Xiao Wang, Shuang Liang, Wenqi Yang, Ke Yu, Fei Liang, Bing Zhao, Xiang Zhu, Chao Zhou, Luis A. J. Mur, Jeremy A. Roberts, Junli Zhang, Xuebin Zhang
{"title":"MetMiner:用于大规模植物代谢组学数据分析的用户友好型管道","authors":"Xiao Wang, Shuang Liang, Wenqi Yang, Ke Yu, Fei Liang, Bing Zhao, Xiang Zhu, Chao Zhou, Luis A. J. Mur, Jeremy A. Roberts, Junli Zhang, Xuebin Zhang","doi":"10.1111/jipb.13774","DOIUrl":null,"url":null,"abstract":"<p>The utilization of metabolomics approaches to explore the metabolic mechanisms underlying plant fitness and adaptation to dynamic environments is growing, highlighting the need for an efficient and user-friendly toolkit tailored for analyzing the extensive datasets generated by metabolomics studies. Current protocols for metabolome data analysis often struggle with handling large-scale datasets or require programming skills. To address this, we present MetMiner (https://github.com/ShawnWx2019/MetMiner), a user-friendly, full-functionality pipeline specifically designed for plant metabolomics data analysis. Built on R shiny, MetMiner can be deployed on servers to utilize additional computational resources for processing large-scale datasets. MetMiner ensures transparency, traceability, and reproducibility throughout the analytical process. Its intuitive interface provides robust data interaction and graphical capabilities, enabling users without prior programming skills to engage deeply in data analysis. Additionally, we constructed and integrated a plant-specific mass spectrometry database into the MetMiner pipeline to optimize metabolite annotation. We have also developed MDAtoolkits, which include a complete set of tools for statistical analysis, metabolite classification, and enrichment analysis, to facilitate the mining of biological meaning from the datasets. Moreover, we propose an iterative weighted gene co-expression network analysis strategy for efficient biomarker metabolite screening in large-scale metabolomics data mining. In two case studies, we validated MetMiner's efficiency in data mining and robustness in metabolite annotation. Together, the MetMiner pipeline represents a promising solution for plant metabolomics analysis, providing a valuable tool for the scientific community to use with ease.</p>","PeriodicalId":195,"journal":{"name":"Journal of Integrative Plant Biology","volume":"66 11","pages":"2329-2345"},"PeriodicalIF":9.3000,"publicationDate":"2024-09-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/jipb.13774","citationCount":"0","resultStr":"{\"title\":\"MetMiner: A user-friendly pipeline for large-scale plant metabolomics data analysis\",\"authors\":\"Xiao Wang, Shuang Liang, Wenqi Yang, Ke Yu, Fei Liang, Bing Zhao, Xiang Zhu, Chao Zhou, Luis A. J. Mur, Jeremy A. Roberts, Junli Zhang, Xuebin Zhang\",\"doi\":\"10.1111/jipb.13774\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The utilization of metabolomics approaches to explore the metabolic mechanisms underlying plant fitness and adaptation to dynamic environments is growing, highlighting the need for an efficient and user-friendly toolkit tailored for analyzing the extensive datasets generated by metabolomics studies. Current protocols for metabolome data analysis often struggle with handling large-scale datasets or require programming skills. To address this, we present MetMiner (https://github.com/ShawnWx2019/MetMiner), a user-friendly, full-functionality pipeline specifically designed for plant metabolomics data analysis. Built on R shiny, MetMiner can be deployed on servers to utilize additional computational resources for processing large-scale datasets. MetMiner ensures transparency, traceability, and reproducibility throughout the analytical process. Its intuitive interface provides robust data interaction and graphical capabilities, enabling users without prior programming skills to engage deeply in data analysis. Additionally, we constructed and integrated a plant-specific mass spectrometry database into the MetMiner pipeline to optimize metabolite annotation. We have also developed MDAtoolkits, which include a complete set of tools for statistical analysis, metabolite classification, and enrichment analysis, to facilitate the mining of biological meaning from the datasets. Moreover, we propose an iterative weighted gene co-expression network analysis strategy for efficient biomarker metabolite screening in large-scale metabolomics data mining. In two case studies, we validated MetMiner's efficiency in data mining and robustness in metabolite annotation. Together, the MetMiner pipeline represents a promising solution for plant metabolomics analysis, providing a valuable tool for the scientific community to use with ease.</p>\",\"PeriodicalId\":195,\"journal\":{\"name\":\"Journal of Integrative Plant Biology\",\"volume\":\"66 11\",\"pages\":\"2329-2345\"},\"PeriodicalIF\":9.3000,\"publicationDate\":\"2024-09-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/jipb.13774\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Integrative Plant Biology\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/jipb.13774\",\"RegionNum\":1,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Integrative Plant Biology","FirstCategoryId":"99","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/jipb.13774","RegionNum":1,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
MetMiner: A user-friendly pipeline for large-scale plant metabolomics data analysis
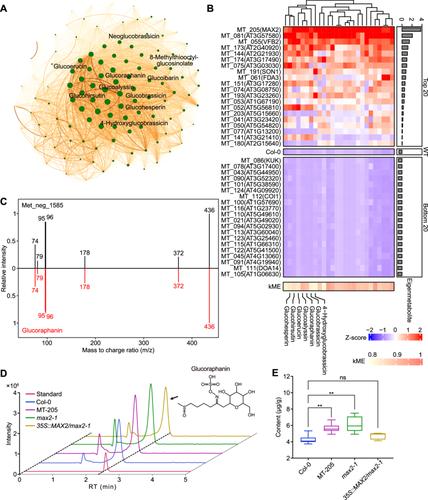
The utilization of metabolomics approaches to explore the metabolic mechanisms underlying plant fitness and adaptation to dynamic environments is growing, highlighting the need for an efficient and user-friendly toolkit tailored for analyzing the extensive datasets generated by metabolomics studies. Current protocols for metabolome data analysis often struggle with handling large-scale datasets or require programming skills. To address this, we present MetMiner (https://github.com/ShawnWx2019/MetMiner), a user-friendly, full-functionality pipeline specifically designed for plant metabolomics data analysis. Built on R shiny, MetMiner can be deployed on servers to utilize additional computational resources for processing large-scale datasets. MetMiner ensures transparency, traceability, and reproducibility throughout the analytical process. Its intuitive interface provides robust data interaction and graphical capabilities, enabling users without prior programming skills to engage deeply in data analysis. Additionally, we constructed and integrated a plant-specific mass spectrometry database into the MetMiner pipeline to optimize metabolite annotation. We have also developed MDAtoolkits, which include a complete set of tools for statistical analysis, metabolite classification, and enrichment analysis, to facilitate the mining of biological meaning from the datasets. Moreover, we propose an iterative weighted gene co-expression network analysis strategy for efficient biomarker metabolite screening in large-scale metabolomics data mining. In two case studies, we validated MetMiner's efficiency in data mining and robustness in metabolite annotation. Together, the MetMiner pipeline represents a promising solution for plant metabolomics analysis, providing a valuable tool for the scientific community to use with ease.
期刊介绍:
Journal of Integrative Plant Biology is a leading academic journal reporting on the latest discoveries in plant biology.Enjoy the latest news and developments in the field, understand new and improved methods and research tools, and explore basic biological questions through reproducible experimental design, using genetic, biochemical, cell and molecular biological methods, and statistical analyses.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


