Nuno A. B. Martins, Luís A. da Silva Cruz, Fernando Lopes
{"title":"在 KITTI 数据集上评估激光雷达点云压缩对 3D 物体检测的影响","authors":"Nuno A. B. Martins, Luís A. da Silva Cruz, Fernando Lopes","doi":"10.1186/s13640-024-00633-4","DOIUrl":null,"url":null,"abstract":"<p>The rapid growth on the amount of generated 3D data, particularly in the form of Light Detection And Ranging (LiDAR) point clouds (PCs), poses very significant challenges in terms of data storage, transmission, and processing. Point cloud (PC) representation of 3D visual information has shown to be a very flexible format with many applications ranging from multimedia immersive communication to machine vision tasks in the robotics and autonomous driving domains. In this paper, we investigate the performance of four reference 3D object detection techniques, when the input PCs are compressed with varying levels of degradation. Compression is performed using two MPEG standard coders based on 2D projections and octree decomposition, as well as two coding methods based on Deep Learning (DL). For the DL coding methods, we used a Joint Photographic Experts Group (JPEG) reference PC coder, that we adapted to accept LiDAR PCs in both Cartesian and cylindrical coordinate systems. The detection performance of the four reference 3D object detection methods was evaluated using both pre-trained models and models specifically trained using degraded PCs reconstructed from compressed representations. It is shown that LiDAR PCs can be compressed down to 6 bits per point with no significant degradation on the object detection precision. Furthermore, employing specifically trained detection models improves the detection capabilities even at compression rates as low as 2 bits per point. These results show that LiDAR PCs can be coded to enable efficient storage and transmission, without significant object detection performance loss.</p>","PeriodicalId":49322,"journal":{"name":"Eurasip Journal on Image and Video Processing","volume":"51 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-06-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Impact of LiDAR point cloud compression on 3D object detection evaluated on the KITTI dataset\",\"authors\":\"Nuno A. B. Martins, Luís A. da Silva Cruz, Fernando Lopes\",\"doi\":\"10.1186/s13640-024-00633-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The rapid growth on the amount of generated 3D data, particularly in the form of Light Detection And Ranging (LiDAR) point clouds (PCs), poses very significant challenges in terms of data storage, transmission, and processing. Point cloud (PC) representation of 3D visual information has shown to be a very flexible format with many applications ranging from multimedia immersive communication to machine vision tasks in the robotics and autonomous driving domains. In this paper, we investigate the performance of four reference 3D object detection techniques, when the input PCs are compressed with varying levels of degradation. Compression is performed using two MPEG standard coders based on 2D projections and octree decomposition, as well as two coding methods based on Deep Learning (DL). For the DL coding methods, we used a Joint Photographic Experts Group (JPEG) reference PC coder, that we adapted to accept LiDAR PCs in both Cartesian and cylindrical coordinate systems. The detection performance of the four reference 3D object detection methods was evaluated using both pre-trained models and models specifically trained using degraded PCs reconstructed from compressed representations. It is shown that LiDAR PCs can be compressed down to 6 bits per point with no significant degradation on the object detection precision. Furthermore, employing specifically trained detection models improves the detection capabilities even at compression rates as low as 2 bits per point. These results show that LiDAR PCs can be coded to enable efficient storage and transmission, without significant object detection performance loss.</p>\",\"PeriodicalId\":49322,\"journal\":{\"name\":\"Eurasip Journal on Image and Video Processing\",\"volume\":\"51 1\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-06-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Eurasip Journal on Image and Video Processing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s13640-024-00633-4\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Eurasip Journal on Image and Video Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s13640-024-00633-4","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
生成的三维数据量迅速增长,尤其是以光探测和测距(LiDAR)点云(PC)的形式出现,这给数据存储、传输和处理带来了巨大挑战。三维视觉信息的点云(PC)表示已被证明是一种非常灵活的格式,其应用范围从多媒体沉浸式通信到机器人和自动驾驶领域的机器视觉任务。在本文中,我们研究了四种参考 3D 物体检测技术在对输入 PC 进行不同程度的降级压缩时的性能。压缩采用了两种基于二维投影和八叉树分解的 MPEG 标准编码器,以及两种基于深度学习(DL)的编码方法。对于 DL 编码方法,我们使用了联合图像专家组(JPEG)的参考 PC 编码器,并对其进行了调整,以接受直角坐标系和圆柱坐标系中的 LiDAR PC。我们使用预训练模型和使用压缩表示重建的降级 PC 专门训练的模型,对四种参考 3D 物体检测方法的检测性能进行了评估。结果表明,LiDAR PC 可以压缩到每点 6 比特,而物体检测精度不会明显降低。此外,即使压缩率低至每点 2 比特,采用专门训练的检测模型也能提高检测能力。这些结果表明,可以对激光雷达 PC 进行编码,以实现高效存储和传输,而不会明显降低物体检测性能。
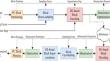
Impact of LiDAR point cloud compression on 3D object detection evaluated on the KITTI dataset
The rapid growth on the amount of generated 3D data, particularly in the form of Light Detection And Ranging (LiDAR) point clouds (PCs), poses very significant challenges in terms of data storage, transmission, and processing. Point cloud (PC) representation of 3D visual information has shown to be a very flexible format with many applications ranging from multimedia immersive communication to machine vision tasks in the robotics and autonomous driving domains. In this paper, we investigate the performance of four reference 3D object detection techniques, when the input PCs are compressed with varying levels of degradation. Compression is performed using two MPEG standard coders based on 2D projections and octree decomposition, as well as two coding methods based on Deep Learning (DL). For the DL coding methods, we used a Joint Photographic Experts Group (JPEG) reference PC coder, that we adapted to accept LiDAR PCs in both Cartesian and cylindrical coordinate systems. The detection performance of the four reference 3D object detection methods was evaluated using both pre-trained models and models specifically trained using degraded PCs reconstructed from compressed representations. It is shown that LiDAR PCs can be compressed down to 6 bits per point with no significant degradation on the object detection precision. Furthermore, employing specifically trained detection models improves the detection capabilities even at compression rates as low as 2 bits per point. These results show that LiDAR PCs can be coded to enable efficient storage and transmission, without significant object detection performance loss.
期刊介绍:
EURASIP Journal on Image and Video Processing is intended for researchers from both academia and industry, who are active in the multidisciplinary field of image and video processing. The scope of the journal covers all theoretical and practical aspects of the domain, from basic research to development of application.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


