Rebecca A Ho, Ariana L Shaari, Paul T Cowan, Kenneth Yan
{"title":"ChatGPT 对梅尼埃病常见问题的回答:与临床实践指南答案的比较。","authors":"Rebecca A Ho, Ariana L Shaari, Paul T Cowan, Kenneth Yan","doi":"10.1002/oto2.163","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Evaluate the quality of responses from Chat Generative Pre-Trained Transformer (ChatGPT) models compared to the answers for \"Frequently Asked Questions\" (FAQs) from the American Academy of Otolaryngology-Head and Neck Surgery (AAO-HNS) Clinical Practice Guidelines (CPG) for Ménière's disease (MD).</p><p><strong>Study design: </strong>Comparative analysis.</p><p><strong>Setting: </strong>The AAO-HNS CPG for MD includes FAQs that clinicians can give to patients for MD-related questions. The ability of ChatGPT to properly educate patients regarding MD is unknown.</p><p><strong>Methods: </strong>ChatGPT-3.5 and 4.0 were each prompted with 16 questions from the MD FAQs. Each response was rated in terms of (1) comprehensiveness, (2) extensiveness, (3) presence of misleading information, and (4) quality of resources. Readability was assessed using Flesch-Kincaid Grade Level (FKGL) and Flesch Reading Ease Score (FRES).</p><p><strong>Results: </strong>ChatGPT-3.5 was comprehensive in 5 responses whereas ChatGPT-4.0 was comprehensive in 9 (31.3% vs 56.3%, <i>P</i> = .2852). ChatGPT-3.5 and 4.0 were extensive in all responses (<i>P</i> = 1.0000). ChatGPT-3.5 was misleading in 5 responses whereas ChatGPT-4.0 was misleading in 3 (31.3% vs 18.75%, <i>P</i> = .6851). ChatGPT-3.5 had quality resources in 10 responses whereas ChatGPT-4.0 had quality resources in 16 (62.5% vs 100%, <i>P</i> = .0177). AAO-HNS CPG FRES (62.4 ± 16.6) demonstrated an appropriate readability score of at least 60, while both ChatGPT-3.5 (39.1 ± 7.3) and 4.0 (42.8 ± 8.5) failed to meet this standard. All platforms had FKGL means that exceeded the recommended level of 6 or lower.</p><p><strong>Conclusion: </strong>While ChatGPT-4.0 had significantly better resource reporting, both models have room for improvement in being more comprehensive, more readable, and less misleading for patients.</p>","PeriodicalId":19697,"journal":{"name":"OTO Open","volume":"8 3","pages":"e163"},"PeriodicalIF":1.8000,"publicationDate":"2024-07-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11225079/pdf/","citationCount":"0","resultStr":"{\"title\":\"ChatGPT Responses to Frequently Asked Questions on Ménière's Disease: A Comparison to Clinical Practice Guideline Answers.\",\"authors\":\"Rebecca A Ho, Ariana L Shaari, Paul T Cowan, Kenneth Yan\",\"doi\":\"10.1002/oto2.163\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Evaluate the quality of responses from Chat Generative Pre-Trained Transformer (ChatGPT) models compared to the answers for \\\"Frequently Asked Questions\\\" (FAQs) from the American Academy of Otolaryngology-Head and Neck Surgery (AAO-HNS) Clinical Practice Guidelines (CPG) for Ménière's disease (MD).