Chiara Carlier, Julian D Karch, Peter Kuppens, Eva Ceulemans
{"title":"比较用于评估二人组特征相似性的方法。","authors":"Chiara Carlier, Julian D Karch, Peter Kuppens, Eva Ceulemans","doi":"10.5334/pb.1297","DOIUrl":null,"url":null,"abstract":"<p><p>Profile similarity measures are used to quantify the similarity of two sets of ratings on multiple variables. Yet, it remains unclear how different measures are distinct or overlap and what type of information they precisely convey, making it unclear what measures are best applied under varying circumstances. With this study, we aim to provide clarity with respect to how existing measures interrelate and provide recommendations for their use by comparing a wide range of profile similarity measures. We have taken four steps. First, we reviewed 88 similarity measures by applying them to multiple cross-sectional and intensive longitudinal data sets on emotional experience and retained 43 useful profile similarity measures after eliminating duplicates, complements, or measures that were unsuitable for the intended purpose. Second, we have clustered these 43 measures into similarly behaving groups, and found three general clusters: one cluster with difference measures, one cluster with product measures that could be split into four more nuanced groups and one miscellaneous cluster that could be split into two more nuanced groups. Third, we have interpreted what unifies these groups and their subgroups and what information they convey based on theory and formulas. Last, based on our findings, we discuss recommendations with respect to the choice of measure, propose to avoid using the Pearson correlation, and suggest to center profile items when stereotypical patterns threaten to confound the computation of similarity.</p>","PeriodicalId":46662,"journal":{"name":"Psychologica Belgica","volume":"64 1","pages":"72-84"},"PeriodicalIF":2.6000,"publicationDate":"2024-06-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11212783/pdf/","citationCount":"0","resultStr":"{\"title\":\"A Comparison of Measures for Assessing Profile Similarity in Dyads.\",\"authors\":\"Chiara Carlier, Julian D Karch, Peter Kuppens, Eva Ceulemans\",\"doi\":\"10.5334/pb.1297\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Profile similarity measures are used to quantify the similarity of two sets of ratings on multiple variables. Yet, it remains unclear how different measures are distinct or overlap and what type of information they precisely convey, making it unclear what measures are best applied under varying circumstances. With this study, we aim to provide clarity with respect to how existing measures interrelate and provide recommendations for their use by comparing a wide range of profile similarity measures. We have taken four steps. First, we reviewed 88 similarity measures by applying them to multiple cross-sectional and intensive longitudinal data sets on emotional experience and retained 43 useful profile similarity measures after eliminating duplicates, complements, or measures that were unsuitable for the intended purpose. Second, we have clustered these 43 measures into similarly behaving groups, and found three general clusters: one cluster with difference measures, one cluster with product measures that could be split into four more nuanced groups and one miscellaneous cluster that could be split into two more nuanced groups. Third, we have interpreted what unifies these groups and their subgroups and what information they convey based on theory and formulas. Last, based on our findings, we discuss recommendations with respect to the choice of measure, propose to avoid using the Pearson correlation, and suggest to center profile items when stereotypical patterns threaten to confound the computation of similarity.</p>\",\"PeriodicalId\":46662,\"journal\":{\"name\":\"Psychologica Belgica\",\"volume\":\"64 1\",\"pages\":\"72-84\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2024-06-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11212783/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Psychologica Belgica\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://doi.org/10.5334/pb.1297\",\"RegionNum\":4,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"PSYCHOLOGY, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Psychologica Belgica","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.5334/pb.1297","RegionNum":4,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"PSYCHOLOGY, MULTIDISCIPLINARY","Score":null,"Total":0}
A Comparison of Measures for Assessing Profile Similarity in Dyads.
