{"title":"预测心血管疾病的监督学习算法比较分析。","authors":"Yifeng Dou, Jiantao Liu, Wentao Meng, Yingchao Zhang","doi":"10.3233/THC-248021","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>With the advent of artificial intelligence technology, machine learning algorithms have been widely used in the area of disease prediction.</p><p><strong>Objective: </strong>Cardiovascular disease (CVD) seriously jeopardizes human health worldwide, thereby needing the establishment of an effective CVD prediction model that can be of great significance for controlling the risk of the disease and safeguarding the physical and mental health of the population.</p><p><strong>Methods: </strong>Considering the UCI heart disease dataset as an example, initially, a single machine learning prediction model was constructed. Subsequently, six methods such as Pearson, chi-squared, RFE and LightGBM were comprehensively used for the feature screening. On the basis of the base classifiers, Soft Voting fusion and Stacking fusion was carried out to build a prediction model for cardiovascular diseases, in order to realize an early warning and disease intervention for high-risk populations. To address the data imbalance problem, the SMOTE method was adopted to process the data set, and the prediction effect of the model was analyzed using multi-dimensional and multi-indicators.</p><p><strong>Results: </strong>In the single classifier model, the MLP algorithm performed optimally on the preprocessed heart disease dataset. After feature selection, five features eliminated. The ENSEM_SV algorithm that combines the base classifiers to determine the prediction results by soft voting on the results of the classifiers achieved the optimal value on five metrics such as Accuracy, Jaccard_Score, Hamm_Loss, AUC, etc., and the AUC value reached 0.951. The RF, ET, GBDT, and LGB algorithms were employed in the first stage sub-model composed of base classifiers. The AB algorithm was selected as the second stage model, and the ensemble algorithm ENSEM_ST, obtained by Stacking fusion of the two stages exhibited the best performance on 7 indicators such as Accuracy, Sensitivity, F1_Score, Mathew_Corrcoef, etc., and the AUC reached 0.952. Furthermore, a comparison of the algorithms' classification effects based on different training set occupancy was carried out. The results indicated that the prediction performance of both the fusion models was better than the single models, and the overall effect of ENSEM_ST fusion was stronger than the ENSEM_SV fusion.</p><p><strong>Conclusions: </strong>The fusion model established in this study improved the overall classification accuracy and stability of the model to a significant extent. It has a good application value in the predictive analysis of CVD diagnosis, and can provide a valuable reference in the disease diagnosis and intervention strategies.</p>","PeriodicalId":48978,"journal":{"name":"Technology and Health Care","volume":" ","pages":"241-251"},"PeriodicalIF":1.8000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11191474/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparative analysis of supervised learning algorithms for prediction of cardiovascular diseases.\",\"authors\":\"Yifeng Dou, Jiantao Liu, Wentao Meng, Yingchao Zhang\",\"doi\":\"10.3233/THC-248021\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>With the advent of artificial intelligence technology, machine learning algorithms have been widely used in the area of disease prediction.</p><p><strong>Objective: </strong>Cardiovascular disease (CVD) seriously jeopardizes human health worldwide, thereby needing the establishment of an effective CVD prediction model that can be of great significance for controlling the risk of the disease and safeguarding the physical and mental health of the population.</p><p><strong>Methods: </strong>Considering the UCI heart disease dataset as an example, initially, a single machine learning prediction model was constructed. Subsequently, six methods such as Pearson, chi-squared, RFE and LightGBM were comprehensively used for the feature screening. On the basis of the base classifiers, Soft Voting fusion and Stacking fusion was carried out to build a prediction model for cardiovascular diseases, in order to realize an early warning and disease intervention for high-risk populations. To address the data imbalance problem, the SMOTE method was adopted to process the data set, and the prediction effect of the model was analyzed using multi-dimensional and multi-indicators.</p><p><strong>Results: </strong>In the single classifier model, the MLP algorithm performed optimally on the preprocessed heart disease dataset. After feature selection, five features eliminated. The ENSEM_SV algorithm that combines the base classifiers to determine the prediction results by soft voting on the results of the classifiers achieved the optimal value on five metrics such as Accuracy, Jaccard_Score, Hamm_Loss, AUC, etc., and the AUC value reached 0.951. The RF, ET, GBDT, and LGB algorithms were employed in the first stage sub-model composed of base classifiers. The AB algorithm was selected as the second stage model, and the ensemble algorithm ENSEM_ST, obtained by Stacking fusion of the two stages exhibited the best performance on 7 indicators such as Accuracy, Sensitivity, F1_Score, Mathew_Corrcoef, etc., and the AUC reached 0.952. Furthermore, a comparison of the algorithms' classification effects based on different training set occupancy was carried out. The results indicated that the prediction performance of both the fusion models was better than the single models, and the overall effect of ENSEM_ST fusion was stronger than the ENSEM_SV fusion.</p><p><strong>Conclusions: </strong>The fusion model established in this study improved the overall classification accuracy and stability of the model to a significant extent. It has a good application value in the predictive analysis of CVD diagnosis, and can provide a valuable reference in the disease diagnosis and intervention strategies.</p>\",\"PeriodicalId\":48978,\"journal\":{\"name\":\"Technology and Health Care\",\"volume\":\" \",\"pages\":\"241-251\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11191474/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Technology and Health Care\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.3233/THC-248021\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"ENGINEERING, BIOMEDICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Technology and Health Care","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.3233/THC-248021","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
Comparative analysis of supervised learning algorithms for prediction of cardiovascular diseases.
Background: With the advent of artificial intelligence technology, machine learning algorithms have been widely used in the area of disease prediction.
