{"title":"TDG-Diff:利用两级扩散引导推进定制文本到图像的合成","authors":"Hong Lin, Qi Chen, Chun Liu, Jingsong Hu","doi":"10.1016/j.cag.2024.103986","DOIUrl":null,"url":null,"abstract":"<div><p>Recently, there has been widespread attention and significant progress in customized text-to-image synthesis based on diffusion models. However, reconstructing multiple concepts in the same scene remains highly challenging. Therefore, we propose a novel framework called TDG-Diff, which employs a two-stage diffusion guidance to achieve customized image synthesis with multiple concepts. TDG-Diff focuses on improving the sampling process of the diffusion model. Specifically, TDG-Diff subdivides the sampling process into two key stages: attribute separation and appearance refinement, introducing spatial constraints and concept representations for sampling guidance. In the attribute separation stage, TDG-Diff introduces a novel attention modulation method. This method effectively separates the attributes of different concepts based on spatial constraint information, reducing the risk of entanglement between attributes of different concepts. In the appearance refinement stage, TDG-Diff proposes a fusion sampling approach, which combines global text descriptions and concept representations to optimize and enhance the model’s ability to capture and represent fine-grained details of concepts. Extensive qualitative and quantitative results demonstrate the effectiveness of TDG-Diff in customized text-to-image synthesis.</p></div>","PeriodicalId":50628,"journal":{"name":"Computers & Graphics-Uk","volume":"122 ","pages":"Article 103986"},"PeriodicalIF":2.5000,"publicationDate":"2024-06-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"TDG-Diff: Advancing customized text-to-image synthesis with two-stage diffusion guidance\",\"authors\":\"Hong Lin, Qi Chen, Chun Liu, Jingsong Hu\",\"doi\":\"10.1016/j.cag.2024.103986\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Recently, there has been widespread attention and significant progress in customized text-to-image synthesis based on diffusion models. However, reconstructing multiple concepts in the same scene remains highly challenging. Therefore, we propose a novel framework called TDG-Diff, which employs a two-stage diffusion guidance to achieve customized image synthesis with multiple concepts. TDG-Diff focuses on improving the sampling process of the diffusion model. Specifically, TDG-Diff subdivides the sampling process into two key stages: attribute separation and appearance refinement, introducing spatial constraints and concept representations for sampling guidance. In the attribute separation stage, TDG-Diff introduces a novel attention modulation method. This method effectively separates the attributes of different concepts based on spatial constraint information, reducing the risk of entanglement between attributes of different concepts. In the appearance refinement stage, TDG-Diff proposes a fusion sampling approach, which combines global text descriptions and concept representations to optimize and enhance the model’s ability to capture and represent fine-grained details of concepts. Extensive qualitative and quantitative results demonstrate the effectiveness of TDG-Diff in customized text-to-image synthesis.</p></div>\",\"PeriodicalId\":50628,\"journal\":{\"name\":\"Computers & Graphics-Uk\",\"volume\":\"122 \",\"pages\":\"Article 103986\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2024-06-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers & Graphics-Uk\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0097849324001213\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Graphics-Uk","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0097849324001213","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
TDG-Diff: Advancing customized text-to-image synthesis with two-stage diffusion guidance
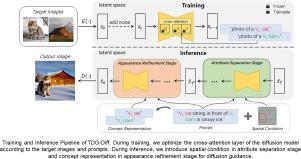
Recently, there has been widespread attention and significant progress in customized text-to-image synthesis based on diffusion models. However, reconstructing multiple concepts in the same scene remains highly challenging. Therefore, we propose a novel framework called TDG-Diff, which employs a two-stage diffusion guidance to achieve customized image synthesis with multiple concepts. TDG-Diff focuses on improving the sampling process of the diffusion model. Specifically, TDG-Diff subdivides the sampling process into two key stages: attribute separation and appearance refinement, introducing spatial constraints and concept representations for sampling guidance. In the attribute separation stage, TDG-Diff introduces a novel attention modulation method. This method effectively separates the attributes of different concepts based on spatial constraint information, reducing the risk of entanglement between attributes of different concepts. In the appearance refinement stage, TDG-Diff proposes a fusion sampling approach, which combines global text descriptions and concept representations to optimize and enhance the model’s ability to capture and represent fine-grained details of concepts. Extensive qualitative and quantitative results demonstrate the effectiveness of TDG-Diff in customized text-to-image synthesis.
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


