{"title":"用于患者分诊的 ChatGPT 的诊断准确性;系统回顾和 Meta 分析。","authors":"Navid Kaboudi, Saeedeh Firouzbakht, Mohammad Shahir Eftekhar, Fatemeh Fayazbakhsh, Niloufar Joharivarnoosfaderani, Salar Ghaderi, Mohammadreza Dehdashti, Yasmin Mohtasham Kia, Maryam Afshari, Maryam Vasaghi-Gharamaleki, Leila Haghani, Zahra Moradzadeh, Fattaneh Khalaj, Zahra Mohammadi, Zahra Hasanabadi, Ramin Shahidi","doi":"10.22037/aaem.v12i1.2384","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Artificial intelligence (AI), particularly ChatGPT developed by OpenAI, has shown the potential to improve diagnostic accuracy and efficiency in emergency department (ED) triage. This study aims to evaluate the diagnostic performance and safety of ChatGPT in prioritizing patients based on urgency in ED settings.</p><p><strong>Methods: </strong>A systematic review and meta-analysis were conducted following PRISMA guidelines. Comprehensive literature searches were performed in Scopus, Web of Science, PubMed, and Embase. Studies evaluating ChatGPT's diagnostic performance in ED triage were included. Quality assessment was conducted using the QUADAS-2 tool. Pooled accuracy estimates were calculated using a random-effects model, and heterogeneity was assessed with the I² statistic.</p><p><strong>Results: </strong>Fourteen studies with a total of 1,412 patients or scenarios were included. ChatGPT 4.0 demonstrated a pooled accuracy of 0.86 (95% CI: 0.64-0.98) with substantial heterogeneity (I² = 93%). ChatGPT 3.5 showed a pooled accuracy of 0.63 (95% CI: 0.43-0.81) with significant heterogeneity (I² = 84%). Funnel plots indicated potential publication bias, particularly for ChatGPT 3.5. Quality assessments revealed varying levels of risk of bias and applicability concerns.</p><p><strong>Conclusion: </strong>ChatGPT, especially version 4.0, shows promise in improving ED triage accuracy. However, significant variability and potential biases highlight the need for further evaluation and enhancement.</p>","PeriodicalId":8146,"journal":{"name":"Archives of Academic Emergency Medicine","volume":"12 1","pages":"e60"},"PeriodicalIF":2.0000,"publicationDate":"2024-07-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11407534/pdf/","citationCount":"0","resultStr":"{\"title\":\"Diagnostic Accuracy of ChatGPT for Patients' Triage; a Systematic Review and Meta-Analysis.\",\"authors\":\"Navid Kaboudi, Saeedeh Firouzbakht, Mohammad Shahir Eftekhar, Fatemeh Fayazbakhsh, Niloufar Joharivarnoosfaderani, Salar Ghaderi, Mohammadreza Dehdashti, Yasmin Mohtasham Kia, Maryam Afshari, Maryam Vasaghi-Gharamaleki, Leila Haghani, Zahra Moradzadeh, Fattaneh Khalaj, Zahra Mohammadi, Zahra Hasanabadi, Ramin Shahidi\",\"doi\":\"10.22037/aaem.v12i1.2384\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Artificial intelligence (AI), particularly ChatGPT developed by OpenAI, has shown the potential to improve diagnostic accuracy and efficiency in emergency department (ED) triage. This study aims to evaluate the diagnostic performance and safety of ChatGPT in prioritizing patients based on urgency in ED settings.</p><p><strong>Methods: </strong>A systematic review and meta-analysis were conducted following PRISMA guidelines. Comprehensive literature searches were performed in Scopus, Web of Science, PubMed, and Embase. Studies evaluating ChatGPT's diagnostic performance in ED triage were included. Quality assessment was conducted using the QUADAS-2 tool. Pooled accuracy estimates were calculated using a random-effects model, and heterogeneity was assessed with the I² statistic.</p><p><strong>Results: </strong>Fourteen studies with a total of 1,412 patients or scenarios were included. ChatGPT 4.0 demonstrated a pooled accuracy of 0.86 (95% CI: 0.64-0.98) with substantial heterogeneity (I² = 93%). ChatGPT 3.5 showed a pooled accuracy of 0.63 (95% CI: 0.43-0.81) with significant heterogeneity (I² = 84%). Funnel plots indicated potential publication bias, particularly for ChatGPT 3.5. Quality assessments revealed varying levels of risk of bias and applicability concerns.</p><p><strong>Conclusion: </strong>ChatGPT, especially version 4.0, shows promise in improving ED triage accuracy. However, significant variability and potential biases highlight the need for further evaluation and enhancement.</p>\",\"PeriodicalId\":8146,\"journal\":{\"name\":\"Archives of Academic Emergency Medicine\",\"volume\":\"12 1\",\"pages\":\"e60\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2024-07-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11407534/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Archives of Academic Emergency Medicine\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.22037/aaem.v12i1.2384\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"EMERGENCY MEDICINE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Archives of Academic Emergency Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.22037/aaem.v12i1.2384","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"EMERGENCY MEDICINE","Score":null,"Total":0}
Diagnostic Accuracy of ChatGPT for Patients' Triage; a Systematic Review and Meta-Analysis.
