Heng Zhang , Yuanyuan Pu , Zhengpeng Zhao , Yupan Li , Xin Li , Rencan Nie
{"title":"通过自适应归一化层和对比度学习实现图像到图像的多样化转换","authors":"Heng Zhang , Yuanyuan Pu , Zhengpeng Zhao , Yupan Li , Xin Li , Rencan Nie","doi":"10.1016/j.cag.2024.104017","DOIUrl":null,"url":null,"abstract":"<div><p>A nice image-to-image translation framework is able to acquire an explicit and credible mapping relationship between the source domain and target domains while satisfying two requirements. One is simplicity, the other is extensibility over multiple translation tasks. To this end, we design a concise but versatile generative model for image-to-image translation. Our method includes three major ingredients. First, inspired by popular unconditional normalization layers, named Spatially Adaptive Normalization(SPADE). We introduce a novel Semantics-Appearance Spatially Adaptive Normalization (SA-SPADE), taking into account both semantic structure and style appearance. This enables semantic composition and style appearance information to be sufficiently captured and integrated by our normalization layers. Thanks to SA-SPADE, our model extends to multiple image-to-image translation tasks in an unsupervised or supervised way. Second, we carefully designed two symmetrical network branches to provide semantic and appearance information for our normalization layer, namely Semantic Branch (SB) and Appearance Branch(AB) respectively. Third, we propose novel Semantic-aware Contrastive Loss (SCL) and Appearance-aware Contrastive Loss (ACL)based on newly un-/self- supervised contrastive learning. That is, SCL guarantees domain-invariant (e.g., pose, structure) representations between the generated image and the input image, while ACL ensures domain-specific representations (e.g., color, texture) between the generated image and the reference image. As a result, we verify the effectiveness of our method by comparing it with various task-dependent image translation models in both qualitative and quantitative evaluations.</p></div>","PeriodicalId":50628,"journal":{"name":"Computers & Graphics-Uk","volume":"123 ","pages":"Article 104017"},"PeriodicalIF":2.5000,"publicationDate":"2024-07-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Towards diverse image-to-image translation via adaptive normalization layer and contrast learning\",\"authors\":\"Heng Zhang , Yuanyuan Pu , Zhengpeng Zhao , Yupan Li , Xin Li , Rencan Nie\",\"doi\":\"10.1016/j.cag.2024.104017\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>A nice image-to-image translation framework is able to acquire an explicit and credible mapping relationship between the source domain and target domains while satisfying two requirements. One is simplicity, the other is extensibility over multiple translation tasks. To this end, we design a concise but versatile generative model for image-to-image translation. Our method includes three major ingredients. First, inspired by popular unconditional normalization layers, named Spatially Adaptive Normalization(SPADE). We introduce a novel Semantics-Appearance Spatially Adaptive Normalization (SA-SPADE), taking into account both semantic structure and style appearance. This enables semantic composition and style appearance information to be sufficiently captured and integrated by our normalization layers. Thanks to SA-SPADE, our model extends to multiple image-to-image translation tasks in an unsupervised or supervised way. Second, we carefully designed two symmetrical network branches to provide semantic and appearance information for our normalization layer, namely Semantic Branch (SB) and Appearance Branch(AB) respectively. Third, we propose novel Semantic-aware Contrastive Loss (SCL) and Appearance-aware Contrastive Loss (ACL)based on newly un-/self- supervised contrastive learning. That is, SCL guarantees domain-invariant (e.g., pose, structure) representations between the generated image and the input image, while ACL ensures domain-specific representations (e.g., color, texture) between the generated image and the reference image. As a result, we verify the effectiveness of our method by comparing it with various task-dependent image translation models in both qualitative and quantitative evaluations.</p></div>\",\"PeriodicalId\":50628,\"journal\":{\"name\":\"Computers & Graphics-Uk\",\"volume\":\"123 \",\"pages\":\"Article 104017\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2024-07-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers & Graphics-Uk\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0097849324001523\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Graphics-Uk","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0097849324001523","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Towards diverse image-to-image translation via adaptive normalization layer and contrast learning
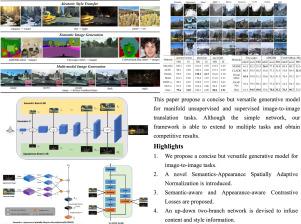
A nice image-to-image translation framework is able to acquire an explicit and credible mapping relationship between the source domain and target domains while satisfying two requirements. One is simplicity, the other is extensibility over multiple translation tasks. To this end, we design a concise but versatile generative model for image-to-image translation. Our method includes three major ingredients. First, inspired by popular unconditional normalization layers, named Spatially Adaptive Normalization(SPADE). We introduce a novel Semantics-Appearance Spatially Adaptive Normalization (SA-SPADE), taking into account both semantic structure and style appearance. This enables semantic composition and style appearance information to be sufficiently captured and integrated by our normalization layers. Thanks to SA-SPADE, our model extends to multiple image-to-image translation tasks in an unsupervised or supervised way. Second, we carefully designed two symmetrical network branches to provide semantic and appearance information for our normalization layer, namely Semantic Branch (SB) and Appearance Branch(AB) respectively. Third, we propose novel Semantic-aware Contrastive Loss (SCL) and Appearance-aware Contrastive Loss (ACL)based on newly un-/self- supervised contrastive learning. That is, SCL guarantees domain-invariant (e.g., pose, structure) representations between the generated image and the input image, while ACL ensures domain-specific representations (e.g., color, texture) between the generated image and the reference image. As a result, we verify the effectiveness of our method by comparing it with various task-dependent image translation models in both qualitative and quantitative evaluations.
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


