Wenjun Liu, Huan Guo, Jiaxin Gan, Hai Wang, Hailan Wang, Chao Zhang, Qingcheng Peng, Yuyan Sun, Bao Yu, Mengshu Hou, Bo Li, Xiaolei Li
{"title":"基于 KM-LSH 融合算法和改进的 BTM 模型的主题检测方法","authors":"Wenjun Liu, Huan Guo, Jiaxin Gan, Hai Wang, Hailan Wang, Chao Zhang, Qingcheng Peng, Yuyan Sun, Bao Yu, Mengshu Hou, Bo Li, Xiaolei Li","doi":"10.1007/s00500-024-09874-x","DOIUrl":null,"url":null,"abstract":"<p>Topic detection is an information processing technology designed to help people deal with the growing problem of data information on the Internet. In the research literature, topic detection methods are used for topic classification through word embedding, supervised-based and unsupervised-based approaches. However, most methods for topic detection only address the problem of clustering and do not focus on the problem of topic detection accuracy reduction due to the cohesiveness of topics. Also, the sequence of biterm during topic detection can cause substantial deviations in the detected topic content. To solve the above problems, this paper proposes a topic detection method based on KM-LSH fusion algorithm and improved BTM model. KM-LSH fusion algorithm is a fusion algorithm that combines K-means clustering and LSH refinement clustering. The proposed method can solve the problem of cohesiveness of topic detection, and the improved BTM model can solve the influence of the sequence of biterm on topic detection. First, the text vector is constructed by processing the collected set of microblog texts using text preprocessing methods. Secondly, the KM-LSH fusion algorithm is used to calculate text similarity and perform topic clustering and refinement. Finally, the improved BTM model is used to model the texts, which is combined with the word position and the improved TF-IDF weight calculation algorithm to adjust the microblogging texts in clustering. The experiment results indicate that the proposed KM-LSH-IBTM method improves the evaluation indexes compared with the other three topic detection methods. In conclusion, the proposed KM-LSH-IBTM method promotes the processing capability of topic detection in terms of cohesiveness and the sequence of biterm.</p>","PeriodicalId":22039,"journal":{"name":"Soft Computing","volume":"11 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-08-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A topic detection method based on KM-LSH Fusion algorithm and improved BTM model\",\"authors\":\"Wenjun Liu, Huan Guo, Jiaxin Gan, Hai Wang, Hailan Wang, Chao Zhang, Qingcheng Peng, Yuyan Sun, Bao Yu, Mengshu Hou, Bo Li, Xiaolei Li\",\"doi\":\"10.1007/s00500-024-09874-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Topic detection is an information processing technology designed to help people deal with the growing problem of data information on the Internet. In the research literature, topic detection methods are used for topic classification through word embedding, supervised-based and unsupervised-based approaches. However, most methods for topic detection only address the problem of clustering and do not focus on the problem of topic detection accuracy reduction due to the cohesiveness of topics. Also, the sequence of biterm during topic detection can cause substantial deviations in the detected topic content. To solve the above problems, this paper proposes a topic detection method based on KM-LSH fusion algorithm and improved BTM model. KM-LSH fusion algorithm is a fusion algorithm that combines K-means clustering and LSH refinement clustering. The proposed method can solve the problem of cohesiveness of topic detection, and the improved BTM model can solve the influence of the sequence of biterm on topic detection. First, the text vector is constructed by processing the collected set of microblog texts using text preprocessing methods. Secondly, the KM-LSH fusion algorithm is used to calculate text similarity and perform topic clustering and refinement. Finally, the improved BTM model is used to model the texts, which is combined with the word position and the improved TF-IDF weight calculation algorithm to adjust the microblogging texts in clustering. The experiment results indicate that the proposed KM-LSH-IBTM method improves the evaluation indexes compared with the other three topic detection methods. In conclusion, the proposed KM-LSH-IBTM method promotes the processing capability of topic detection in terms of cohesiveness and the sequence of biterm.</p>\",\"PeriodicalId\":22039,\"journal\":{\"name\":\"Soft Computing\",\"volume\":\"11 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-08-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Soft Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00500-024-09874-x\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Soft Computing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00500-024-09874-x","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
A topic detection method based on KM-LSH Fusion algorithm and improved BTM model
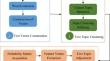
Topic detection is an information processing technology designed to help people deal with the growing problem of data information on the Internet. In the research literature, topic detection methods are used for topic classification through word embedding, supervised-based and unsupervised-based approaches. However, most methods for topic detection only address the problem of clustering and do not focus on the problem of topic detection accuracy reduction due to the cohesiveness of topics. Also, the sequence of biterm during topic detection can cause substantial deviations in the detected topic content. To solve the above problems, this paper proposes a topic detection method based on KM-LSH fusion algorithm and improved BTM model. KM-LSH fusion algorithm is a fusion algorithm that combines K-means clustering and LSH refinement clustering. The proposed method can solve the problem of cohesiveness of topic detection, and the improved BTM model can solve the influence of the sequence of biterm on topic detection. First, the text vector is constructed by processing the collected set of microblog texts using text preprocessing methods. Secondly, the KM-LSH fusion algorithm is used to calculate text similarity and perform topic clustering and refinement. Finally, the improved BTM model is used to model the texts, which is combined with the word position and the improved TF-IDF weight calculation algorithm to adjust the microblogging texts in clustering. The experiment results indicate that the proposed KM-LSH-IBTM method improves the evaluation indexes compared with the other three topic detection methods. In conclusion, the proposed KM-LSH-IBTM method promotes the processing capability of topic detection in terms of cohesiveness and the sequence of biterm.
期刊介绍:
Soft Computing is dedicated to system solutions based on soft computing techniques. It provides rapid dissemination of important results in soft computing technologies, a fusion of research in evolutionary algorithms and genetic programming, neural science and neural net systems, fuzzy set theory and fuzzy systems, and chaos theory and chaotic systems.
Soft Computing encourages the integration of soft computing techniques and tools into both everyday and advanced applications. By linking the ideas and techniques of soft computing with other disciplines, the journal serves as a unifying platform that fosters comparisons, extensions, and new applications. As a result, the journal is an international forum for all scientists and engineers engaged in research and development in this fast growing field.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