</p><p><strong>Study design: </strong>Comparative analysis.</p><p><strong>Setting: </strong>The AAO-HNS CPG for MD includes FAQs that clinicians can give to patients for MD-related questions. The ability of ChatGPT to properly educate patients regarding MD is unknown.</p><p><strong>Methods: </strong>ChatGPT-3.5 and 4.0 were each prompted with 16 questions from the MD FAQs. Each response was rated in terms of (1) comprehensiveness, (2) extensiveness, (3) presence of misleading information, and (4) quality of resources. Readability was assessed using Flesch-Kincaid Grade Level (FKGL) and Flesch Reading Ease Score (FRES).</p><p><strong>Results: </strong>ChatGPT-3.5 was comprehensive in 5 responses whereas ChatGPT-4.0 was comprehensive in 9 (31.3% vs 56.3%, <i>P</i> = .2852). ChatGPT-3.5 and 4.0 were extensive in all responses (<i>P</i> = 1.0000). ChatGPT-3.5 was misleading in 5 responses whereas ChatGPT-4.0 was misleading in 3 (31.3% vs 18.75%, <i>P</i> = .6851). ChatGPT-3.5 had quality resources in 10 responses whereas ChatGPT-4.0 had quality resources in 16 (62.5% vs 100%, <i>P</i> = .0177). AAO-HNS CPG FRES (62.4 ± 16.6) demonstrated an appropriate readability score of at least 60, while both ChatGPT-3.5 (39.1 ± 7.3) and 4.0 (42.8 ± 8.5) failed to meet this standard. All platforms had FKGL means that exceeded the recommended level of 6 or lower.</p><p><strong>Conclusion: </strong>While ChatGPT-4.0 had significantly better resource reporting, both models have room for improvement in being more comprehensive, more readable, and less misleading for patients.</p>\",\"PeriodicalId\":19697,\"journal\":{\"name\":\"OTO Open\",\"volume\":\"8 3\",\"pages\":\"e163\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-07-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11225079/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"OTO Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1002/oto2.163\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/7/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"OTORHINOLARYNGOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"OTO Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1002/oto2.163","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"OTORHINOLARYNGOLOGY","Score":null,"Total":0}
ChatGPT Responses to Frequently Asked Questions on Ménière's Disease: A Comparison to Clinical Practice Guideline Answers.
Objective: Evaluate the quality of responses from Chat Generative Pre-Trained Transformer (ChatGPT) models compared to the answers for "Frequently Asked Questions" (FAQs) from the American Academy of Otolaryngology-Head and Neck Surgery (AAO-HNS) Clinical Practice Guidelines (CPG) for Ménière's disease (MD).
Study design: Comparative analysis.
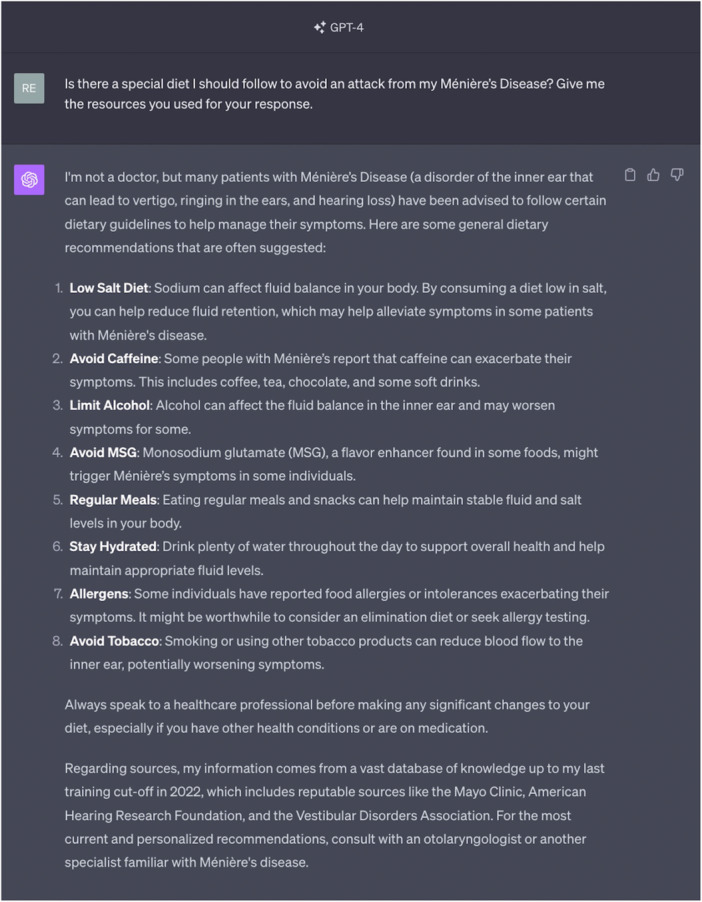
Setting: The AAO-HNS CPG for MD includes FAQs that clinicians can give to patients for MD-related questions. The ability of ChatGPT to properly educate patients regarding MD is unknown.
