{"title":"POTLoc:用于点监督时间动作定位的伪标签定向变换器","authors":"Elahe Vahdani, Yingli Tian","doi":"10.1016/j.cviu.2024.104044","DOIUrl":null,"url":null,"abstract":"<div><p>This paper tackles the challenge of point-supervised temporal action detection, wherein only a single frame is annotated for each action instance in the training set. Most of the current methods, hindered by the sparse nature of annotated points, struggle to effectively represent the continuous structure of actions or the inherent temporal and semantic dependencies within action instances. Consequently, these methods frequently learn merely the most distinctive segments of actions, leading to the creation of incomplete action proposals. This paper proposes POTLoc, a <strong>P</strong>seudo-label <strong>O</strong>riented <strong>T</strong>ransformer for weakly-supervised Action <strong>Loc</strong>alization utilizing only point-level annotation. POTLoc is designed to identify and track continuous action structures via a self-training strategy. The base model begins by generating action proposals solely with point-level supervision. These proposals undergo refinement and regression to enhance the precision of the estimated action boundaries, which subsequently results in the production of ‘pseudo-labels’ to serve as supplementary supervisory signals. The architecture of the model integrates a transformer with a temporal feature pyramid to capture video snippet dependencies and model actions of varying duration. The pseudo-labels, providing information about the coarse locations and boundaries of actions, assist in guiding the transformer for enhanced learning of action dynamics. POTLoc outperforms the state-of-the-art point-supervised methods on THUMOS’14 and ActivityNet-v1.2 datasets.</p></div>","PeriodicalId":50633,"journal":{"name":"Computer Vision and Image Understanding","volume":null,"pages":null},"PeriodicalIF":4.3000,"publicationDate":"2024-05-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"POTLoc: Pseudo-label Oriented Transformer for point-supervised temporal Action Localization\",\"authors\":\"Elahe Vahdani, Yingli Tian\",\"doi\":\"10.1016/j.cviu.2024.104044\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>This paper tackles the challenge of point-supervised temporal action detection, wherein only a single frame is annotated for each action instance in the training set. Most of the current methods, hindered by the sparse nature of annotated points, struggle to effectively represent the continuous structure of actions or the inherent temporal and semantic dependencies within action instances. Consequently, these methods frequently learn merely the most distinctive segments of actions, leading to the creation of incomplete action proposals. This paper proposes POTLoc, a <strong>P</strong>seudo-label <strong>O</strong>riented <strong>T</strong>ransformer for weakly-supervised Action <strong>Loc</strong>alization utilizing only point-level annotation. POTLoc is designed to identify and track continuous action structures via a self-training strategy. The base model begins by generating action proposals solely with point-level supervision. These proposals undergo refinement and regression to enhance the precision of the estimated action boundaries, which subsequently results in the production of ‘pseudo-labels’ to serve as supplementary supervisory signals. The architecture of the model integrates a transformer with a temporal feature pyramid to capture video snippet dependencies and model actions of varying duration. The pseudo-labels, providing information about the coarse locations and boundaries of actions, assist in guiding the transformer for enhanced learning of action dynamics. POTLoc outperforms the state-of-the-art point-supervised methods on THUMOS’14 and ActivityNet-v1.2 datasets.</p></div>\",\"PeriodicalId\":50633,\"journal\":{\"name\":\"Computer Vision and Image Understanding\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2024-05-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer Vision and Image Understanding\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1077314224001255\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Vision and Image Understanding","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1077314224001255","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
POTLoc: Pseudo-label Oriented Transformer for point-supervised temporal Action Localization
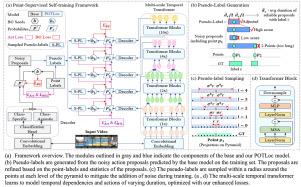
This paper tackles the challenge of point-supervised temporal action detection, wherein only a single frame is annotated for each action instance in the training set. Most of the current methods, hindered by the sparse nature of annotated points, struggle to effectively represent the continuous structure of actions or the inherent temporal and semantic dependencies within action instances. Consequently, these methods frequently learn merely the most distinctive segments of actions, leading to the creation of incomplete action proposals. This paper proposes POTLoc, a Pseudo-label Oriented Transformer for weakly-supervised Action Localization utilizing only point-level annotation. POTLoc is designed to identify and track continuous action structures via a self-training strategy. The base model begins by generating action proposals solely with point-level supervision. These proposals undergo refinement and regression to enhance the precision of the estimated action boundaries, which subsequently results in the production of ‘pseudo-labels’ to serve as supplementary supervisory signals. The architecture of the model integrates a transformer with a temporal feature pyramid to capture video snippet dependencies and model actions of varying duration. The pseudo-labels, providing information about the coarse locations and boundaries of actions, assist in guiding the transformer for enhanced learning of action dynamics. POTLoc outperforms the state-of-the-art point-supervised methods on THUMOS’14 and ActivityNet-v1.2 datasets.
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


