{"title":"如何将高维数据可视化。","authors":"Ralf Mrowka, Ralf Schmauder","doi":"10.1111/apha.14219","DOIUrl":null,"url":null,"abstract":"<p>Recently, a colleague asked after a lecture about a fancy diagram where the axis designation was not clear to him and the discussion about that raised a few interesting thoughts about that specific matter. Physiological knowledge is often taught at university seminars and in textbooks with the help of diagrams. A very important first step when discussing diagrams is to clarify which physical, physiological variable at what scale and unit is represented on which axis. Examples of typical classical low dimensional diagrams in physiology publications in Acta Physiologica might be blood pressure over time,<span><sup>1</sup></span> infarct size as percentage of Left ventricular mass depending on genotype<span><sup>2</sup></span> or urine excretion in volume per time depending on diet.<span><sup>3</sup></span> Not knowing the axes of the classical diagrams, they might as well be “just” pieces of fancy modern art.</p><p>We strongly believe that graphical representation of complex data—for example, as diagrams—is essential in communicating them. However, for specific types of diagrams, the understanding and interpretation of their content is more complex, and requires more explanation than classical diagrams. Specifically, we refer to the graphical representation of high-dimensional data, which have, in recent years, played an increasing role in new understandings of physiological processes.</p><p>To visualize data a reduction of dimensionality is often applied. A simple example is a black/white photograph of a colorful moving three dimensional object. The snapshot “eliminated” the dimension time and the optical projection on a plane in the camera eliminated one dimension in space and the gray values just reduced the spectral information to an intensity value on the photograph. Although the photograph does not represent the compete “dataset” it gives us in most cases a good impression about the situation captured by the photographer.</p><p>Times have changed.</p><p>To describe the “amount” of data obtained for a study in the 1960s one physiologist for example referred to the length of the paper of plots of curved of blood pressure measurements he was analyzing for one particular study. Compared with that amount of data back then we are nowadays faced with a completely new situation. With the development of technology we have to handle a huge amount of data today. For example, in recent studies with single RNAseq data scientists obtained with thousands of expression values for single genes for each of thousands of single cells at multiple experimental points and possibly for multiple interventions. Obviously you cannot produce a meaningful simple classical plot with thousands of dimensions.</p><p>In order to make sense out of the hugely dimensional data, researches can employ methods for the reduction of dimensionality. One classical methods would be to employ the so called principal component analysis (PCA). This linear method projects the data onto a new coordinate system where the axes (principal components) are the directions of maximum variance. Without diving too deep into the mathematics, this is done by calculating the so called eigenvectors of the data matrix.</p><p>It turned out that this PCA method with its linear transformation is not sufficient in the above described case. Here new statistical approaches for nonlinear dimensionality reduction have been developed. One is the so called t-Distributed Stochastic Neighbor Embedding (t-SNE) method<span><sup>4</sup></span> and later a kind of improved version of this is the so called Uniform Manifold Approximation and Projection (UMAP).<span><sup>5</sup></span> Both dimensionality reduction techniques often used for visualizing high-dimensional data. One of the features regarding the axes is that, unlike typical plots with well-defined physical quantities such as blood pressure or voltage or time on the axes, t-SNE and UMAP plots have more abstract interpretations. The positions of the points on the plot reflect the (probability)-relationships between the individual data points in the original high-dimensional space, whereby we can find clustered clouds. The points in that clouds that are close together on the plot are considered similar or closely related in the high-dimensional space. When comparing t-SNE and UMAP, we can differentiate between so called local structure and global structure of the points in the diagram. The t-SNE method preserves local structure of the data, that is, close points in the diagram, for example, in a cluster represent close point in the higher dimensional space. However the global structure is not accurately preserved with the t-SNE method. Here is the main point where the improved UMAP method comes into play. The UMAP aims to preserve both local and global data structures more effectively than the t-SNE method. Therefore, the UMAP method might be more suitable for analysis of data where this feature of global topology is relevant for interpretation. This might be the case for example for high-dimensional lineage analysis in stem cell maturation. To illustrate their performance we have generated three datasets and visualize them with all the tree methods (Figure 2). With t-SNE and UMAP representation it is also possible to perform statistical analysis.<span><sup>6</sup></span> The UMAP method is widely used in high-dimensional data in the field of neurophysiology,<span><sup>7</sup></span> immunology,<span><sup>8</sup></span> cancer<span><sup>9, 10</sup></span> and infectious diseases like COVID-19.