Viktor Wiberg , Erik Wallin , Arvid Fälldin , Tobias Semberg , Morgan Rossander , Eddie Wadbro , Martin Servin
{"title":"利用深度强化学习实现主动悬架控制的仿真到真实传输","authors":"Viktor Wiberg , Erik Wallin , Arvid Fälldin , Tobias Semberg , Morgan Rossander , Eddie Wadbro , Martin Servin","doi":"10.1016/j.robot.2024.104731","DOIUrl":null,"url":null,"abstract":"<div><p>We explore sim-to-real transfer of deep reinforcement learning controllers for a heavy vehicle with active suspensions designed for traversing rough terrain. While related research primarily focuses on lightweight robots with electric motors and fast actuation, this study uses a forestry vehicle with a complex hydraulic driveline and slow actuation. We simulate the vehicle using multibody dynamics and apply system identification to find an appropriate set of simulation parameters. We then train policies in simulation using various techniques to mitigate the sim-to-real gap, including domain randomization, action delays, and a reward penalty to encourage smooth control. In reality, the policies trained with action delays and a penalty for erratic actions perform nearly at the same level as in simulation. In experiments on level ground, the motion trajectories closely overlap when turning to either side, as well as in a route tracking scenario. When faced with a ramp that requires active use of the suspensions, the simulated and real motions are in close alignment. This shows that the actuator model together with system identification yields a sufficiently accurate model of the actuators. We observe that policies trained without the additional action penalty exhibit fast switching or bang–bang control. These present smooth motions and high performance in simulation but transfer poorly to reality. We find that policies make marginal use of the local height map for perception, showing no indications of predictive planning. However, the strong transfer capabilities entail that further development concerning perception and performance can be largely confined to simulation.</p></div>","PeriodicalId":49592,"journal":{"name":"Robotics and Autonomous Systems","volume":"179 ","pages":"Article 104731"},"PeriodicalIF":5.2000,"publicationDate":"2024-06-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0921889024001155/pdfft?md5=e7bbe412bd07a5f03c52e1e36921e3d4&pid=1-s2.0-S0921889024001155-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Sim-to-real transfer of active suspension control using deep reinforcement learning\",\"authors\":\"Viktor Wiberg , Erik Wallin , Arvid Fälldin , Tobias Semberg , Morgan Rossander , Eddie Wadbro , Martin Servin\",\"doi\":\"10.1016/j.robot.2024.104731\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>We explore sim-to-real transfer of deep reinforcement learning controllers for a heavy vehicle with active suspensions designed for traversing rough terrain. While related research primarily focuses on lightweight robots with electric motors and fast actuation, this study uses a forestry vehicle with a complex hydraulic driveline and slow actuation. We simulate the vehicle using multibody dynamics and apply system identification to find an appropriate set of simulation parameters. We then train policies in simulation using various techniques to mitigate the sim-to-real gap, including domain randomization, action delays, and a reward penalty to encourage smooth control. In reality, the policies trained with action delays and a penalty for erratic actions perform nearly at the same level as in simulation. In experiments on level ground, the motion trajectories closely overlap when turning to either side, as well as in a route tracking scenario. When faced with a ramp that requires active use of the suspensions, the simulated and real motions are in close alignment. This shows that the actuator model together with system identification yields a sufficiently accurate model of the actuators. We observe that policies trained without the additional action penalty exhibit fast switching or bang–bang control. These present smooth motions and high performance in simulation but transfer poorly to reality. We find that policies make marginal use of the local height map for perception, showing no indications of predictive planning. However, the strong transfer capabilities entail that further development concerning perception and performance can be largely confined to simulation.</p></div>\",\"PeriodicalId\":49592,\"journal\":{\"name\":\"Robotics and Autonomous Systems\",\"volume\":\"179 \",\"pages\":\"Article 104731\"},\"PeriodicalIF\":5.2000,\"publicationDate\":\"2024-06-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S0921889024001155/pdfft?md5=e7bbe412bd07a5f03c52e1e36921e3d4&pid=1-s2.0-S0921889024001155-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Robotics and Autonomous Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0921889024001155\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"AUTOMATION & CONTROL SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Robotics and Autonomous Systems","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0921889024001155","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
Sim-to-real transfer of active suspension control using deep reinforcement learning
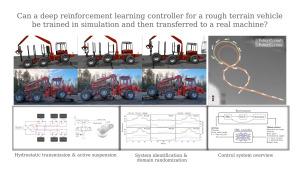
We explore sim-to-real transfer of deep reinforcement learning controllers for a heavy vehicle with active suspensions designed for traversing rough terrain. While related research primarily focuses on lightweight robots with electric motors and fast actuation, this study uses a forestry vehicle with a complex hydraulic driveline and slow actuation. We simulate the vehicle using multibody dynamics and apply system identification to find an appropriate set of simulation parameters. We then train policies in simulation using various techniques to mitigate the sim-to-real gap, including domain randomization, action delays, and a reward penalty to encourage smooth control. In reality, the policies trained with action delays and a penalty for erratic actions perform nearly at the same level as in simulation. In experiments on level ground, the motion trajectories closely overlap when turning to either side, as well as in a route tracking scenario. When faced with a ramp that requires active use of the suspensions, the simulated and real motions are in close alignment. This shows that the actuator model together with system identification yields a sufficiently accurate model of the actuators. We observe that policies trained without the additional action penalty exhibit fast switching or bang–bang control. These present smooth motions and high performance in simulation but transfer poorly to reality. We find that policies make marginal use of the local height map for perception, showing no indications of predictive planning. However, the strong transfer capabilities entail that further development concerning perception and performance can be largely confined to simulation.
期刊介绍:
Robotics and Autonomous Systems will carry articles describing fundamental developments in the field of robotics, with special emphasis on autonomous systems. An important goal of this journal is to extend the state of the art in both symbolic and sensory based robot control and learning in the context of autonomous systems.
Robotics and Autonomous Systems will carry articles on the theoretical, computational and experimental aspects of autonomous systems, or modules of such systems.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


