{"title":"针对潜在特征的单幅图像超分辨率重建","authors":"Xin Wang, Jing-Ke Yan, Jing-Ye Cai, Jian-Hua Deng, Qin Qin, Yao Cheng","doi":"10.1007/s41095-023-0387-8","DOIUrl":null,"url":null,"abstract":"<p>Single-image super-resolution (SISR) typically focuses on restoring various degraded low-resolution (LR) images to a single high-resolution (HR) image. However, during SISR tasks, it is often challenging for models to simultaneously maintain high quality and rapid sampling while preserving diversity in details and texture features. This challenge can lead to issues such as model collapse, lack of rich details and texture features in the reconstructed HR images, and excessive time consumption for model sampling. To address these problems, this paper proposes a Latent Feature-oriented Diffusion Probability Model (LDDPM). First, we designed a conditional encoder capable of effectively encoding LR images, reducing the solution space for model image reconstruction and thereby improving the quality of the reconstructed images. We then employed a normalized flow and multimodal adversarial training, learning from complex multimodal distributions, to model the denoising distribution. Doing so boosts the generative modeling capabilities within a minimal number of sampling steps. Experimental comparisons of our proposed model with existing SISR methods on mainstream datasets demonstrate that our model reconstructs more realistic HR images and achieves better performance on multiple evaluation metrics, providing a fresh perspective for tackling SISR tasks.</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"39 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-05-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Super-resolution reconstruction of single image for latent features\",\"authors\":\"Xin Wang, Jing-Ke Yan, Jing-Ye Cai, Jian-Hua Deng, Qin Qin, Yao Cheng\",\"doi\":\"10.1007/s41095-023-0387-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Single-image super-resolution (SISR) typically focuses on restoring various degraded low-resolution (LR) images to a single high-resolution (HR) image. However, during SISR tasks, it is often challenging for models to simultaneously maintain high quality and rapid sampling while preserving diversity in details and texture features. This challenge can lead to issues such as model collapse, lack of rich details and texture features in the reconstructed HR images, and excessive time consumption for model sampling. To address these problems, this paper proposes a Latent Feature-oriented Diffusion Probability Model (LDDPM). First, we designed a conditional encoder capable of effectively encoding LR images, reducing the solution space for model image reconstruction and thereby improving the quality of the reconstructed images. We then employed a normalized flow and multimodal adversarial training, learning from complex multimodal distributions, to model the denoising distribution. Doing so boosts the generative modeling capabilities within a minimal number of sampling steps. Experimental comparisons of our proposed model with existing SISR methods on mainstream datasets demonstrate that our model reconstructs more realistic HR images and achieves better performance on multiple evaluation metrics, providing a fresh perspective for tackling SISR tasks.</p>\",\"PeriodicalId\":37301,\"journal\":{\"name\":\"Computational Visual Media\",\"volume\":\"39 1\",\"pages\":\"\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2024-05-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Visual Media\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s41095-023-0387-8\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0387-8","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Super-resolution reconstruction of single image for latent features
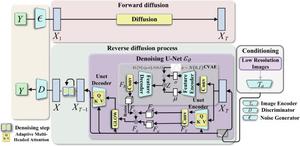
Single-image super-resolution (SISR) typically focuses on restoring various degraded low-resolution (LR) images to a single high-resolution (HR) image. However, during SISR tasks, it is often challenging for models to simultaneously maintain high quality and rapid sampling while preserving diversity in details and texture features. This challenge can lead to issues such as model collapse, lack of rich details and texture features in the reconstructed HR images, and excessive time consumption for model sampling. To address these problems, this paper proposes a Latent Feature-oriented Diffusion Probability Model (LDDPM). First, we designed a conditional encoder capable of effectively encoding LR images, reducing the solution space for model image reconstruction and thereby improving the quality of the reconstructed images. We then employed a normalized flow and multimodal adversarial training, learning from complex multimodal distributions, to model the denoising distribution. Doing so boosts the generative modeling capabilities within a minimal number of sampling steps. Experimental comparisons of our proposed model with existing SISR methods on mainstream datasets demonstrate that our model reconstructs more realistic HR images and achieves better performance on multiple evaluation metrics, providing a fresh perspective for tackling SISR tasks.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