<span><sup>11</sup></span></p><p>Taken together, both nonlinear methods have been applied to high-dimensional data so far. Clusters in the data might be revealed and their usage in the literature has been growing steadily in the scientific literature since the publication of the methods (Figure 1). The meaning of the axes of t-SNE and UMAP plot is not straightforward as compared to more traditional diagrams used in physiology, for example, the spread of points showing the variance of what? The mapping of the data points into the diagram is a nonlinear transformation while on the local scales the neighboring relationships are aimed to preserve. The UMAP might be better in preserving global scales; however, one might be cautious in the interpretation of the distances of the clusters for both the t-SNE and the UMAP methods due to the nonlinear transformations. There are efforts to further improve those methods.<span><sup>12</sup></span> We will see whether they will find resonance and application the scientific community.</p><p>To come back to the beginning: please remember to take a second to explain what your high-dimensional plots show in your presentation. As physiology is a rather interdisciplinary and methods develop rapidly, likely part of your audience might otherwise be just admiring beautiful graphic and not your data.</p><p>RM did the statistics on pubmed occurences. RM and RS did the data anaysis for figure 2. RM wrote the initial text. Both authors edited the final version of the manuscript.</p><p>None.</p>","PeriodicalId":107,"journal":{"name":"Acta Physiologica","volume":"240 10","pages":""},"PeriodicalIF":5.6000,"publicationDate":"2024-08-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/apha.14219","citationCount":"0","resultStr":"{\"title\":\"How to visualize high-dimensional data\",\"authors\":\"Ralf Mrowka, Ralf Schmauder\",\"doi\":\"10.1111/apha.14219\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Recently, a colleague asked after a lecture about a fancy diagram where the axis designation was not clear to him and the discussion about that raised a few interesting thoughts about that specific matter. Physiological knowledge is often taught at university seminars and in textbooks with the help of diagrams. A very important first step when discussing diagrams is to clarify which physical, physiological variable at what scale and unit is represented on which axis. Examples of typical classical low dimensional diagrams in physiology publications in Acta Physiologica might be blood pressure over time,<span><sup>1</sup></span> infarct size as percentage of Left ventricular mass depending on genotype<span><sup>2</sup></span> or urine excretion in volume per time depending on diet.<span><sup>3</sup></span> Not knowing the axes of the classical diagrams, they might as well be “just” pieces of fancy modern art.</p><p>We strongly believe that graphical representation of complex data—for example, as diagrams—is essential in communicating them. However, for specific types of diagrams, the understanding and interpretation of their content is more complex, and requires more explanation than classical diagrams. Specifically, we refer to the graphical representation of high-dimensional data, which have, in recent years, played an increasing role in new understandings of physiological processes.</p><p>To visualize data a reduction of dimensionality is often applied. A simple example is a black/white photograph of a colorful moving three dimensional object. The snapshot “eliminated” the dimension time and the optical projection on a plane in the camera eliminated one dimension in space and the gray values just reduced the spectral information to an intensity value on the photograph. Although the photograph does not represent the compete “dataset” it gives us in most cases a good impression about the situation captured by the photographer.</p><p>Times have changed.</p><p>To describe the “amount” of data obtained for a study in the 1960s one physiologist for example referred to the length of the paper of plots of curved of blood pressure measurements he was analyzing for one particular study. Compared with that amount of data back then we are nowadays faced with a completely new situation. With the development of technology we have to handle a huge amount of data today. For example, in recent studies with single RNAseq data scientists obtained with thousands of expression values for single genes for each of thousands of single cells at multiple experimental points and possibly for multiple interventions. Obviously you cannot produce a meaningful simple classical plot with thousands of dimensions.</p><p>In order to make sense out of the hugely dimensional data, researches can employ methods for the reduction of dimensionality. One classical methods would be to employ the so called principal component analysis (PCA). This linear method projects the data onto a new coordinate system where the axes (principal components) are the directions of maximum variance. Without diving too deep into the mathematics, this is done by calculating the so called eigenvectors of the data matrix.</p><p>It turned out that this PCA method with its linear transformation is not sufficient in the above described case. Here new statistical approaches for nonlinear dimensionality reduction have been developed. One is the so called t-Distributed Stochastic Neighbor Embedding (t-SNE) method<span><sup>4</sup></span> and later a kind of improved version of this is the so called Uniform Manifold Approximation and Projection (UMAP).