{"title":"整合先验知识和数据驱动方法,改进韩语中的词素到音素转换","authors":"Dezhi Cao, Yue Zhao, Licheng Wu","doi":"10.1007/s00500-024-09934-2","DOIUrl":null,"url":null,"abstract":"<p>Grapheme-to-phoneme (G2P) conversion technology is currently dominated by two methodologies: knowledge-based and data-based approaches. Knowledge-driven methods struggle to adapt to extensive datasets, while data-driven methods rely heavily on high-quality data and require precise feature selection for model construction. To address these challenges, this research aims to propose an integrated approach that combines prior knowledge with data-driven techniques for automatic G2P conversion in the Korean language. In this work, we extract attributes based on pronunciation rules and phonetic transformations between Korean words to construct a decision tree. Subsequently, the model is trained using a data-driven approach for automated phonetic transcription. The proposed integrated model achieves more accurate alignment between input and output variables, effectively capturing phonological variations in continuous Korean speech, and determining corresponding phonemes for graphemes. Rigorous cross-validation confirms its superiority, with an average accuracy of 94.63% in grapheme-to-phoneme conversion, outperforming existing methodologies. In conclusion, this research demonstrates the effectiveness of an integrated approach combining prior knowledge and data-driven techniques for G2P conversion in Korean. The high accuracy and performance of this method are significant for Korean G2P. Our approach can also be applied to low-resource or endangered languages that already have some linguistic research foundation to improve the accuracy of the pronunciation lexicon of the language.</p>","PeriodicalId":22039,"journal":{"name":"Soft Computing","volume":"26 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-08-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Integrating prior knowledge and data-driven approaches for improving grapheme-to-phoneme conversion in Korean language\",\"authors\":\"Dezhi Cao, Yue Zhao, Licheng Wu\",\"doi\":\"10.1007/s00500-024-09934-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Grapheme-to-phoneme (G2P) conversion technology is currently dominated by two methodologies: knowledge-based and data-based approaches. Knowledge-driven methods struggle to adapt to extensive datasets, while data-driven methods rely heavily on high-quality data and require precise feature selection for model construction. To address these challenges, this research aims to propose an integrated approach that combines prior knowledge with data-driven techniques for automatic G2P conversion in the Korean language. In this work, we extract attributes based on pronunciation rules and phonetic transformations between Korean words to construct a decision tree. Subsequently, the model is trained using a data-driven approach for automated phonetic transcription. The proposed integrated model achieves more accurate alignment between input and output variables, effectively capturing phonological variations in continuous Korean speech, and determining corresponding phonemes for graphemes. Rigorous cross-validation confirms its superiority, with an average accuracy of 94.63% in grapheme-to-phoneme conversion, outperforming existing methodologies. In conclusion, this research demonstrates the effectiveness of an integrated approach combining prior knowledge and data-driven techniques for G2P conversion in Korean. The high accuracy and performance of this method are significant for Korean G2P. Our approach can also be applied to low-resource or endangered languages that already have some linguistic research foundation to improve the accuracy of the pronunciation lexicon of the language.</p>\",\"PeriodicalId\":22039,\"journal\":{\"name\":\"Soft Computing\",\"volume\":\"26 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-08-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Soft Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00500-024-09934-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Soft Computing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00500-024-09934-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Integrating prior knowledge and data-driven approaches for improving grapheme-to-phoneme conversion in Korean language
Grapheme-to-phoneme (G2P) conversion technology is currently dominated by two methodologies: knowledge-based and data-based approaches. Knowledge-driven methods struggle to adapt to extensive datasets, while data-driven methods rely heavily on high-quality data and require precise feature selection for model construction. To address these challenges, this research aims to propose an integrated approach that combines prior knowledge with data-driven techniques for automatic G2P conversion in the Korean language. In this work, we extract attributes based on pronunciation rules and phonetic transformations between Korean words to construct a decision tree. Subsequently, the model is trained using a data-driven approach for automated phonetic transcription. The proposed integrated model achieves more accurate alignment between input and output variables, effectively capturing phonological variations in continuous Korean speech, and determining corresponding phonemes for graphemes. Rigorous cross-validation confirms its superiority, with an average accuracy of 94.63% in grapheme-to-phoneme conversion, outperforming existing methodologies. In conclusion, this research demonstrates the effectiveness of an integrated approach combining prior knowledge and data-driven techniques for G2P conversion in Korean. The high accuracy and performance of this method are significant for Korean G2P. Our approach can also be applied to low-resource or endangered languages that already have some linguistic research foundation to improve the accuracy of the pronunciation lexicon of the language.
期刊介绍:
Soft Computing is dedicated to system solutions based on soft computing techniques. It provides rapid dissemination of important results in soft computing technologies, a fusion of research in evolutionary algorithms and genetic programming, neural science and neural net systems, fuzzy set theory and fuzzy systems, and chaos theory and chaotic systems.
Soft Computing encourages the integration of soft computing techniques and tools into both everyday and advanced applications. By linking the ideas and techniques of soft computing with other disciplines, the journal serves as a unifying platform that fosters comparisons, extensions, and new applications. As a result, the journal is an international forum for all scientists and engineers engaged in research and development in this fast growing field.
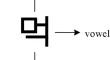

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