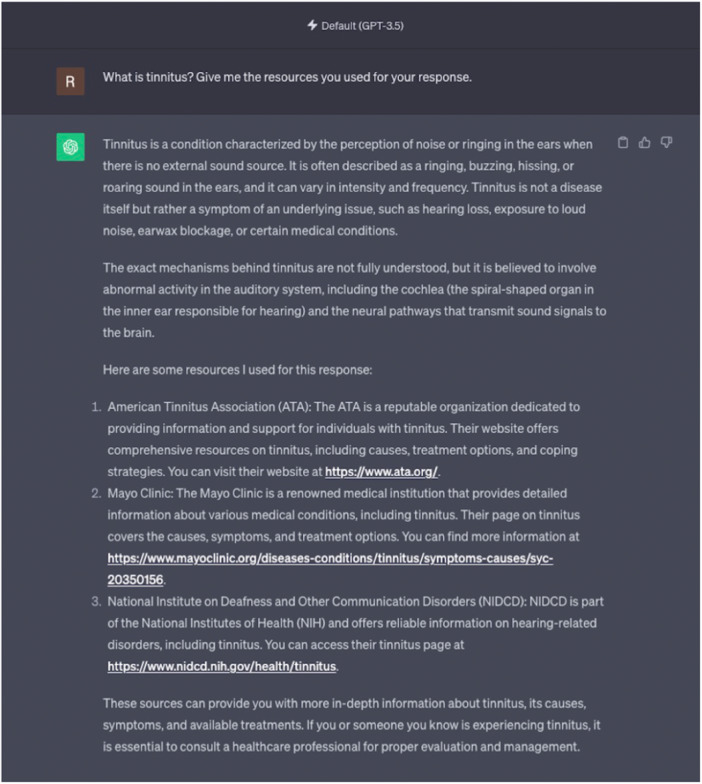
Methods: ChatGPT-3.5 and 4.0 were each prompted with 16 questions from the MD FAQs. Each response was rated in terms of (1) comprehensiveness, (2) extensiveness, (3) presence of misleading information, and (4) quality of resources. Readability was assessed using Flesch-Kincaid Grade Level (FKGL) and Flesch Reading Ease Score (FRES).
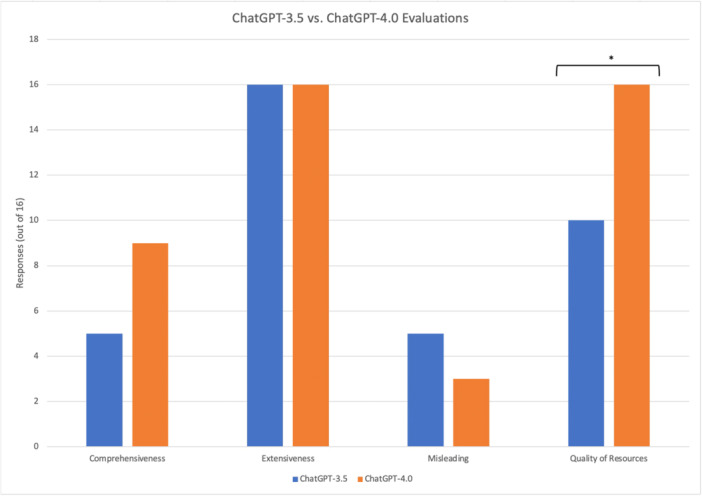
Results: ChatGPT-3.5 was comprehensive in 5 responses whereas ChatGPT-4.0 was comprehensive in 9 (31.3% vs 56.3%, P = .2852). ChatGPT-3.5 and 4.0 were extensive in all responses (P = 1.0000). ChatGPT-3.5 was misleading in 5 responses whereas ChatGPT-4.0 was misleading in 3 (31.3% vs 18.75%, P = .6851). ChatGPT-3.5 had quality resources in 10 responses whereas ChatGPT-4.0 had quality resources in 16 (62.5% vs 100%, P = .0177). AAO-HNS CPG FRES (62.4 ± 16.6) demonstrated an appropriate readability score of at least 60, while both ChatGPT-3.5 (39.1 ± 7.3) and 4.0 (42.8 ± 8.5) failed to meet this standard. All platforms had FKGL means that exceeded the recommended level of 6 or lower.
Conclusion: While ChatGPT-4.0 had significantly better resource reporting, both models have room for improvement in being more comprehensive, more readable, and less misleading for patients.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