Introduction: Artificial intelligence (AI), particularly ChatGPT developed by OpenAI, has shown the potential to improve diagnostic accuracy and efficiency in emergency department (ED) triage. This study aims to evaluate the diagnostic performance and safety of ChatGPT in prioritizing patients based on urgency in ED settings.
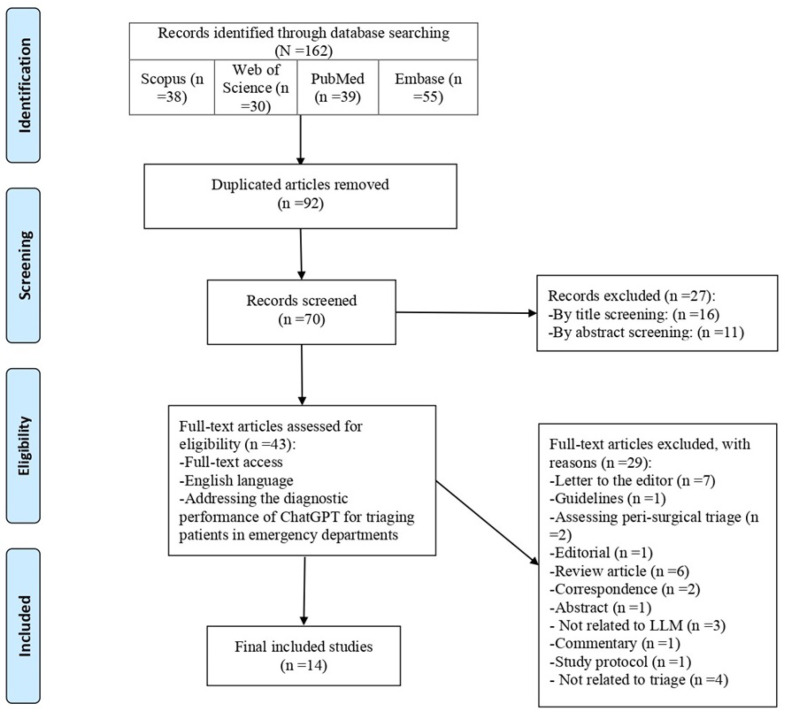
Methods: A systematic review and meta-analysis were conducted following PRISMA guidelines. Comprehensive literature searches were performed in Scopus, Web of Science, PubMed, and Embase. Studies evaluating ChatGPT's diagnostic performance in ED triage were included. Quality assessment was conducted using the QUADAS-2 tool. Pooled accuracy estimates were calculated using a random-effects model, and heterogeneity was assessed with the I² statistic.
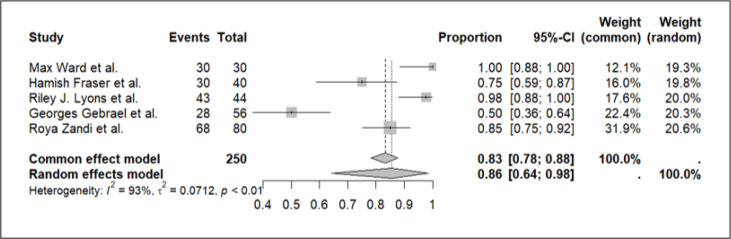
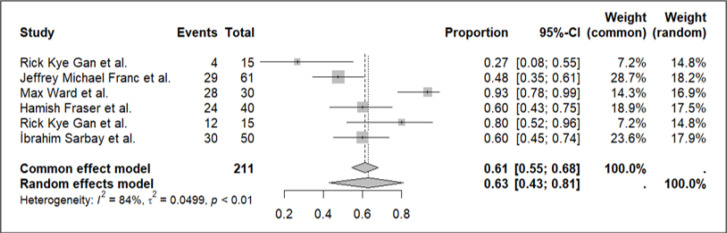
Results: Fourteen studies with a total of 1,412 patients or scenarios were included. ChatGPT 4.0 demonstrated a pooled accuracy of 0.86 (95% CI: 0.64-0.98) with substantial heterogeneity (I² = 93%). ChatGPT 3.5 showed a pooled accuracy of 0.63 (95% CI: 0.43-0.81) with significant heterogeneity (I² = 84%). Funnel plots indicated potential publication bias, particularly for ChatGPT 3.5. Quality assessments revealed varying levels of risk of bias and applicability concerns.
Conclusion: ChatGPT, especially version 4.0, shows promise in improving ED triage accuracy. However, significant variability and potential biases highlight the need for further evaluation and enhancement.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


