MoMa:利用蒙皮姿势建模进行蒙皮运动重定位
IF 3.5
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
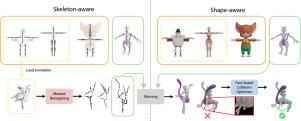
运动重定位需要仔细分析源角色和目标角色在骨骼结构和身体形状上的差异。现有的骨骼感知和形状感知方法可以处理这种差异,但当源角色和目标角色在骨骼(如关节数量和骨骼长度)和形状(如几何形状和网格属性)方面表现出显著差异时,这些方法就会陷入困境。在这项工作中,我们引入了 MoMa,这是一种用于带皮肤运动重定位的新方法,同时具有骨架和形状感知功能。我们的骨骼感知模块通过使用基于自定义变换器的自动编码器和时空遮蔽策略来恢复源和目标之间的差异,从而学会重定向动画。自动编码器以共享关节为参考点,通过重建被掩盖的骨骼差异,在输入骨骼和目标骨骼之间传递运动。我们突破了以往方法的限制,还能在具有不同数量叶关节的骨骼之间执行重定位。我们的形状感知模块包含一个新颖的基于脸部的优化器,可调整骨骼位置以限制身体部位之间的碰撞。与传统的基于顶点的方法相比,我们的基于面的优化器在解决身体形状内的表面碰撞方面表现出色,从而实现了更精确的重定向运动。在 Mixamo 数据集上,所提出的架构在定量和定性方面都优于最先进的结果。我们的代码可在[Github 链接,请参见补充材料]。本文章由计算机程序翻译,如有差异,请以英文原文为准。
MoMa: Skinned motion retargeting using masked pose modeling
Motion retargeting requires to carefully analyze the differences in both skeletal structure and body shape between source and target characters. Existing skeleton-aware and shape-aware approaches can deal with such differences, but they struggle when the source and target characters exhibit significant dissimilarities in both skeleton (like joint count and bone length) and shape (like geometry and mesh properties). In this work we introduce MoMa, a novel approach for skinned motion retargeting which is both skeleton and shape-aware. Our skeleton-aware module learns to retarget animations by recovering the differences between source and target using a custom transformer-based auto-encoder coupled with a spatio-temporal masking strategy. The auto-encoder can transfer the motion between input and target skeletons by reconstructing the masked skeletal differences using shared joints as a reference point. Surpassing the limitations of previous approaches, we can also perform retargeting between skeletons with a varying number of leaf joints. Our shape-aware module incorporates a novel face-based optimizer that adapts skeleton positions to limit collisions between body parts. In contrast to conventional vertex-based methods, our face-based optimizer excels in resolving surface collisions within a body shape, resulting in more accurate retargeted motions. The proposed architecture outperforms the state-of-the-art results on the Mixamo dataset, both quantitatively and qualitatively. Our code is available at: [Github link upon acceptance, see supplementary materials].
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computer Vision and Image Understanding
工程技术-工程:电子与电气
CiteScore
7.80
自引率
4.40%
发文量
112
审稿时长
79 days
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