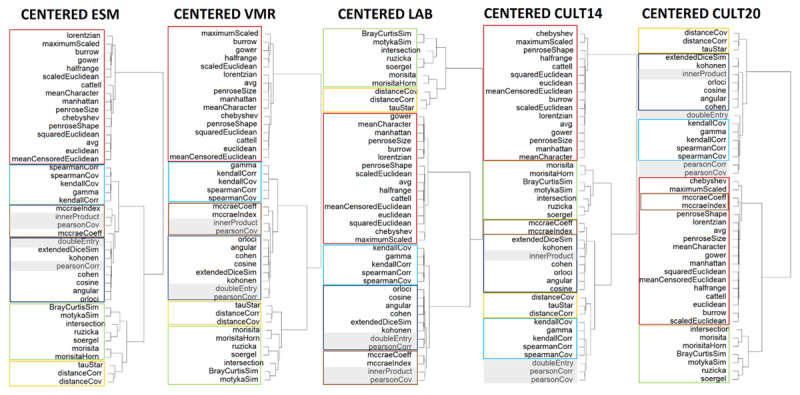
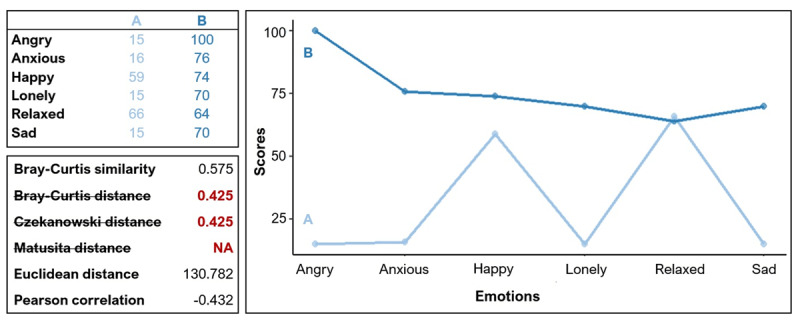
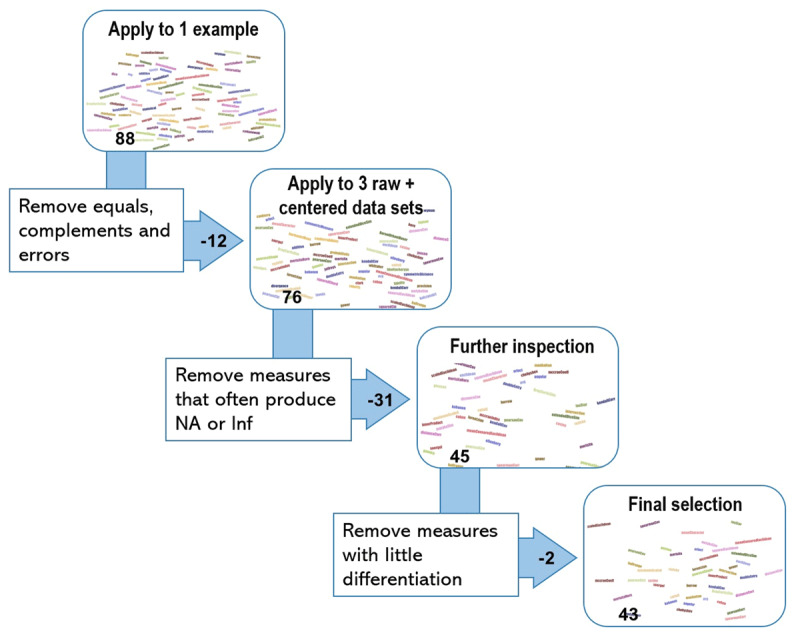
Profile similarity measures are used to quantify the similarity of two sets of ratings on multiple variables. Yet, it remains unclear how different measures are distinct or overlap and what type of information they precisely convey, making it unclear what measures are best applied under varying circumstances. With this study, we aim to provide clarity with respect to how existing measures interrelate and provide recommendations for their use by comparing a wide range of profile similarity measures. We have taken four steps. First, we reviewed 88 similarity measures by applying them to multiple cross-sectional and intensive longitudinal data sets on emotional experience and retained 43 useful profile similarity measures after eliminating duplicates, complements, or measures that were unsuitable for the intended purpose. Second, we have clustered these 43 measures into similarly behaving groups, and found three general clusters: one cluster with difference measures, one cluster with product measures that could be split into four more nuanced groups and one miscellaneous cluster that could be split into two more nuanced groups. Third, we have interpreted what unifies these groups and their subgroups and what information they convey based on theory and formulas. Last, based on our findings, we discuss recommendations with respect to the choice of measure, propose to avoid using the Pearson correlation, and suggest to center profile items when stereotypical patterns threaten to confound the computation of similarity.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