<span><sup>5</sup></span> Both dimensionality reduction techniques often used for visualizing high-dimensional data. One of the features regarding the axes is that, unlike typical plots with well-defined physical quantities such as blood pressure or voltage or time on the axes, t-SNE and UMAP plots have more abstract interpretations. The positions of the points on the plot reflect the (probability)-relationships between the individual data points in the original high-dimensional space, whereby we can find clustered clouds. The points in that clouds that are close together on the plot are considered similar or closely related in the high-dimensional space. When comparing t-SNE and UMAP, we can differentiate between so called local structure and global structure of the points in the diagram. The t-SNE method preserves local structure of the data, that is, close points in the diagram, for example, in a cluster represent close point in the higher dimensional space. However the global structure is not accurately preserved with the t-SNE method. Here is the main point where the improved UMAP method comes into play. The UMAP aims to preserve both local and global data structures more effectively than the t-SNE method. Therefore, the UMAP method might be more suitable for analysis of data where this feature of global topology is relevant for interpretation. This might be the case for example for high-dimensional lineage analysis in stem cell maturation. To illustrate their performance we have generated three datasets and visualize them with all the tree methods (Figure 2). With t-SNE and UMAP representation it is also possible to perform statistical analysis.<span><sup>6</sup></span> The UMAP method is widely used in high-dimensional data in the field of neurophysiology,<span><sup>7</sup></span> immunology,<span><sup>8</sup></span> cancer<span><sup>9, 10</sup></span> and infectious diseases like COVID-19.<span><sup>11</sup></span></p><p>Taken together, both nonlinear methods have been applied to high-dimensional data so far. Clusters in the data might be revealed and their usage in the literature has been growing steadily in the scientific literature since the publication of the methods (Figure 1). The meaning of the axes of t-SNE and UMAP plot is not straightforward as compared to more traditional diagrams used in physiology, for example, the spread of points showing the variance of what? The mapping of the data points into the diagram is a nonlinear transformation while on the local scales the neighboring relationships are aimed to preserve. The UMAP might be better in preserving global scales; however, one might be cautious in the interpretation of the distances of the clusters for both the t-SNE and the UMAP methods due to the nonlinear transformations. There are efforts to further improve those methods.<span><sup>12</sup></span> We will see whether they will find resonance and application the scientific community.</p><p>To come back to the beginning: please remember to take a second to explain what your high-dimensional plots show in your presentation. As physiology is a rather interdisciplinary and methods develop rapidly, likely part of your audience might otherwise be just admiring beautiful graphic and not your data.</p><p>RM did the statistics on pubmed occurences. RM and RS did the data anaysis for figure 2. RM wrote the initial text. Both authors edited the final version of the manuscript.</p><p>None.</p>\",\"PeriodicalId\":107,\"journal\":{\"name\":\"Acta Physiologica\",\"volume\":\"240 10\",\"pages\":\"\"},\"PeriodicalIF\":5.6000,\"publicationDate\":\"2024-08-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/apha.14219\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Acta Physiologica\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/apha.14219\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"PHYSIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Acta Physiologica","FirstCategoryId":"3","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/apha.14219","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PHYSIOLOGY","Score":null,"Total":0}
Recently, a colleague asked after a lecture about a fancy diagram where the axis designation was not clear to him and the discussion about that raised a few interesting thoughts about that specific matter. Physiological knowledge is often taught at university seminars and in textbooks with the help of diagrams. A very important first step when discussing diagrams is to clarify which physical, physiological variable at what scale and unit is represented on which axis. Examples of typical classical low dimensional diagrams in physiology publications in Acta Physiologica might be blood pressure over time,1 infarct size as percentage of Left ventricular mass depending on genotype2 or urine excretion in volume per time depending on diet.3 Not knowing the axes of the classical diagrams, they might as well be “just” pieces of fancy modern art.
We strongly believe that graphical representation of complex data—for example, as diagrams—is essential in communicating them. However, for specific types of diagrams, the understanding and interpretation of their content is more complex, and requires more explanation than classical diagrams. Specifically, we refer to the graphical representation of high-dimensional data, which have, in recent years, played an increasing role in new understandings of physiological processes.
To visualize data a reduction of dimensionality is often applied. A simple example is a black/white photograph of a colorful moving three dimensional object. The snapshot “eliminated” the dimension time and the optical projection on a plane in the camera eliminated one dimension in space and the gray values just reduced the spectral information to an intensity value on the photograph. Although the photograph does not represent the compete “dataset” it gives us in most cases a good impression about the situation captured by the photographer.
Times have changed.
