{"title":"基于机器学习的新抗原筛选点燃癌症免疫疗法的火花","authors":"Sebastian Jurczak, Maksym Druchok","doi":"10.1002/adbi.202400114","DOIUrl":null,"url":null,"abstract":"<p>Identification of neoantigens, derived from somatic DNA alterations, emerges as a promising strategy for cancer immunotherapies. However, not all somatic mutations result in immunogenicity, hence, efficient tools to predict the immunogenicity of neoepitopes are needed. A pipeline is presented that provides a comprehensive solution for the identification of neoepitopes based on genomic sequencing data. The pipeline consists of a data pre-processing step and three machine learning predictive steps. The pre-processing step analyzes genomic data for different types of alterations, produces a list of all possible antigens, and determines the human leukocyte antigen (HLA) type and T-cell receptor (TCR) repertoire. The first predictive step performs a classification into antigens and neoantigens, selecting neoantigens for further consideration. The next step predicts the strength of binding between neoantigens and available major histocompatibility complexes of class I (MHC-I). The third step is engaged to predict the likelihood of inducing an immune response. Neoepitopes satisfying all three predictive stages are assumed to be potent candidates to ensure immunogenicity. The predictive pipeline is used in two regimes: selecting neoantigens from patients' sequencing data and generating novel neoantigen candidates. Two different techniques — Monte Carlo and Reinforcement Learning – are implemented to facilitate the generative regime.</p>","PeriodicalId":7234,"journal":{"name":"Advanced biology","volume":"8 10","pages":""},"PeriodicalIF":2.6000,"publicationDate":"2024-07-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Cancer Immunotherapies Ignited by a Thorough Machine Learning-Based Selection of Neoantigens\",\"authors\":\"Sebastian Jurczak, Maksym Druchok\",\"doi\":\"10.1002/adbi.202400114\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Identification of neoantigens, derived from somatic DNA alterations, emerges as a promising strategy for cancer immunotherapies. However, not all somatic mutations result in immunogenicity, hence, efficient tools to predict the immunogenicity of neoepitopes are needed. A pipeline is presented that provides a comprehensive solution for the identification of neoepitopes based on genomic sequencing data. The pipeline consists of a data pre-processing step and three machine learning predictive steps. The pre-processing step analyzes genomic data for different types of alterations, produces a list of all possible antigens, and determines the human leukocyte antigen (HLA) type and T-cell receptor (TCR) repertoire. The first predictive step performs a classification into antigens and neoantigens, selecting neoantigens for further consideration. The next step predicts the strength of binding between neoantigens and available major histocompatibility complexes of class I (MHC-I). The third step is engaged to predict the likelihood of inducing an immune response. Neoepitopes satisfying all three predictive stages are assumed to be potent candidates to ensure immunogenicity. The predictive pipeline is used in two regimes: selecting neoantigens from patients' sequencing data and generating novel neoantigen candidates. Two different techniques — Monte Carlo and Reinforcement Learning – are implemented to facilitate the generative regime.</p>\",\"PeriodicalId\":7234,\"journal\":{\"name\":\"Advanced biology\",\"volume\":\"8 10\",\"pages\":\"\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2024-07-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advanced biology\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://advanced.onlinelibrary.wiley.com/doi/10.1002/adbi.202400114\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATERIALS SCIENCE, BIOMATERIALS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advanced biology","FirstCategoryId":"99","ListUrlMain":"https://advanced.onlinelibrary.wiley.com/doi/10.1002/adbi.202400114","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATERIALS SCIENCE, BIOMATERIALS","Score":null,"Total":0}
引用次数: 0
摘要
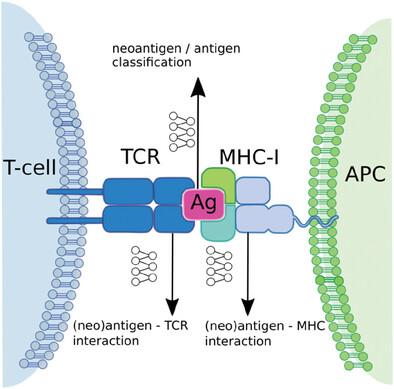
鉴定来自体细胞 DNA 变异的新抗原是一种很有前景的癌症免疫疗法策略。然而,并非所有的体细胞突变都会导致免疫原性,因此需要高效的工具来预测新表位的免疫原性。本文介绍了一种基于基因组测序数据鉴定新表位的综合解决方案。该流程包括一个数据预处理步骤和三个机器学习预测步骤。预处理步骤分析基因组数据中不同类型的改变,生成所有可能抗原的列表,并确定人类白细胞抗原(HLA)类型和 T 细胞受体(TCR)谱系。第一个预测步骤将抗原和新抗原进行分类,选择新抗原作进一步考虑。下一步是预测新抗原与可用的 I 类主要组织相容性复合物(MHC-I)之间的结合强度。第三步是预测诱导免疫反应的可能性。满足所有三个预测阶段的新抗原被认为是有效的候选抗原,以确保免疫原性。预测流程分为两种:从患者的测序数据中选择新抗原和生成新的候选新抗原。两种不同的技术--蒙特卡洛和强化学习--被用于促进生成机制。
Cancer Immunotherapies Ignited by a Thorough Machine Learning-Based Selection of Neoantigens
Identification of neoantigens, derived from somatic DNA alterations, emerges as a promising strategy for cancer immunotherapies. However, not all somatic mutations result in immunogenicity, hence, efficient tools to predict the immunogenicity of neoepitopes are needed. A pipeline is presented that provides a comprehensive solution for the identification of neoepitopes based on genomic sequencing data. The pipeline consists of a data pre-processing step and three machine learning predictive steps. The pre-processing step analyzes genomic data for different types of alterations, produces a list of all possible antigens, and determines the human leukocyte antigen (HLA) type and T-cell receptor (TCR) repertoire. The first predictive step performs a classification into antigens and neoantigens, selecting neoantigens for further consideration. The next step predicts the strength of binding between neoantigens and available major histocompatibility complexes of class I (MHC-I). The third step is engaged to predict the likelihood of inducing an immune response. Neoepitopes satisfying all three predictive stages are assumed to be potent candidates to ensure immunogenicity. The predictive pipeline is used in two regimes: selecting neoantigens from patients' sequencing data and generating novel neoantigen candidates. Two different techniques — Monte Carlo and Reinforcement Learning – are implemented to facilitate the generative regime.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