Objective: Cardiovascular disease (CVD) seriously jeopardizes human health worldwide, thereby needing the establishment of an effective CVD prediction model that can be of great significance for controlling the risk of the disease and safeguarding the physical and mental health of the population.
Methods: Considering the UCI heart disease dataset as an example, initially, a single machine learning prediction model was constructed. Subsequently, six methods such as Pearson, chi-squared, RFE and LightGBM were comprehensively used for the feature screening. On the basis of the base classifiers, Soft Voting fusion and Stacking fusion was carried out to build a prediction model for cardiovascular diseases, in order to realize an early warning and disease intervention for high-risk populations. To address the data imbalance problem, the SMOTE method was adopted to process the data set, and the prediction effect of the model was analyzed using multi-dimensional and multi-indicators.
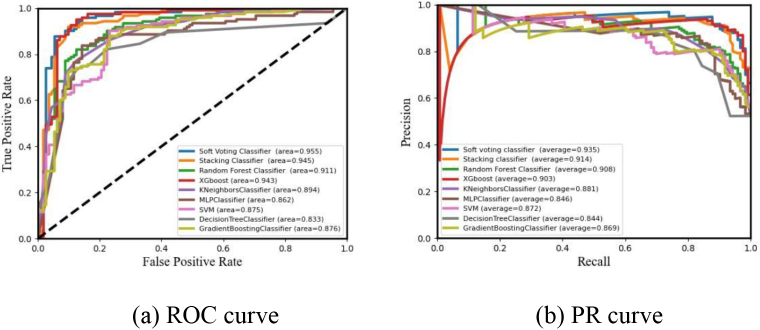
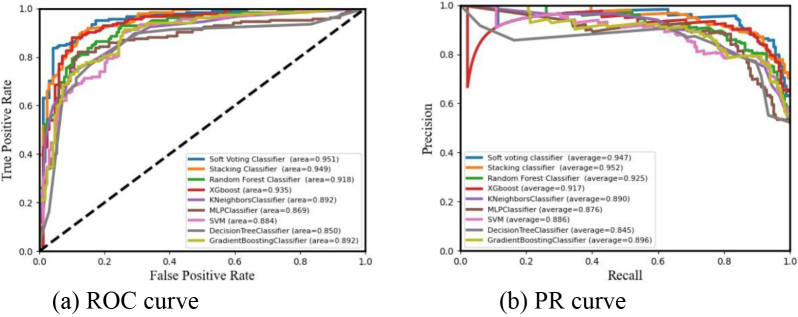
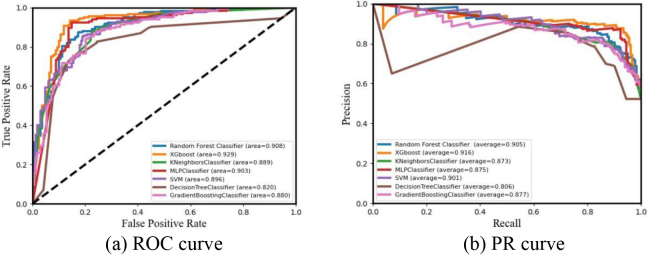
Results: In the single classifier model, the MLP algorithm performed optimally on the preprocessed heart disease dataset. After feature selection, five features eliminated. The ENSEM_SV algorithm that combines the base classifiers to determine the prediction results by soft voting on the results of the classifiers achieved the optimal value on five metrics such as Accuracy, Jaccard_Score, Hamm_Loss, AUC, etc., and the AUC value reached 0.951. The RF, ET, GBDT, and LGB algorithms were employed in the first stage sub-model composed of base classifiers. The AB algorithm was selected as the second stage model, and the ensemble algorithm ENSEM_ST, obtained by Stacking fusion of the two stages exhibited the best performance on 7 indicators such as Accuracy, Sensitivity, F1_Score, Mathew_Corrcoef, etc., and the AUC reached 0.952. Furthermore, a comparison of the algorithms' classification effects based on different training set occupancy was carried out. The results indicated that the prediction performance of both the fusion models was better than the single models, and the overall effect of ENSEM_ST fusion was stronger than the ENSEM_SV fusion.
Conclusions: The fusion model established in this study improved the overall classification accuracy and stability of the model to a significant extent. It has a good application value in the predictive analysis of CVD diagnosis, and can provide a valuable reference in the disease diagnosis and intervention strategies.
期刊介绍:
Technology and Health Care is intended to serve as a forum for the presentation of original articles and technical notes, observing rigorous scientific standards. Furthermore, upon invitation, reviews, tutorials, discussion papers and minisymposia are featured. The main focus of THC is related to the overlapping areas of engineering and medicine. The following types of contributions are considered:
1.Original articles: New concepts, procedures and devices associated with the use of technology in medical research and clinical practice are presented to a readership with a widespread background in engineering and/or medicine. In particular, the clinical benefit deriving from the application of engineering methods and devices in clinical medicine should be demonstrated. Typically, full length original contributions have a length of 4000 words, thereby taking duly into account figures and tables.
2.Technical Notes and Short Communications: Technical Notes relate to novel technical developments with relevance for clinical medicine. In Short Communications, clinical applications are shortly described. 3.Both Technical Notes and Short Communications typically have a length of 1500 words.
Reviews and Tutorials (upon invitation only): Tutorial and educational articles for persons with a primarily medical background on principles of engineering with particular significance for biomedical applications and vice versa are presented. The Editorial Board is responsible for the selection of topics.
4.Minisymposia (upon invitation only): Under the leadership of a Special Editor, controversial or important issues relating to health care are highlighted and discussed by various authors.
5.Letters to the Editors: Discussions or short statements (not indexed).

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


