Cristiano Sorrentino, Vincenzo Canoro, Maria Russo, Caterina Giordano, Paolo Barone, Roberto Erro
{"title":"评估 ChatGPT 回答有关本质性震颤的常见问题的能力。","authors":"Cristiano Sorrentino, Vincenzo Canoro, Maria Russo, Caterina Giordano, Paolo Barone, Roberto Erro","doi":"10.5334/tohm.917","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large-language models (LLMs) driven by artificial intelligence allow people to engage in direct conversations about their health. The accuracy and readability of the answers provided by ChatGPT, the most famous LLM, about Essential Tremor (ET), one of the commonest movement disorders, have not yet been evaluated.</p><p><strong>Methods: </strong>Answers given by ChatGPT to 10 questions about ET were evaluated by 5 professionals and 15 laypeople with a score ranging from 1 (poor) to 5 (excellent) in terms of clarity, relevance, accuracy (only for professionals), comprehensiveness, and overall value of the response. We further calculated the readability of the answers.</p><p><strong>Results: </strong>ChatGPT answers received relatively positive evaluations, with median scores ranging between 4 and 5, by both groups and independently from the type of question. However, there was only moderate agreement between raters, especially in the group of professionals. Moreover, readability levels were poor for all examined answers.</p><p><strong>Discussion: </strong>ChatGPT provided relatively accurate and relevant answers, with some variability as judged by the group of professionals suggesting that the degree of literacy about ET has influenced the ratings and, indirectly, that the quality of information provided in clinical practice is also variable. Moreover, the readability of the answer provided by ChatGPT was found to be poor. LLMs will likely play a significant role in the future; therefore, health-related content generated by these tools should be monitored.</p>","PeriodicalId":23317,"journal":{"name":"Tremor and Other Hyperkinetic Movements","volume":"14 ","pages":"33"},"PeriodicalIF":2.1000,"publicationDate":"2024-07-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11225576/pdf/","citationCount":"0","resultStr":"{\"title\":\"Assessing ChatGPT Ability to Answer Frequently Asked Questions About Essential Tremor.\",\"authors\":\"Cristiano Sorrentino, Vincenzo Canoro, Maria Russo, Caterina Giordano, Paolo Barone, Roberto Erro\",\"doi\":\"10.5334/tohm.917\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Large-language models (LLMs) driven by artificial intelligence allow people to engage in direct conversations about their health. The accuracy and readability of the answers provided by ChatGPT, the most famous LLM, about Essential Tremor (ET), one of the commonest movement disorders, have not yet been evaluated.</p><p><strong>Methods: </strong>Answers given by ChatGPT to 10 questions about ET were evaluated by 5 professionals and 15 laypeople with a score ranging from 1 (poor) to 5 (excellent) in terms of clarity, relevance, accuracy (only for professionals), comprehensiveness, and overall value of the response. We further calculated the readability of the answers.</p><p><strong>Results: </strong>ChatGPT answers received relatively positive evaluations, with median scores ranging between 4 and 5, by both groups and independently from the type of question. However, there was only moderate agreement between raters, especially in the group of professionals. Moreover, readability levels were poor for all examined answers.</p><p><strong>Discussion: </strong>ChatGPT provided relatively accurate and relevant answers, with some variability as judged by the group of professionals suggesting that the degree of literacy about ET has influenced the ratings and, indirectly, that the quality of information provided in clinical practice is also variable. Moreover, the readability of the answer provided by ChatGPT was found to be poor. LLMs will likely play a significant role in the future; therefore, health-related content generated by these tools should be monitored.</p>\",\"PeriodicalId\":23317,\"journal\":{\"name\":\"Tremor and Other Hyperkinetic Movements\",\"volume\":\"14 \",\"pages\":\"33\"},\"PeriodicalIF\":2.1000,\"publicationDate\":\"2024-07-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11225576/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Tremor and Other Hyperkinetic Movements\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.5334/tohm.917\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"CLINICAL NEUROLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Tremor and Other Hyperkinetic Movements","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5334/tohm.917","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"CLINICAL NEUROLOGY","Score":null,"Total":0}
Assessing ChatGPT Ability to Answer Frequently Asked Questions About Essential Tremor.
Background: Large-language models (LLMs) driven by artificial intelligence allow people to engage in direct conversations about their health. The accuracy and readability of the answers provided by ChatGPT, the most famous LLM, about Essential Tremor (ET), one of the commonest movement disorders, have not yet been evaluated.
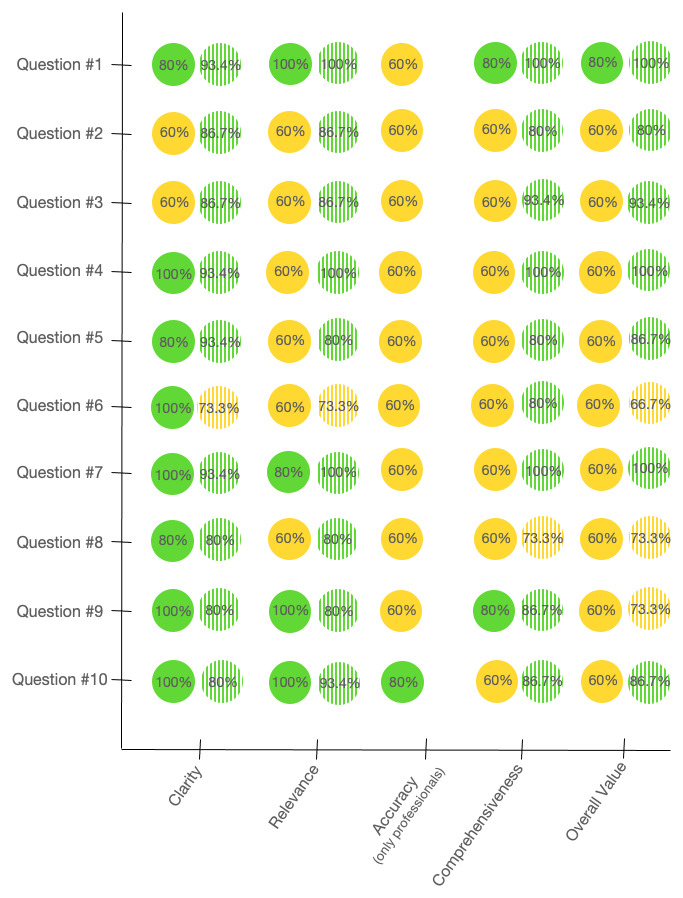
Methods: Answers given by ChatGPT to 10 questions about ET were evaluated by 5 professionals and 15 laypeople with a score ranging from 1 (poor) to 5 (excellent) in terms of clarity, relevance, accuracy (only for professionals), comprehensiveness, and overall value of the response. We further calculated the readability of the answers.
Results: ChatGPT answers received relatively positive evaluations, with median scores ranging between 4 and 5, by both groups and independently from the type of question. However, there was only moderate agreement between raters, especially in the group of professionals. Moreover, readability levels were poor for all examined answers.
Discussion: ChatGPT provided relatively accurate and relevant answers, with some variability as judged by the group of professionals suggesting that the degree of literacy about ET has influenced the ratings and, indirectly, that the quality of information provided in clinical practice is also variable. Moreover, the readability of the answer provided by ChatGPT was found to be poor. LLMs will likely play a significant role in the future; therefore, health-related content generated by these tools should be monitored.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


