44% and 25%, respectively) with significant differences between all LLMAs except GPT-4.0 models. The performance on subcategories direct restorations and caries was the highest, followed by indirect restorations and endodontics.</p><p><strong>Conclusions: </strong>Overall, there are large performance differences among LLMAs. Only the ChatGPT-4 models achieved a success ratio that could be used with caution to support the dental academic curriculum.</p><p><strong>Clinical relevance: </strong>While LLMAs could support clinicians to answer dental field-related questions, this capacity depends strongly on the employed model. The most performant model ChatGPT-4.0o achieved acceptable accuracy rates in some subject sub-categories analyzed.</p>","PeriodicalId":10461,"journal":{"name":"Clinical Oral Investigations","volume":"28 11","pages":"575"},"PeriodicalIF":3.1000,"publicationDate":"2024-10-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11458639/pdf/","citationCount":"0","resultStr":"{\"title\":\"Performance of large language artificial intelligence models on solving restorative dentistry and endodontics student assessments.\",\"authors\":\"Paul Künzle, Sebastian Paris\",\"doi\":\"10.1007/s00784-024-05968-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>The advent of artificial intelligence (AI) and large language model (LLM)-based AI applications (LLMAs) has tremendous implications for our society. This study analyzed the performance of LLMAs on solving restorative dentistry and endodontics (RDE) student assessment questions.</p><p><strong>Materials and methods: </strong>151 questions from a RDE question pool were prepared for prompting using LLMAs from OpenAI (ChatGPT-3.5,-4.0 and -4.0o) and Google (Gemini 1.0). Multiple-choice questions were sorted into four question subcategories, entered into LLMAs and answers recorded for analysis. P-value and chi-square statistical analyses were performed using Python 3.9.16.</p><p><strong>Results: </strong>The total answer accuracy of ChatGPT-4.0o was the highest, followed by ChatGPT-4.0, Gemini 1.0 and ChatGPT-3.5 (72%, 62%, 44% and 25%, respectively) with significant differences between all LLMAs except GPT-4.0 models. The performance on subcategories direct restorations and caries was the highest, followed by indirect restorations and endodontics.</p><p><strong>Conclusions: </strong>Overall, there are large performance differences among LLMAs. Only the ChatGPT-4 models achieved a success ratio that could be used with caution to support the dental academic curriculum.</p><p><strong>Clinical relevance: </strong>While LLMAs could support clinicians to answer dental field-related questions, this capacity depends strongly on the employed model. The most performant model ChatGPT-4.0o achieved acceptable accuracy rates in some subject sub-categories analyzed.</p>\",\"PeriodicalId\":10461,\"journal\":{\"name\":\"Clinical Oral Investigations\",\"volume\":\"28 11\",\"pages\":\"575\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-10-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11458639/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Clinical Oral Investigations\",\"FirstCategoryId\":\"88\",\"ListUrlMain\":\"https://doi.org/10.1007/s00784-024-05968-w\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"DENTISTRY, ORAL SURGERY & MEDICINE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Clinical Oral Investigations","FirstCategoryId":"88","ListUrlMain":"https://doi.org/10.1007/s00784-024-05968-w","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"DENTISTRY, ORAL SURGERY & MEDICINE","Score":null,"Total":0}
Performance of large language artificial intelligence models on solving restorative dentistry and endodontics student assessments.
Objectives: The advent of artificial intelligence (AI) and large language model (LLM)-based AI applications (LLMAs) has tremendous implications for our society. This study analyzed the performance of LLMAs on solving restorative dentistry and endodontics (RDE) student assessment questions.
Materials and methods: 151 questions from a RDE question pool were prepared for prompting using LLMAs from OpenAI (ChatGPT-3.5,-4.0 and -4.0o) and Google (Gemini 1.0). Multiple-choice questions were sorted into four question subcategories, entered into LLMAs and answers recorded for analysis. P-value and chi-square statistical analyses were performed using Python 3.9.16.
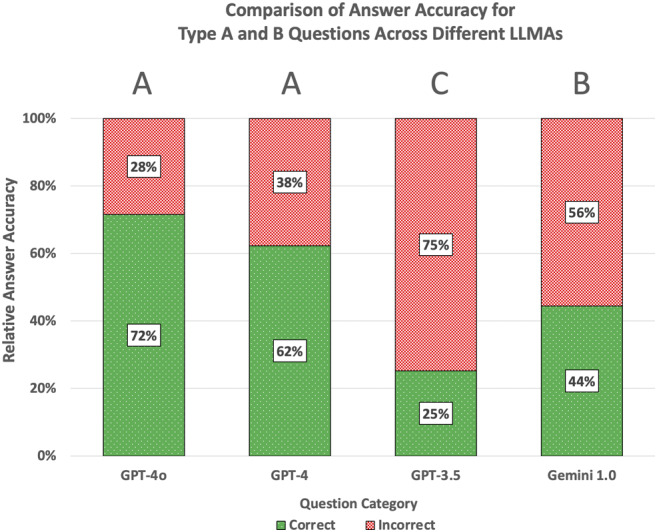
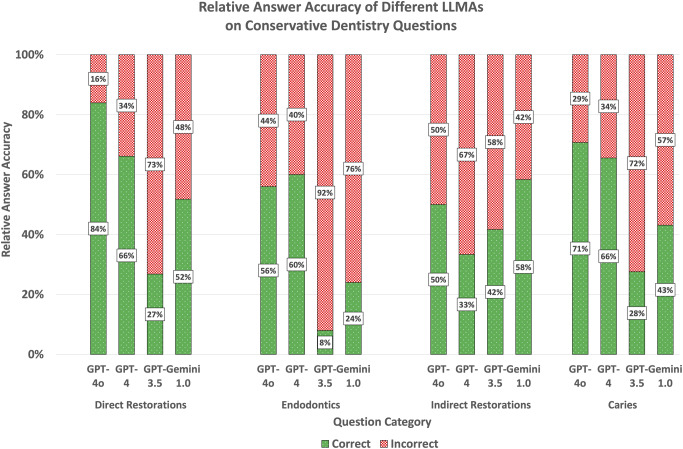
Results: The total answer accuracy of ChatGPT-4.0o was the highest, followed by ChatGPT-4.0, Gemini 1.0 and ChatGPT-3.5 (72%, 62%, 44% and 25%, respectively) with significant differences between all LLMAs except GPT-4.0 models. The performance on subcategories direct restorations and caries was the highest, followed by indirect restorations and endodontics.
Conclusions: Overall, there are large performance differences among LLMAs. Only the ChatGPT-4 models achieved a success ratio that could be used with caution to support the dental academic curriculum.
Clinical relevance: While LLMAs could support clinicians to answer dental field-related questions, this capacity depends strongly on the employed model. The most performant model ChatGPT-4.0o achieved acceptable accuracy rates in some subject sub-categories analyzed.
期刊介绍:
The journal Clinical Oral Investigations is a multidisciplinary, international forum for publication of research from all fields of oral medicine. The journal publishes original scientific articles and invited reviews which provide up-to-date results of basic and clinical studies in oral and maxillofacial science and medicine. The aim is to clarify the relevance of new results to modern practice, for an international readership. Coverage includes maxillofacial and oral surgery, prosthetics and restorative dentistry, operative dentistry, endodontics, periodontology, orthodontics, dental materials science, clinical trials, epidemiology, pedodontics, oral implant, preventive dentistiry, oral pathology, oral basic sciences and more.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