To describe the “amount” of data obtained for a study in the 1960s one physiologist for example referred to the length of the paper of plots of curved of blood pressure measurements he was analyzing for one particular study. Compared with that amount of data back then we are nowadays faced with a completely new situation. With the development of technology we have to handle a huge amount of data today. For example, in recent studies with single RNAseq data scientists obtained with thousands of expression values for single genes for each of thousands of single cells at multiple experimental points and possibly for multiple interventions. Obviously you cannot produce a meaningful simple classical plot with thousands of dimensions.
In order to make sense out of the hugely dimensional data, researches can employ methods for the reduction of dimensionality. One classical methods would be to employ the so called principal component analysis (PCA). This linear method projects the data onto a new coordinate system where the axes (principal components) are the directions of maximum variance. Without diving too deep into the mathematics, this is done by calculating the so called eigenvectors of the data matrix.
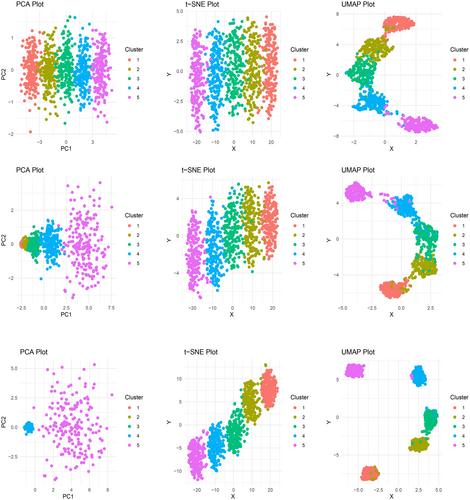
It turned out that this PCA method with its linear transformation is not sufficient in the above described case. Here new statistical approaches for nonlinear dimensionality reduction have been developed. One is the so called t-Distributed Stochastic Neighbor Embedding (t-SNE) method4 and later a kind of improved version of this is the so called Uniform Manifold Approximation and Projection (UMAP).5 Both dimensionality reduction techniques often used for visualizing high-dimensional data. One of the features regarding the axes is that, unlike typical plots with well-defined physical quantities such as blood pressure or voltage or time on the axes, t-SNE and UMAP plots have more abstract interpretations. The positions of the points on the plot reflect the (probability)-relationships between the individual data points in the original high-dimensional space, whereby we can find clustered clouds. The points in that clouds that are close together on the plot are considered similar or closely related in the high-dimensional space. When comparing t-SNE and UMAP, we can differentiate between so called local structure and global structure of the points in the diagram. The t-SNE method preserves local structure of the data, that is, close points in the diagram, for example, in a cluster represent close point in the higher dimensional space. However the global structure is not accurately preserved with the t-SNE method. Here is the main point where the improved UMAP method comes into play. The UMAP aims to preserve both local and global data structures more effectively than the t-SNE method. Therefore, the UMAP method might be more suitable for analysis of data where this feature of global topology is relevant for interpretation. This might be the case for example for high-dimensional lineage analysis in stem cell maturation. To illustrate their performance we have generated three datasets and visualize them with all the tree methods (Figure 2). With t-SNE and UMAP representation it is also possible to perform statistical analysis.6 The UMAP method is widely used in high-dimensional data in the field of neurophysiology,7 immunology,8 cancer9, 10 and infectious diseases like COVID-19.11
Taken together, both nonlinear methods have been applied to high-dimensional data so far. Clusters in the data might be revealed and their usage in the literature has been growing steadily in the scientific literature since the publication of the methods (Figure 1). The meaning of the axes of t-SNE and UMAP plot is not straightforward as compared to more traditional diagrams used in physiology, for example, the spread of points showing the variance of what? The mapping of the data points into the diagram is a nonlinear transformation while on the local scales the neighboring relationships are aimed to preserve. The UMAP might be better in preserving global scales; however, one might be cautious in the interpretation of the distances of the clusters for both the t-SNE and the UMAP methods due to the nonlinear transformations. There are efforts to further improve those methods.12 We will see whether they will find resonance and application the scientific community.
To come back to the beginning: please remember to take a second to explain what your high-dimensional plots show in your presentation. As physiology is a rather interdisciplinary and methods develop rapidly, likely part of your audience might otherwise be just admiring beautiful graphic and not your data.
RM did the statistics on pubmed occurences. RM and RS did the data anaysis for figure 2. RM wrote the initial text. Both authors edited the final version of the manuscript.
期刊介绍:
Acta Physiologica is an important forum for the publication of high quality original research in physiology and related areas by authors from all over the world. Acta Physiologica is a leading journal in human/translational physiology while promoting all aspects of the science of physiology. The journal publishes full length original articles on important new observations as well as reviews and commentaries.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


